







CMU 15-213 CSAPP (Ch1~Ch3)
CMU 15-213 CSAPP (Ch5~Ch7)
CMU 15-213 CSAPP (Ch8)
视频链接
课件链接
课程补充
该课程使用 64位 编译器!
Ch8.Exceptional Control Flow
- 从启动到关机,CPU 只做一件事,读入 并 执行 指令序列,这个 指令序列 就是CPU 控制流
多核CPU,一核一流 - 硬件正在执行的指令序列 是 物理控制流 (Physical Control Flow ,而非软件层面)
- Jumps and Branches 、Call and Return,都是根据 Program State 改变控制流,但一个 功能正常的OS 还要能应对 System State 的改变;
- 计算机系统的所有层次 都存在 ECF ( Exceptional Control Flow )
- Low level mechanisms
- Exceptions,系统事件 ( system event ) 的响应,由 硬件 与 OS kernel 实现;
- Higher level mechanisms
- Process context switch,由硬件 ( Timer ) 与 OS kernel 实现;
- Signal,OS 软件实现;
- Nonlocal jumps,不受 call-return 形式束缚,直接跳转到其他函数内,由C运行时库 ( Runtime library ) 实现;
- Low level mechanisms
8.1 Exceptions
“An exception is a really low level transfer of control to the OS kernel in response to some event”
- 内核 (kernel) 是 OS在内存中常驻的部分 ( momery-resident part );
- System Events:divide by 0,arithmetic overflow,page fault,I/O request completes、ctrl + c …
- 内核处理完 exception 后有三种可能:
- return and reexecute current instruction ( eg. Virtual Memory is based on Page fault );
- return and execute next instruction;
- Abort;
- 控制流的切换 (%rip 或 PC) 由硬件完成,但相应执行哪一段代码由软件 OS Kernel 决定:
- 每个 event 对应唯一一个 中断向量 ( exception number,a.k.a interrupt vector );
- 硬件将 中断向量 作为索引,handler 地址 作为表项,组成 中断向量表 ( exception table );

8.1.1 Asynchronous and Synchronous
Asynchronous Exceptions
- 将 处理器引脚 ( interrupt bin ) 置位 ⇒ OS 收到 外部 event 发生 ⇒ System State 发生变化,触发 exception;
- Handler 处理完 exception 后返回执行 “next instruction”;
- 如 计时器中断 ( Timer Interrupt ),每隔几毫秒,外部计时器芯片触发一次,用于 内核 从 用户程序 夺取控制权;
- 如 外部设备的 I/O 中断 ( I/O Interrupt ),Ctrl + c,网络分组包抵达,磁盘数据抵达…
Synchronous Exceptions
- 处理器 内部 执行指令 ⇒ events 发生 ⇒ 触发的 Exceptions ⇒ 处理完 Exception 后返回执行指令:
- 陷阱 ( Traps )
- 故意引发 ( Intentional )
- 如 system call:用户程序无权直接访问 内核函数,内核数据 等资源,内核提供各种各样的服务接口,允许程序高效的 调用内核功能 或 请求服务;
- 如 断点 ( breakpoint traps );
- 如 特殊指令;
- 错误 ( Faults )
- 意外引发 ( Unintentional ) ,可能 ( possibly ) 恢复 ( recoverable );
- 恢复后可能 重新执行当前指令,也可能终止;
- 如 页错误 ( page faults ),程序引用的地址空间不在内存中,可恢复,恢复后重新执行引发错误的指令;
- 如 保护错误 ( protection faults ),程序访问 未分配 或 非法 的地址空间,不可恢复,终止;
- 如 浮点错误 ( floating point exceptions ),通常可恢复;
- 终止 (Aborts)
- 意外引发 (Unintentional ) ,不可恢复 (unrecoverable ),用户程序直接终止;
- 如 执行非法指令 ( illegal instruction );
- 如 内存的 奇偶校验错误(详见 Rowhammer 技术)( parity error );
- 如 机器检查出错 ( machine check );
- 陷阱 ( Traps )
System Call
- 每个 x86-64 架构的 系统调用 都有唯一的标志ID,详见 Syscall Table,以 Open 为例
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int myopen()
{
return open("./a.txt",O_RDWR);
}
int main(void)
{
int a = myopen();
return 0;
}
man 查找不到某个函数,可能是 CentOS 使用 minimal 安装,man-pages 不全
[Unix]$ yum install -y man-pages
[Unix]$ man 2 open()
...
DESCRIPTION
The open() system call opens the file specified by pathname.
...
[Unix]$
[Unix]$ gcc main.c
[Unix]$ objdump -d a.out
...
0000000000400586 <myopen>:
400586: 55 push %rbp
400587: 48 89 e5 mov %rsp,%rbp
40058a: be 02 00 00 00 mov $0x2,%esi # O_RDWR
40058f: bf 58 06 40 00 mov $0x400658,%edi # Path
400594: b8 00 00 00 00 mov $0x0,%eax
400599: e8 f2 fe ff ff callq 400490 <open@plt>
40059e: 5d pop %rbp
40059f: c3 retq
...
这里第 400594 行,为什么 %eax = 0(open 对应的 syscall number = 2)?
因为 open() ⇒ __open ⇒ syscall,层层封装,这一层还太浅,真正的 syscall 在glibc 里
[Unix]$ whereis libc.so.6
libc.so: /usr/lib64/libc.so /usr/lib64/libc.so.6
[Unix]$
[Unix]$ objdump -d /usr/lib64/libc.so.6 |grep "<__open>:" -A 100
00000000000ed2a0 <__open>:
...
ed2e1: 89 f2 mov %esi,%edx
ed2e3: b8 01 01 00 00 mov $0x101,%eax
ed2e8: 48 89 fe mov %rdi,%rsi
ed2eb: bf 9c ff ff ff mov $0xffffff9c,%edi
ed2f0: 0f 05 syscall
ed2f2: 48 3d 00 f0 ff ff cmp $0xfffffffffffff000,%rax
...
%eax = 0x101
≠
\neq
= syscall number of “open” = 2 ?
系统调用的返回值依旧放 %rax 中:
系统调用结果在 %rax 中,正数 = file descriptor,负数 = 错误码;
Protection Fault
若处理器侦测到保护违例,会停止当前代码的执行,并发出GPF (General protection fault) 中断。
大多数情形下,操作系统会简单地关闭触发GPF的进程,告知用户,并继续执行其它程序。
如果操作系统没能捕获这一错误,比如 GPF中断处理 return 前发生了另一次违例,处理器会发出双重错误(中断向量值8,常见蓝屏原因之一)。
如果再次(三重)违例,则处理器会关闭,其后只会响应复位(按钮)、启动 或 不可屏蔽中断。
- 非法地址访问 (Invalid Memory Reference)
int a[1000];
main()
{
a[5000] = 13;
}
虽然 用户程序 触发的是 page fault,但 内核 会检测到 地址 属于 虚拟内存地址空间 的一个 非法的区域,因此向 用户程序 发送 SIGSEGV 信号,促使用户程序 退出 并打印 “segmentation fault”。

8.2 Processes
传统 定义:An instance of a running program;
Program 存在的形式 可以是:源文件、二进制文件的 .text section,甚至是内存中字节;
Process 则必须是 正在执行中 的 Program;
-
Process 提供了两个 关键 抽象,目的都是制造 每个 Process 独占 硬件资源 的 “错觉”
- Logical Control Flow
- Each program seems to have exclusive use of the CPU;
- Mechanism ( provided by kernel ) called context switch;
- Private address space
- Each program seems to have exclusive use of main memory;
- Mechanism ( provided by kernel ) called virtual memory
- Logical Control Flow
-
Multiprocessing
- 每个处理器 并行 ( concurrency,logical control flow have overlap in time ) run 多个 进程,进程间 共享 硬件资源,OS 负责管理这种 共享
- 进程交错 ( interleaved ) 执行,multitasking;
- Virtual Memory System 负责管理 地址空间;
- 在某一时刻,Timer Exceptions、Traps、或 Faults,OS 获得 系统控制权:
(1) 将 当前进程 的CPU寄存器值 保存到内存中;
(2) 切换 内存 虚拟地址空间;
(3) 将 内存中 下一个待执行进程 最后一次执行后 保存到内存中的值,载入 CPU;
(4) 开始执行;

- 因此 上下文切换 即 虚拟地址空间 的切换 + CPU寄存器值 的交换;
- 现代多核系统,进程数 通常远多于 核数,OS kernel 负责 Core 间的 进程调度;
- 每个处理器 并行 ( concurrency,logical control flow have overlap in time ) run 多个 进程,进程间 共享 硬件资源,OS 负责管理这种 共享
- Context Switching
- 内核 不是单独的进程 (Separate process),而是作为 现有进程的一部分,常驻内存,管理进程;
- 位于高地址空间,作为 Exception 的 handler 被执行,会等待当前进程的最后一个 instruction 执行完;
- 控制流 经过 上下文切换 (context switch) 由一个进程 转移 另一个进程;

- 内核 不是单独的进程 (Separate process),而是作为 现有进程的一部分,常驻内存,管理进程;
8.2.1 Process Control
- 用户代码借助 Syscall 来操控进程 的行为,即进程控制; - 用户进程 调用的 这类系统级函数 ( System-level functions ),大多数 都封装有 syscall; - Linux 系统级函数,发生 Error 时,通常会返回-1,且将 错误码 赋给 ( global variable?) **errno**,来指明错误原因; - syscall 必须检查返回值,否则 容易出 大 问 题 ; - 一些 系统函数 返回值类型是 void,如 free、exit ... ```cpp void unix_error(char *msg) { fprintf(stderr,"%s: %s\n", msg, strerror(errno)); exit(0); }pid_t Fork(void)
{
pid_t pid;
if((pid = fork()) < 0)
unix_error(“Fork error”);
return pid;
}
pid_t getpid(void); //获取当前进程的 pid
pid_t getppid(void); //获取父进程的 pid
- **Processes States**
* **Running**,executing or waiting to be executed;
* **Stopped**,suspended,will not be scheduled until further notice (<a href="#signal">signal</a>);
* **Terminated**,stopped permanently;
+ signal whose default acton is to terminate;
+ <font color=red>return</font> from main(){};
+ <font color=purple>void</font> <font color=blue>exit</font>( <font color=purple>int</font> status ),与其他函数不同,call 但不会 return;
- **Creating Processes**
* <font color=purple>int</font> <font color=blue>fork</font>( <font color=purple>void</font> ) 创建子进程,子进程中返回0,父进程中返回 子进程的 PID(正整数),错误返回 负整数;
* 子进程 地址空间 与 父进程 <font color=red>分开</font> 但 <font color=red>(变量、栈、代码等) 完全一样</font>;
+ 父进程中 文件描述符 作为变量也被复制,父进程能访问的文件,包括 标准IO 等,子进程都能;
* 与 <font color=purple>void</font> <font color=blue>exit</font>( <font color=purple>int</font> status ) 对应,<font color=purple>int</font> <font color=blue>fork</font>( <font color=purple>void</font> ) call 一次 return 两次(子、父进程 各一次);
* fork() 之后 <font color=red>无法预测</font> 先执行子进程 还是 先父进程;
```cpp
int main()
{
pid_t pid;
int x = 1;
pid = fork(); //这里就暂且不用之前封装的 Fork() 了
if (pid == 0)
{
printf("child : x=%d\n", ++x);
exit(0);
}
printf("parent: x=%d\n", --x);
exit(0);
}
[Unix]$ ./fork
parent: x=0
child : x=2
-
Process Graph
- topological sort,用于整理 并行程序间 所有可能的 交错 ( interleavings,也称 partial ordering )
- [ 顶点,vertex ] 语句的执行;
- [ 边,Edges ] 执行顺序 ( 有向线段 );
- 边 使用 变量当前值 标记;
- printf 顶点 使用 输出内容标记;
- Graph 从 没有入边 的顶点 开始,且只能 从左到右,串联的 edges 就是一条 logical flow;

- topological sort,用于整理 并行程序间 所有可能的 交错 ( interleavings,也称 partial ordering )
-
Child Process Reaping
- 子进程终止 ( Terminate ) 后仍会消耗少许系统资源,等待系统的回收 ( reaped );
- 父进程 通过 wait() 或 waitpid() 函数 从 OS tables 中获取 子进程 exit status 或 其他状态信息,之后 kernel 将负责对 子进程 进行回收 ( 删除 );
- int wait( int *child_status ) 函数,暂停 父进程 ( Caller ),返回 终止子进程 的 PID,且在 child_status 非 NULL 时,将 子进程的 exit status 赋值 给 指向内存;
- exit status 取值声明在 <sys/wait.h>
- 已经终止 但 并未消失 的进程,被称为 “僵尸进程” ( zombie );
- 如果父进程 没有回收 子进程 就先 terminates 了, 系统 会安排 整个系统中的第一个进程 init ( pid=1 ) 来回收这个 “孤儿进程” ( orphaned );
- 像 shell 或 server 这种 长期存在的父进程,忘回收会导致 占用大量的 内核空间,内存泄漏;
#include <stdio.h>
#include <unistd.h>
int main(void)
{
if (0 == fork())
{
printf("\nTerminating Child, PID = %d\n", getpid());
_exit(0);
}
else
{
printf("\nRunning Parent, PID = %d\n", getpid());
while (1);
}
return 0;
}
[Unix]$ ./a.out &
[1] 1321880
Running Parent, PID = 1321880
Terminating Child, PID = 1321881
[Unix]$ ps |grep a.out
1321880 pts/3 00:00:03 a.out
1321881 pts/3 00:00:00 a.out <defunct> // “defunct” 表明 僵尸子进程
[Unix]$ kill 1321880 // 杀死父进程后
[1]+ Terminated ./a.out
[Unix]$ ps |grep a.out // 子进程被 init 进程回收
[Unix]$
[Unix]$ man 2 wait
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *wstatus);
pid_t waitpid(pid_t pid, int *wstatus, int options);
WIFEXITED(wstatus)
returns true if the child terminated normally, that is, by calling exit(3) or
_exit(2), or by returning from main().
WEXITSTATUS(wstatus)
returns the exit status of the child. This consists of the least significant 8 bits
of the status argument that the child specified in a call to exit(3) or _exit(2)
or as the argument for a return statement in main(). This macro should be employed
only if WIFEXITED returned true.
WIFSIGNALED(wstatus)
returns true if the child process was terminated by a signal.
WTERMSIG(wstatus)
returns the number of the signal that caused the child process to terminate.
This macro should be employed only if WIFSIGNALED returned true.
WIFSTOPPED(wstatus)
returns true if the child process was stopped by delivery of a signal; this is
possible only if the call was done using WUNTRACED or when the child is being
traced (see ptrace(2)).
WSTOPSIG(wstatus)
returns the number of the signal which caused the child to stop. This macro
should be employed only if WIFSTOPPED returned true.
WIFCONTINUED(wstatus)
(since Linux 2.6.10) returns true if the child process was resumed by delivery
of SIGCONT.
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
#define N (10)
int main(void)
{
pid_t pid[N];
int i, child_status;
for (i = 0; i < N; i++)
if ((pid[i] = fork()) == 0)
{
if(i == (N-1))
{
_exit(-1);
}
else
{
_exit(100+i);
}
}
for (i = 0; i < N; i++)
{
pid_t wpid = wait(&child_status);
if (WIFEXITED(child_status))
printf("Child [%d] pid [%d] terminated with exit status [%d] [%d]\n", i, wpid, WEXITSTATUS(child_status), child_status);
else
printf("Error ! Child pid [%d] terminate abnormally [%d] [%d]\n", wpid, WEXITSTATUS(child_status), child_status);
}
return 0;
}
[Unix]$ ./a.out # 推测 WEXITSTATUS(child_status) = (child_status >> 8)
Child [0] pid [1352653] terminated with exit status [100] [25600]
Child [1] pid [1352654] terminated with exit status [101] [25856] # 856-600 = 256
Child [2] pid [1352655] terminated with exit status [102] [26112]
Child [3] pid [1352656] terminated with exit status [103] [26368]
Child [4] pid [1352659] terminated with exit status [106] [27136]
Child [5] pid [1352660] terminated with exit status [107] [27392]
Child [6] pid [1352661] terminated with exit status [108] [27648]
Child [7] pid [1352662] terminated with exit status [255] [65280] # -1 认作无符号整型 255
Child [8] pid [1352657] terminated with exit status [104] [26624]
Child [9] pid [1352658] terminated with exit status [105] [26880]
- Loading and Running Programs
- int execve ( char *file, char *argv[], char *envp[] ) ;
- 【file】需要在当前进程中运行的 obj文件 或 脚本文件 ( 以 “#!( Interpreter绝对路径 )” 开头 ) 的绝对路径;
- 【argv】入参,如 argv[0] = “$filename” = $0 …
- 【envp】设置环境变量,如 envp[0] = “USER=root” …
- 注意 argv 和 envp 的最后一个元素都必须是 NULL ( 详见 man execve )
- execve 将导致当前进程的 code、data 和 stack 被完全覆写,仅保留 PID,已经被打开的文件,和信号上下文 ( signal context );
- 除非 文件不存在 return -1,或其他错误导致 return,正常执行流程 将不 return 到 Caller 中;

#include <stdio.h>
#include <unistd.h>
int main(void)
{
pid_t pid;
const char *filename = "/bin/ls";
char* const para = "-lt /usr/include";
char* const* argv = ¶ //pointer to const pointer to char
char* const env = "";
char* const* envp = &env;
if ((pid = fork()) == 0)
{ /* Child runs execve */
if (execve(filename, argv, envp) < 0)
{
printf("%s: Command not found.\n", filename);
_exit(1);
}
}
return 0;
}
- 为啥要 拆成 fork() 再 execve() 两步?
主要是 fork 这个功能是必要的,尤其是 Concurrent Server 开发,你只是需要复制得到多个 server 的镜像;同时,通过 fork 进入子进程后,执行execve前,可以对 入参进行设置,比如:屏蔽某些 signal…
8.2.2 shell
- Linux 上只有一个办法创建新的进程,即 fork,系统 boot up 时首先创建 init_1 ( pid = 1 ),其他所有进程都时它的子孙 ( descendant );
- Init 进程创建后,会创建守护进程 ( daemon ),提供长期服务,如 Web Server,登录进程 login shell (为用户提供 命令行界面);
- 使用 pstree 命令可以查看 进程结构 ( hierarchy );
[Unix]$ pstree
systemd─┬─NetworkManager───2*[{NetworkManager}]
├─2*[agetty]
├─atd
├─auditd─┬─sedispatch
│ └─2*[{auditd}]
├─barad_agent─┬─barad_agent
│ └─barad_agent───2*[{barad_agent}]
├─chronyd
├─crond
├─dbus-daemon
├─lsmd
├─mcelog
├─polkitd───5*[{polkitd}]
├─rngd───2*[{rngd}]
├─rsyslogd───2*[{rsyslogd}]
├─secu-tcs-agent
├─sgagent───{sgagent}
├─sshd───sshd───sshd───bash───pstree
├─sssd─┬─sssd_be
│ └─sssd_nss
├─systemd───(sd-pam)
├─systemd-journal
├─systemd-logind
├─systemd-udevd
├─tat_agent───4*[{tat_agent}]
├─tmux: server───3*[bash]
├─tuned───3*[{tuned}]
└─watchdog.sh───sleep
- 其实 shell 与其他 Application Program 无异,代表用户执行动作 ( on behalf of Users )
- bash ( “Bourne-Again” Shell,default Linux shell );
- sh ( Original Unix Shell by Stephen Bourne, AT&T Bell Labs, 1977 );
- csh/tcsh ( BSD Unix C shell );
- shell 本质上 是 一系列 read 和 evaluate
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/wait.h>
#define CMD_LEN (256)
#define ARGV_MAX (3)
int parseLine(char *buf, char **argv)
{
char *p=buf;
for (int i = 0; i < ARGV_MAX; i++)
{
argv[i]=calloc(CMD_LEN,1);
sscanf(p,"%s",argv[i]);
p += strlen(argv[i])+1;
}
if(argv[ARGV_MAX-1][0] == '&')
return 1;
else
return 0;
}
void freeLine(char **argv)
{
for (int i = 0; i < ARGV_MAX; i++)
{
free(argv[i]);
}
return;
}
int builtin_command(char *cmd)
{
if(0 == strcmp(cmd,"ls"))
return 1;
else
return 0;
}
void eval(char *cmd)
{
char *argv[ARGV_MAX];
char buf[CMD_LEN]={'\0'};
int bg;
pid_t pid;
char* const* penv = NULL;
strcpy(buf,cmd);
// parses cmdline into arguments vector
bg = parseLine(buf,argv);
argv[ARGV_MAX-1] = NULL;
// whather a builtin command
if(builtin_command(argv[0]))
{
printf("%s: builtin_command.\n", argv[0]);
freeLine(argv);
return;
}
else
{
if ((pid = fork()) == 0) // create child to run user job
{
if (execve(argv[0], argv, penv) < 0)
{
printf("%s: Command not found.\n", argv[0]);
_exit(0);
}
}
printf("cpid[%d] argv[0] -argv[1]: %s -%s\n",pid,argv[0],argv[1]);
// parent need to determine running in background or foreground
if (!bg) // bg = 0, foreground job, wait for job finishing
{
int status;
if (waitpid(pid, &status, 0) < 0)
{
printf("%s: foreground error ! waitpid status [%d] \n",
cmd, WIFEXITED(status));
}
}
else
{
printf("%s: background start !\n",cmd);
}
}
freeLine(argv);
return;
}
int main(void)
{
char cmd[CMD_LEN] = {'\0'};
while(1)
{
printf("[PID%d_SH]> ",getpid());
fgets(cmd,CMD_LEN,stdin); // read
if(feof(stdin))
{
printf("[%s:%d] terminated manually !\n",cmd,getpid());
_exit(0);
}
eval(cmd); // evaluate cmd
}
return 0;
}
//child.c
#include <stdio.h>
#include <unistd.h>
int main(void)
{
while(1)
{
sleep(5);
printf("Child [%d]\n",getpid());
}
return 0;
}
[Unix]$ gcc myshell.c
[Unix]$ gcc child.c -o child
[Unix]$ ls
a.out child child.c myshell.c
[Unix]$ ./a.out
[PID1729299_SH]> ls
ls: builtin_command.
[PID1729299_SH]> ./child &
cpid[1729339] argv[0] -argv[1]: ./child -&
Child [1729339]
Child [1729339]
# 说明子进程会占用 foreground
- 按照上述逻辑实现的 myshell,在 后台运行的 job子进程 结束后,父进程没有回收子进程,导致 内存泄露,需要 signal “救场”:
- Kernel 负责 通知 myshell 某个子进程运行结束;
- myshell 收到信号 ( signal ) 开始执行 waitpid 回收;
fork 和 vfork
在不需要执行 execve 且需要 阻塞父进程时 可以用 vfork
8.3 Signals
8.3.1 Signals
- A signal is a small message that notifies a process that an event of some type has occured in the system.
- 与 Exception 最大区别是 完全由软件实现;
- 只会由 kernel 发出:
- Kernel 确认到 event 的发生,通过 更新目标进程的上下文状态 ( 位 ) 发送 signal ;
- 进程 系统调用 kill() 请求内核 向其他进程发送信号;
- 信号 类型 为 int,取值范围 1~30;
- 信号 携带的信息 只有id ( 部分取值有特殊含义 ) 和 “它被发出” 这个动作本身;
| ID | Name | Default Action | Corresponding Event |
|---|---|---|---|
| 2 | SIGINT | Terminate | User typed ctrl-c send to every processes in the foreground |
| 8 | SIGFPE | Terminate Mostly Core Dump | Erroneous arithmetic operation. e.g. 除以 0 |
| 9 | SIGKILL | Terminate | Kill program Cannot Override or ignore |
| 11 | SIGSEGV | Terminate | Segmentation violation |
| 14 | SIGALRM | Terminate | Timer signal Set a Timeout |
| 17 | SIGCHLD | Ignore | Kernel sends to Parent When Child stops or terminates |
| 19 | SIGSTOP | USER handler + SIGTSTP | |
| 20 | SIGTSTP | Suspend | Ctrl + Z |
-
Kernel 强制 目标进程 接受信号 并 做出反应
- Ignore;
- Terminate ( 多伴随 core dump );
- Catch signal,即 执行用户的 signal handler ( 类似 exception handler,但 信号的 ECF 始终在用户进程中 );

-
Pending and Blocked Signals
- 发出但未被进程接收 的信号,处于 代办 ( pending ) 状态:
- 任意时刻,同类型 ( id ) 信号 至多 只能存在 一个;
- signal 没有队列,一个进程有一个 id = k 的 “代办 ( pending )” 信号,后续同类信号直接 被丢弃 ( discarded );
- 重复 Ctrl + C 无效的原理 ?
- 进程可以 屏蔽 ( block) 某种信号,即 内核发出 ( deliver ) 但 进程不接收 ( receipt );
- Pending 信号 最多只接收 一次,取走就清空,handler 执行过程中,后续同类型 signal 直接被内核block,直到 handler 处理完 return 回到内核;
- Kernel 将在 每个进程上下文 中维护 pending 和 blocked 位向量 ( bit vector,32 bit int );
- Pending bit vector,k 类信号发出,第 k 位置位;k 类信号被接收,第 k 位清空;
- Blocked bit vector,也称 信号掩码 ( signal mask ),用户 可使用 sigprocmask syscall 置位 、清位 ( 详见 man syscall );
- 发出但未被进程接收 的信号,处于 代办 ( pending ) 状态:
#include <stdio.h> //printf
#include <signal.h> // sig**()
#include <string.h> //strerror()
#include <errno.h> // errno
void mySigHandler(int num)
{
printf("\nRecv SIGINT\n");
return;
}
int main(void)
{
sigset_t Set, *pSet = &Set;
if(0 != sigemptyset(pSet))
{
printf("init error [%d][%s]\n",errno,strerror(errno));
return -1;
}
if(0 != sigaddset(pSet,SIGINT))
{
printf("add error [%d][%s]\n",errno,strerror(errno));
return -1;
}
signal(SIGINT,&mySigHandler);
/* //取消注释,开启 SIGINT 信号屏蔽
if(0 != sigprocmask(SIG_BLOCK,pSet,NULL))
{
printf("sigprocmask [%d][%s]\n",errno,strerror(errno));
return -1;
}
//这里注释,不屏蔽信号 */
while(1);
return 0;
}
[Unix]$ gcc block.c -o blocktest # block.c 有注释,信号屏蔽 关闭
[Unix]$ ./blocktest &
[1] 2171501
[Unix]$ kill -SIGINT 2171501
Recv SIGINT # 可以接收信号
[Unix]$ kill 2171501 # 先 杀掉 未屏蔽信号的 blocktest 进程
[1]+ Terminated ./blocktest
[Unix]$ vim block.c # 取消注释,开启 信号屏蔽
[Unix]$ gcc block.c -o blocktest
[Unix]$ ./blocktest &
[1] 2171763
[Unix]$ kill -SIGINT 2171763 # SIGINT 信号 已经被屏蔽
[Unix]$ ps
PID TTY TIME CMD
2159495 pts/4 00:00:00 bash
2171763 pts/4 00:00:17 blocktest
2171794 pts/4 00:00:00 ps
[Unix]$ kill 2171763
[1]+ Terminated ./blocktest
[Unix]$
8.3.2 Process Groups
- 每个进程 属于 一个进程组 ( Process Group ),可以通过 getpgrp 或 setpgid 等系统调用 获取 或 修改 进程组;fork Child 会继承 Parent 的 groupid,( 上图 Job #1 就通过 setpgid 修改 groupid = 20 );
- Process Group 使得 /bin/kill 可以 同时 向一组进程 发送 signal 成为可能;
#include <stdio.h>
#include <unistd.h>
int main(void)
{
setpgid(0,2208533); // pid = 0 表示当前进程,pgid = 现有group才能生效
if(0 == fork())
{
fprintf(stdout,"Child pid[%d] pgid[%d]\n",getpid(),getpgrp());
}
else
{
printf("\nParent pid[%d] pgid[%d]\n",getpid(),getpgrp());
}
while(1);
return 0;
}
[Unix]$ man setpgid
...
setpgid() sets the PGID of the process specified by pid to pgid. If pid is zero,
then the process ID of the calling process is used. If pgid is zero, then the
PGID of the process specified by pid is made the same as its process ID. If
setpgid() is used to move a process from one process group to another (as is done
by some shells when creating pipelines), both process groups must be part of the
same session. In this case, the pgid specifies an existing process group to be
joined and the session ID of that group must match the session ID of the joining
process.
...
[Unix]$ ./blocktest & # 使用 setpgid 时,group 必须存在,因此使用任意一个进程作为依托
[2] 2208533
[Unix]$ gcc main.c
[Unix]$ ./a.out &
[3] 2208715
[Unix]$
Parent pid[2208715] pgid[2208533]
Child pid[2208716] pgid[2208533]
[Unix]$ ps -Hj
PID PGID SID TTY TIME CMD
2159495 2159495 2159495 pts/4 00:00:00 bash
2208533 2208533 2159495 pts/4 00:01:29 blocktest
2208715 2208533 2159495 pts/4 00:00:54 a.out
2208716 2208533 2159495 pts/4 00:00:54 a.out
2209126 2209126 2159495 pts/4 00:00:00 ps
[Unix]$ kill -SIGKILL 2208533
[Unix]$ # 这里可以看到 kill -SIG PID 只会杀死对应某 个 进程,不会 全组通杀
[2]- Killed ./blocktest
[Unix]$ ps -Hj
PID PGID SID TTY TIME CMD
2159495 2159495 2159495 pts/4 00:00:00 bash
2208715 2208533 2159495 pts/4 00:01:21 a.out
2208716 2208533 2159495 pts/4 00:01:20 a.out
2209273 2209273 2159495 pts/4 00:00:00 ps
[Unix]$ kill -SIGKILL -2208533
[Unix]$
[3]+ Killed ./a.out
[Unix]$ ps -Hj
PID PGID SID TTY TIME CMD
2159495 2159495 2159495 pts/4 00:00:00 bash
2209373 2209373 2159495 pts/4 00:00:00 ps
[Unix]$
- Sending Signals from the Keyboard
- Ctrl + C 请求 Kermel 向 前台进程组 所有进程 发送 SIGINT;
- Ctrl + Z 请求 Kernel 向 前台进程组 所有进程 发送 SIGTSTP;
- SIGTSTP 暂停 ( suspend ) 进程后,使用 kill -SIGCONT 或 fg ( shell 内置命令 ) 恢复运行;
[Unix]$ ./a.out
Parent pid[2284546] pgid[2284546]
Child pid[2284547] pgid[2284546]
^Z # ctrl + z
[1]+ Stopped ./a.out
[Unix]$ fg
./a.out
^C
[Unix]$ ps w
PID TTY STAT TIME COMMAND
...
2166847 pts/6 Ss+ 0:00 -bash
2284862 pts/4 R+ 0:00 ps w
# S-sleeping T-stoped R-running
# s:session leader +:foreground proc group
# see "man ps" for more
- Sending Signals with kill
- 需要注意,子进程收到 SIGINT / SIGKILL 等信号 终止运行 ( Terminated ) 后,若父进程没有 wait 回收,同样会导致 内存泄漏;
#include <unistd.h>
#include <signal.h>
int main(void)
{
kill(2289369,SIGINT); // Child 的 pid
return 0;
}
[Unix]$ gcc killtest.c -o killtest
[Unix]$ ps -Hj
PID PGID SID TTY TIME CMD
2286049 2286049 2286049 pts/4 00:00:00 bash
2289368 2289368 2286049 pts/4 00:03:01 a.out
2289369 2289368 2286049 pts/4 00:03:01 a.out
2290040 2290040 2286049 pts/4 00:00:00 ps
[Unix]$ ./killtest
[Unix]$ ps -Hj
PID PGID SID TTY TIME CMD
2286049 2286049 2286049 pts/4 00:00:00 bash
2289368 2289368 2286049 pts/4 00:03:19 a.out
2289369 2289368 2286049 pts/4 00:03:13 a.out <defunct>
2290073 2290073 2286049 pts/4 00:00:00 ps
8.3.3 Receiving Signals
- ECF,从 Kernel 返回 process 的最后一刻,内核计算 ( pending not blocked signals )
p
n
b
⃗
=
p
e
n
d
i
n
g
⃗
&
∼
b
l
o
c
k
e
d
⃗
\vec{pnb} = \vec{pending}\ \& \sim \vec{blocked}
pnb=pending &∼blocked
- if ( p n b ⃗ \vec{pnb} pnb == 0),没有 待办 信号,control flow 还给 进程 logical flow 的下一条指令;
- if ( p n b ⃗ \vec{pnb} pnb != 0),从最小的 非零信号位 k 开始,强制进程接收信号,接收后 进程触发相应动作 ( handler ),对其他非零信号重复上述流程,直到清空 p n b ⃗ \vec{pnb} pnb,最后将 control flow 还给 进程 logical flow 的下一条指令;
#include <stdio.h>
#include <unistd.h>
#include <signal.h>
void sigint_handler(int signum)
{
while(1)
{
sleep(2);
printf("\nsigint_handler\n");
}
return;
}
void sigusr1_handler(int signum)
{
printf("\nsigusr1\n");
return;
}
int main(void)
{
signal(SIGINT,&sigint_handler);
signal(SIGUSR1,&sigusr1_handler);
while(1);
return 0;
}
[Unix]$ gcc pnb.c -o pnbtest
[Unix]$ ./pnbtest &
[1] 2443177
[Unix]$ kill -SIGINT 2443177
[Unix]$
sigint_handler # 进入 sigint_handler 死循环
sigint_handler
sigint_handler
...
[Unix]$ kill -SIGUSR1 2443177
sigint_handler # 处理完 SIGUSR1 后继续 SIGINT
sigusr1
sigint_handler
...
[Unix]$ kill -9 2443177
[Unix]$
将 sigint_handler 和 sigusr1_handler 改为
#include <stdio.h> #include<time.h> #include <unistd.h> #include <signal.h> void sigint_handler(int signum) { struct timespec tim; clock_gettime(CLOCK_MONOTONIC,&tim); printf("\nsigint_handler [%d]\n",tim.tv_nsec); return; } void sigusr1_handler(int signum) { struct timespec tim; clock_gettime(CLOCK_MONOTONIC,&tim); printf("\nsigusr1_handler [%d]\n",tim.tv_nsec); return; }验证信号接收的顺序,SIGUSR1 id小应该优先于 SIGINT,但 结果相反?
刚开始执行 sigint_handler 就被 sigusr1_handker 打断?[Unix]$ ./a.out & [1] 2477509 [Unix]$ kill -SIGINT 2477509 && kill -SIGUSR1 2477509 sigusr1_handler [191504489] sigint_handler [191589578]
- Installing Signal Handlers
- handler_t *signal ( int signum, handler_t *handler );
- 是 syscall,过程定义为 Installing signal;
- handler = SIG_IGN,忽略 signum 信号;
- handler = SIG_DFL,signum 信号处理函数 恢复默认 action;
- handler = &handler,用户自定义
- Excecuting Handler 过程定义为 Catching 或 Handling signal;
- handler_t *signal ( int signum, handler_t *handler );
- Signal Handlers as Concurrent Flows
- A signal handlers is a separate logical flow ( not process ) that runs concurrently with the main program ( overlap in time );
- 同前,A进程"时间片"内,内核即使向A发送信号,A也不会处理,只有下一轮调度到 A之前,内核 check 进程A的 pending set,才会促使 A receive and handle signal,handler执行结束再短暂进入kernel,( 因此,结合 signal() 函数本身也是syscall,我猜想 control flow 甚至没有经过A再 jump 到 handler,而是 kernel 直接 jump 到 handler 开始执行,执行结束再 jump 到 A 的 main flow ) ;
- handler 在执行完之前不会返回 main flow;
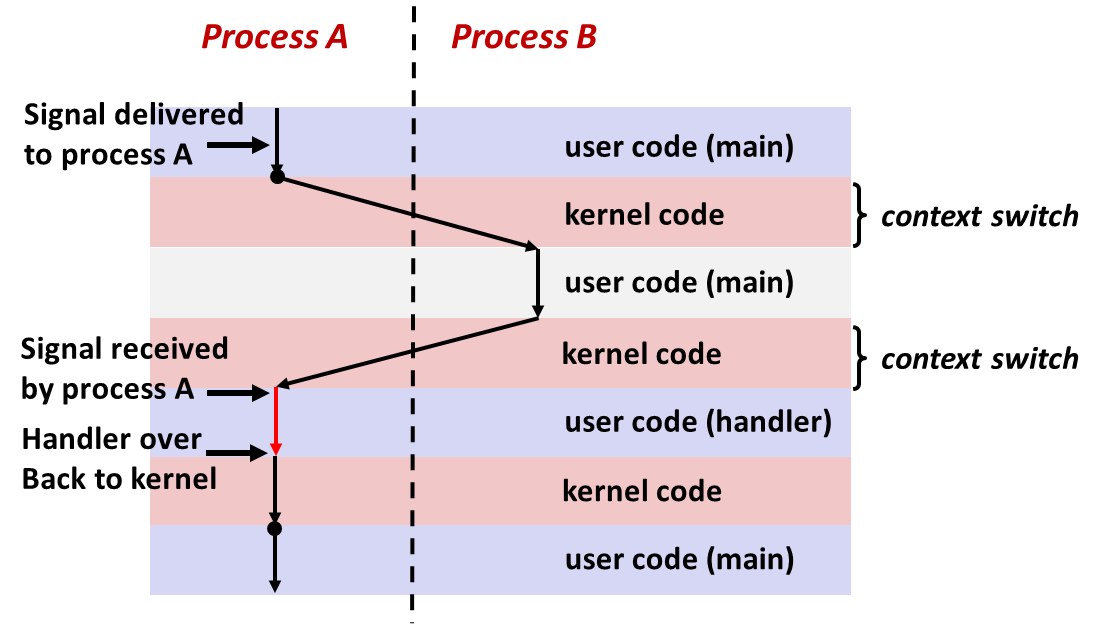
#include <signal.h>
#include <stdio.h>
#include <unistd.h>
void sigusr1_handler(int sig)
{
while(1)
{
sleep(3);
printf("\nsigusr1");
}
return;
}
void sigusr2_handler(int sig)
{
while(1)
{
sleep(3);
printf("\nsigusr2");
}
return;
}
int main(void)
{
signal(SIGUSR1,&sigusr1_handler);
signal(SIGUSR2,&sigusr2_handler);
while(1)
{
sleep(3);
printf("\nmain");
}
return 0;
}
[Unix]$ gcc mt.c -o mttest
[Unix]$ ./mttest &
[1] 2710384
[Unix]$
main
main
main
main
[Unix]$ kill -SIGUSR1 2710384
sigusr1
sigusr1
sigusr1
sigusr1
[Unix]$ kill -SIGUSR2 2710384
sigusr2
sigusr2
sigusr2
sigusr2
...
- Block and Unblocking Signals
- Implicit_block_mechanism:T类信号的 handler 无法被下一个 T类信号 打断;
- 使用 sigprocmask 系统调用,显式开启屏蔽,如同 之前的例程;
8.3.4 Tricky Handler
(1) It’s easy to write unsafe hadnler, mainly because of concurrency
CMU cert Guidelines for writing safe handler:
- Handlers 尽可能的保持简单 ( 比如,读写 Global flag 就 return ) ;
- Handlers 中只使用 async-signal-safe 函数:
- Reentrant,多数情况下没有引用全局变量就算;
- Signal 无法打断的函数;
- POSIX 保证 117 个函数 async-signal-safe:
- _exit()、write ( 唯一输出函数 )、wait、waitpid、sleep、kill …
- 以下常用函数 非 async-signal-safe:
- printf、sprintf、malloc、exit …
- 以 printf 为例,同一时刻只有一个 printf 函数实例能向终端 输出,因此 printf 中必有全局变量 ( 类似 errno ),因此需要 lock,某一时刻 main 中 printf 获取到 lock 后,signal 打断进入 handler,handler 中的 printf 等锁回不到 main,main 也就无法释放锁,形成 Deadlock… ( 目前还没试出来 )
- csapp.c 中提供了 安全版 的 printf() 实现;
- Don’t be pedantic ! 规矩是死的,人是活的 !
- Callee Save,保证所有 handler entry 首先保存 errno ( global variable,系统函数出错时被赋值 ),return 首先还原 errno,从而保证每次执行 handler 后 errno 的一致性;
- Protect accesses to shared data structure by blocking all signals;
- 将 global variables 声明为 volatile,防止编译器将变量值放入寄存器,变量 读写 只在内存上 ( 目前没有想到 演示例程,因为通常 handler 结束后才执行 main,而handler 到 main 之间已经进行过上下文切换,即便没有 vilatile 声明可能也同步到内存了 );
- 将 global flags 声明为 volatile sig_atomic_t,由 编译器 和 系统 保证 flags 的读写是原子的 ( uninterruptible ),多数 Linux 发行版上 sig_atomic_t = int;
(2) It’s easy to get semantics wrong, mainly because of SIGCHLD
还记得之前的 myshell 没有回收子进程的问题么?现在来处理:
//--wait.c-----
#include <unistd.h>
#include <stdio.h>
#include <wait.h>
#include <signal.h>
#include <errno.h>
#define CHILDNUM (5)
int chldcnt = CHILDNUM;
void sigchld_handler(int sig)
{
int olderrno = errno;
pid_t pid = 0;
if((pid = wait(NULL))<0)
printf("\nwait error\n");
printf("\nchild[%d] reap",pid);
chldcnt--;
sleep(1);
errno = olderrno;
return;
}
int main(void)
{
signal(SIGCHLD,&sigchld_handler);
for(int i=0;i < CHILDNUM;i++)
{
if(fork()==0)
{
printf("\nchild[%d]fork [%d] ",i,getpid());
sleep(1);
_exit(0);
}
}
while(chldcnt>0);
return 0;
}
//--loopwait.c-------
#include <unistd.h>
#include <stdio.h>
#include <wait.h>
#include <signal.h>
#include <errno.h>
#define CHILDNUM (5)
int chldcnt = CHILDNUM;
void sigchld_handler(int sig)
{
int olderrno = errno;
pid_t pid = 0;
//wait会导致阻塞在 handler 里,所以 waitpid 更节约资源
while((pid = wait(NULL))>0)
{
chldcnt--;
sleep(1);
printf("\nchild[%d] reap",pid);
}
if(errno =! ECHILD)
{
printf("\nwait error\n");
}
errno = olderrno;
return;
}
int main(void)
{
signal(SIGCHLD,&sigchld_handler);
for(int i=0;i < CHILDNUM;i++)
{
if(fork()==0)
{
printf("\nchild[%d]fork [%d] ",i,getpid());
sleep(1);
_exit(0);
}
}
while(chldcnt>0);
return 0;
}
[Unix]$ gcc wait.c -o wait
[Unix]$ ./wait &
[1] 2830033
[Unix]$
child[2830034] reap
[Unix]$ ps
PID TTY TIME CMD
2702064 pts/10 00:00:00 bash
2830033 pts/10 00:00:04 wait
2830036 pts/10 00:00:00 wait <defunct>
2830037 pts/10 00:00:00 wait <defunct>
2830038 pts/10 00:00:00 wait <defunct>
2830051 pts/10 00:00:00 ps
[Unix]$ gcc loopwait.c -o loopwait
[Unix]$ ./loopwait &
[1] 2832210
child[2832211] reap
child[2832212] reap
child[2832213] reap
child[2832214] reap
child[2832215] reap
[1]+ Done ./loopwait
[Unix]$
(3) Not portable across UNIX OS
- 一些早期的UNIX系统捕捉到信号后,会将 action 还原成默认 action ( Linux 不会 );
- Some interrupted system calls can return with errno == EINTR;
- 【slow syscalls】有些系统调用,内核并不会等待它执行完,而会 调度其他进程;当中断通知内核执行完后,才继续执行系统调用并 return,例如 read;
- 在某些系统上,如果进程在 slow syscall 结束前收到 signal,内核会 abort syscall,并 return errno = EINTR 到进程;因此在这些系统上,用户需要自己管理被 signal 中断的 syscall;
- 某些系统并不会屏蔽 正被处理的同类信号 ( dont’t block signals of the type being handled );
- signal 函数的"替代品",另一个syscall,sigaction,可移植性强,行为可预测;
//csapp.c 中对 signal 函数做了封装
handler_t *Signal(int signum, handler_t *handler)
{
struct sigaction action, old_action;
action.sa_handler = handler;
sigemptyset(&action.sa_mask); //
action.sa_flags = SA_RESTART; // 如果slow syscall 被 signal 打断则尽可能的重启
if(sigaction(signum, &action, &old_action) < 0)
{
unix_error("Signal error");
}
return oldaction.sa_handler;
}
8.3.5 Some Subtle Issues
- Synchronizing Flows to Avoid Races Between Parent and Child
void handler(int sig)
{
int olderrno = errno;
sigset_t mask_all, prev_all;
pid_t pid;
Sigfillset(&mask_all);
while ((pid = waitpid(-1, NULL, 0)) > 0) { /* Reap child */
Sigprocmask(SIG_BLOCK, &mask_all, &prev_all);
deletejob(pid); /* Delete the child from the job list */
Sigprocmask(SIG_SETMASK, &prev_all, NULL);
}
if (errno != ECHILD)
Sio_error("waitpid error");
errno = olderrno;
}
int main(int argc, char **argv)
{
int pid;
sigset_t mask_all, prev_all;
Sigfillset(&mask_all);
Signal(SIGCHLD, handler);
initjobs(); /* Initialize the job list */
while (1) {
if ((pid = Fork()) == 0) { /* Child */
Execve("/bin/date", argv, NULL);
}
Sigprocmask(SIG_BLOCK, &mask_all, &prev_all); /* Parent */
addjob(pid); /* Add the child to the job list */
Sigprocmask(SIG_SETMASK, &prev_all, NULL);
}
exit(0);
}
这是一个简单的 shell;
父进程中,main 维护了 jobs list,意图 在 fork 出 job 子进程后立刻屏蔽所有信号,防止在向 job list 中添加任务的同时,某个子进程运行结束发出 SIGCHILD 信号,导致 handler 并行 ( concurrently ) 操作 job list;
再看 handler,每次 reap 子进程时,屏蔽信号,jobs list 中 job 减 1 ( 清掉子进程对应 pid ),最后开放信号屏蔽开关;
子进程在 fork 出来后,有没有可能,在父进程 main 中 addjob 开始执行前就执行完?
handler 将尝试删除还没有添加到 job list 中的 job,main 中 job 被加入 list 后也永远不会消失…
怎么改? 在 fork 出子进程 之前就屏蔽 SIGCHILD,但子进程会继承父进程的 bit vector set,因此需要在子进程中 解开对 SIGCHILD 的屏蔽;之后与改造前相同,父进程 屏蔽所有信号 ( 这里我觉得其他 handler 如果不操作 jobs list 是否可以不屏蔽所有 bit vector,只屏蔽 SIGCHILD ? ),添加子进程 job 到 jobs list 中,再解开屏蔽;
int main(int argc, char **argv)
{
int pid;
sigset_t mask_all, mask_one, prev_one;
Sigfillset(&mask_all);
Sigemptyset(&mask_one);
Sigaddset(&mask_one, SIGCHLD);
Signal(SIGCHLD, handler);
initjobs(); /* Initialize the job list */
while (1) {
Sigprocmask(SIG_BLOCK, &mask_one, &prev_one); /* Block SIGCHLD */
if ((pid = Fork()) == 0) { /* Child process */
Sigprocmask(SIG_SETMASK, &prev_one, NULL); /* Unblock SIGCHLD */
Execve("/bin/date", argv, NULL);
}
Sigprocmask(SIG_BLOCK, &mask_all, NULL); /* Parent process */
addjob(pid); /* Add the child to the job list */
Sigprocmask(SIG_SETMASK, &prev_one, NULL); /* Unblock SIGCHLD */
}
exit(0);
}
- Explicitly Waiting for Signals
之前 shell 实验里,前台 ( foreground ) 执行命令通过 waitpid 实现等待;
但在实际的 shell 中, SIGCHILD 的 handler 中调用 wait 的功能,效率会高很多;
volatile sig_atomic_t pid;
void sigchild_handler(int s)
{
int olderrno = errno;
pid = waitpid(-1,NULL,0);
errno = olderrno;
}
int main(int argc, char **argv)
{
sigset_t mask, prev;
Signal(SIGCHLD, sigchld_handler);
Signal(SIGINT, sigint_handler);
Sigemptyset(&mask);
Sigaddset(&mask, SIGCHLD);
while (1)
{
Sigprocmask(SIG_BLOCK, &mask, &prev); /* Block SIGCHLD */
if (Fork() == 0) exit(0); /* Child */
/* Parent */
pid = 0;
Sigprocmask(SIG_SETMASK, &prev, NULL); /* Unblock SIGCHLD */
/* Wait for SIGCHLD to be received (wasteful!) */
while (!pid);
}
exit(0);
}
[root@VM-4-10-centos ~]# man waitpid
...
wait() and waitpid()
The wait() system call suspends execution of the calling process
until one of its children terminates. The call wait(&wstatus) is
equivalent to:
waitpid(-1, &wstatus, 0);
The waitpid() system call suspends execution of the calling process
until a child specified by pid argument has changed state. By
default, waitpid() waits only for terminated children, but this
behavior is modifiable via the options argument, as described below.
The value of pid can be:
< -1 meaning wait for any child process whose process group ID is
equal to the absolute value of pid.
-1 meaning wait for any child process.
0 meaning wait for any child process whose process group ID is
equal to that of the calling process.
> 0 meaning wait for the child whose process ID is equal to the
value of pid.
while( !pid ) 这种 自旋操作 非常的浪费资源 !!!
一种解决思路是 pause (),pause 会被其他信号如 SIGINT 唤醒,因此需要 while 循环;
while( !pid ) pause(); // way no.1
问题的关键在于,while( !pid ) 到 pause 之间,可能被 SIGCHILD 信号打断,执行 sigchild_handler 再回到 main 中执行 pause(),等待一个再也不会来的信号,导致死锁;
第二种解决思路是 sleep (),但效率过低,响应过慢;
while( !pid ) nanosleep(100); //way mo.2
最终的解决方法是使用 sigsuspend 函数,函数功能等同于下述动作的原子操作
// sigsuspend equivalent to atomic version of
sigprocmask(SIG_SETMASK, &mask, &pre_mask);
pause();
sigprocmask(SIG_SETMASK, &premask, &NULL);
shell 前台任务的正确实现方法如下:
int main(int argc, char **argv)
{
sigset_t mask, prev;
Signal(SIGCHLD, sigchld_handler);
Signal(SIGINT, sigint_handler);
Sigemptyset(&mask);
Sigaddset(&mask, SIGCHLD);
while (1)
{
Sigprocmask(SIG_BLOCK, &mask, &prev); /* Block SIGCHLD */
if (Fork() == 0) exit(0); /* Child */
/* Wait for SIGCHLD to be received */
pid = 0;
while (!pid) Sigsuspend(&prev);
/* Optionally unblock SIGCHLD */
Sigprocmask(SIG_SETMASK, &prev, NULL);
/* Do some work after receiving SIGCHLD */
printf(".");
}
exit(0);
}















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









