







1.背景上下文
一些文章通过一些手段引入背上下文提高了一定的目标检测精度,如:
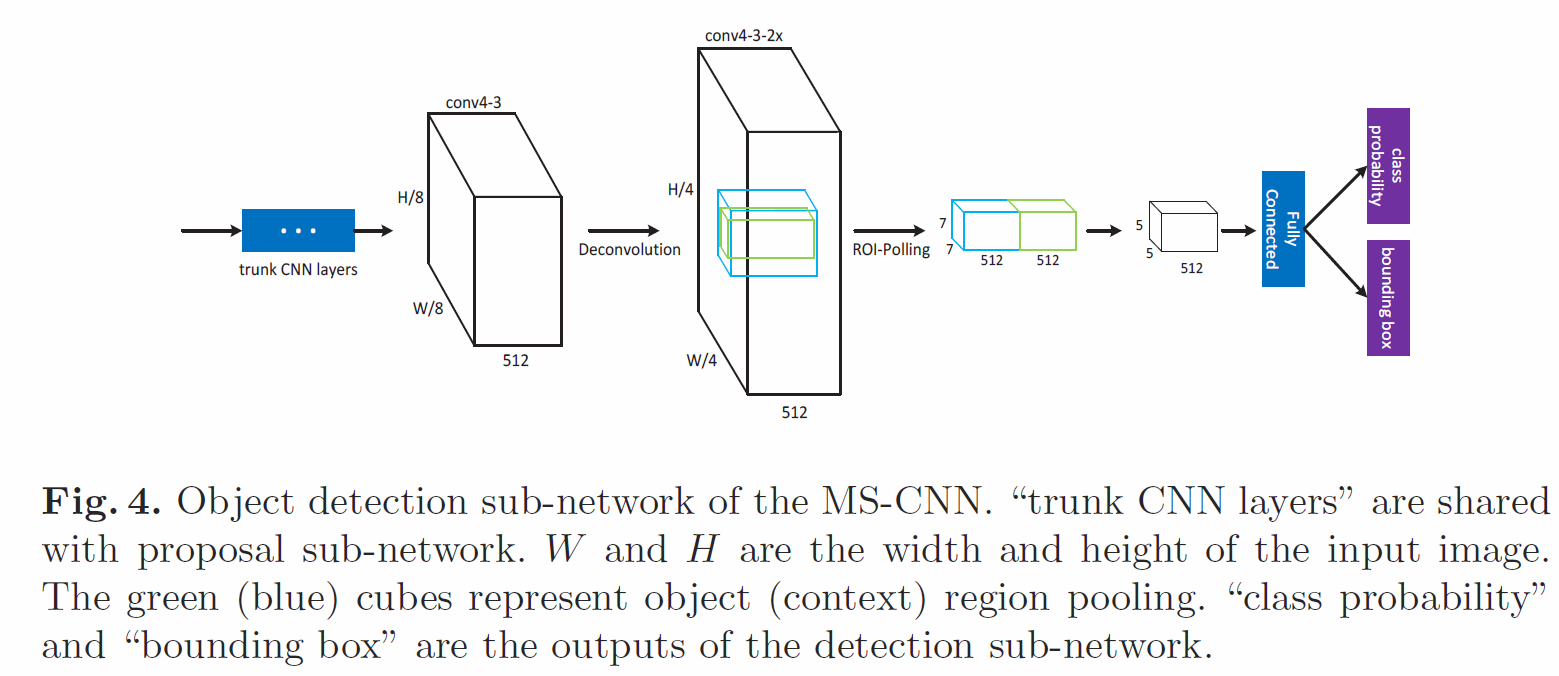
A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection 在检测子网络中添加了上下文池化
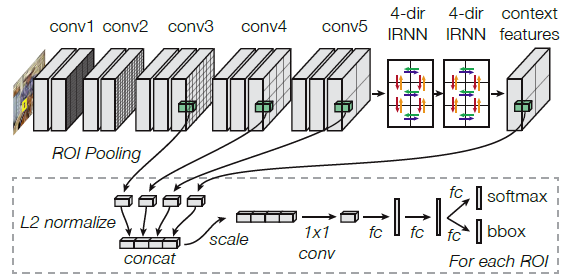
Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks
通过引入2次IRNN层添加上下文信息
2. 时域上下文
基于视频的目标检测,有利用考虑时域信息的3D卷积、时域上利用RNN提取时域上下文、光流信息等,可利用时域上下文做行为识别,目标跟踪,目标定向等。
视频检测是比单张图片检测多了Temporal Context(时域上下文)的信息。不同方法想利用这些Context来解决的问题并不相同。一类方法是关注如何使用这部分信息来加速Video Detection。因为相邻帧之间存在大量冗余,如果可以通过一些廉价的办法来加速不损害性能,在实际应用中还是很有意义的。另一类方法是关注
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1007
1007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









