







Kaldi学习笔记(三)——运行thchs30(清华大学中文语料库):
https://blog.csdn.net/snowdroptulip/article/details/78943748
THCHS-30:一个免费的中文语料库:
https://blog.csdn.net/sut_wj/article/details/70662181
语音识别工具Kaldi :
https://blog.csdn.net/wbgxx333/article/details/17469947
https://blog.csdn.net/amds123/article/details/70313780
http://www.kaldi-asr.org/doc/ 官网
Kaldi中文语音识别公共数据集一共有4个,分别是:
1.aishell: AI SHELL公司开源178小时中文语音语料及基本训练脚本,见kaldi-master/egs/aishell
2.gale_mandarin: 中文新闻广播数据集(LDC2013S08, LDC2013S08)
3.hkust: 中文电话数据集(LDC2005S15, LDC2005T32)
4.thchs30: 清华大学30小时的数据集,可以在 http://www.openslr.org/18/ 下载
Thchs-30 里面共有3个文件,分别是:
data_thchs30.tgz [6.4G] ( speech data and transcripts )
test-noise.tgz [1.9G] ( standard 0db noisy test data )
resource.tgz [24M] ( supplementary resources, incl. lexicon for training data, noise samples )
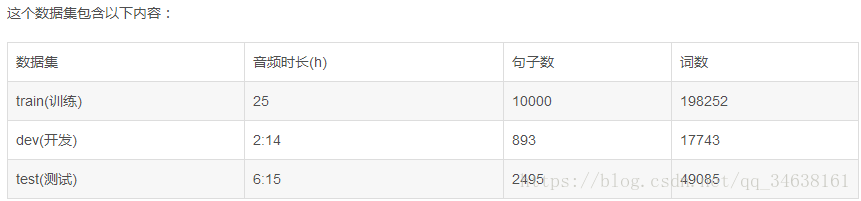
还有训练好的语言模型word.3gram.lm和phone.3gram.lm以及相应的词典lexicon.txt。
其中dev的作用是在某些步骤与train进行交叉验证的,如local/nnet/run_dnn.sh同时用到exp/tri4b_ali和exp/tri4b_ali_cv。训练和测试的目标数据也分为两类:word(词)和phone(音素)
1.local/thchs-30_data_prep.sh主要工作是从$thchs/data_thchs30(下载的数据)三部分分别生成word.txt(词序列),phone.txt(音素序列),text(与word.txt相同),wav.scp(语音),utt2pk(句子与说话人的映射),spk2utt(说话人与句子的映射)
2.#produce MFCC features是提取MFCC特征,分为两步,先通过steps/make_mfcc.sh提取MFCC特征,再通过steps/compute_cmvn_stats.sh计算倒谱均值和方差归一化。
3.#prepare language stuff是构建一个包含训练和解码用到的词的词典。而语言模型已经由王东老师处理好了,如果不打算改语言模型,这段代码也不需要修改。
a)基于词的语言模型包含48k基于三元词的词,从gigaword语料库中随机选择文本信息进行训练得到,训练文本包含772000个句子,总计1800万词,1.15亿汉字
b)基于音素的语言模型包含218个基于三元音的中文声调,从只有200万字的样本训练得到,之所以选择这么小的样本是因为在模型中尽可能少地保留语言信息,可以使得到的性能更直接地反映声学模型的质量。
c)这两个语言模型都是由SRILM工具训练得到。

















 6879
6879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









