






前言
本题作为王爽老师《汇编语言(第4版)》的压轴题,确实还是有一定难度的。我也是参考了大佬们的解答,以及自己踩了一系列的坑,才给出一个并不算完美的答案。即便如此,这个过程中遇到的问题,也足够写一篇博客,整理经验了。
题目要求
用C语言实现一个简单的printf函数,只要支持"%c"(字符型变量)、"%d"(十进制整型变量)即可。
*在此基础上,笔者额外实现了换行功能,即正确处理格式控制字符串中的'\n'字符。
分析
我们知道,C语言stdio库中的printf函数,是一个不定参数的函数。根据书本前面的分析以及网友们的总结,我们知道,printf函数生成的汇编代码,会将格式控制字符串(即第一个实参)的地址,作为最后入栈的变量。而后,在汇编代码中,printf会根据这个地址,来找到内存中的格式控制字符串,逐个读取字符,并进行如下处理:
- 对于'%'字符,读取它后面一个字符,根据后面一个字符类型('c'/'d'/...),决定当前参数以何种格式输出。
- 对于'\0'字符,printf函数立即退出。
- 对于其他字符,基本上原样输出,但有些字符需要额外的处理——例如,'\n'字符会导致输出从下一行开始。
为了专注核心逻辑(也为了节省宝贵的时间),我们对功能进行了进一步简化,包括:
- 不进行输入合法性检查
- 不设置文本颜色
- 输出的字符串的起始位置总是为12行0列(8086的屏幕共80行25列)
完整代码和运行效果
完整代码:
void my_printf(char *format, ...);
void print_char(char c);
void print_decimal(int decimal);
void print_int_min();
#define BASE (0xb8000000 + 160 * 12) /* 第12行0列的地址 */
#define INT_MIN -32768 /* 16位整型数的最小值,输出时需要特殊处理 */
unsigned int str_index = 0; /* 屏幕上单个字符相对于BASE的偏移位置 */
int main()
{
/*
* 由于输出位置固定,因此连续调用两次my_printf函数后,第二次的输出会覆盖第一次
* 所以每次运行只调用一次my_printf函数,而注释其他的调用语句
*/
my_printf("In DECIMAL, %d - %d = %d.\n", -32767, 1, -32768);
my_printf("In HEX, %dH + %dH = %c%cH.", 90, 11, 'A', '1');
return 0;
}
void my_printf(char *format, ...)
{
char *p = format;
unsigned int param_index = 0; /* format之后的参数在栈中的下标,从0开始 */
while (*p) /* 遍历format,遇到'\0'就退出 */
{
if (*p == '%') /* 遇到'%'字符,则读取下一个字符 */
{
p++;
if (*p == 'c')
{
/*
* 将栈中当前参数(字型,2字节)按字符类型输出
* 对于这个2字节的参数,我们只需要代表字符的那个字节
* 8086是小端机器,因此实际需要输出的字符保存在低位字节
*/
char ch = *(char *)(_BP + 6 + 2 * param_index); /* 获取低位字节,详见后文分析 */
param_index++;
print_char(ch);
}
else if (*p == 'd')
{
/*
* 将栈中当前参数(字型,2字节)按十进制整型输出
* 这2个字节都有意义,它们共同构成一个16位整型数据
*/
int decimal = *(int *)(_BP + 6 + 2 * param_index); /* 见后文分析 */
param_index++;
print_decimal(decimal);
}
p++;
}
/*
* 遇到换行符'\n',则令str_index变为代表下一行起始位置的值
* 注意不要将'\n'拆分为'\\'和'n'两个字符
* 因为'\n'在格式控制字符串format中,本就已经被转义为一个单独的换行符
*/
else if (*p == '\n')
{
str_index += (80 - str_index);
p++;
}
else
{
print_char(*p);
p++;
}
}
}
/* 在相对于BASE偏移量为str_ndex的位置,打印单个字符c */
void print_char(char c)
{
/*
* 重坑提醒:一定不要遗漏far!
* 在16位的8086处理器中,int类型长度为一个字(16位)
* 如果不写far,那么地址会被当做字型(16位)而不是双字型(32位)来处理
* 而BASE = 0xb8000000 + 160 * 12,必须用双字型才能完整表示
* 如果使用默认的字类型,则高位字将会丢失,实际地址将会是(160 * 12 + 2 * index),
* 而不是(0xb8000000 + 160 * 12 + 2 * index)
*/
*(char far *)(BASE + 2 * str_index) = c;
str_index++;
}
/* 在相对于BASE偏移量为index的位置,输出一个整数 */
void print_decimal(int decimal)
{
if (decimal == 0)
{
print_char('0');
}
else
{
/* INT_MIN(-32768 ,16位整型数最小值)没有对应的相反数(16位整型最大值为32767),需单独处理 */
if (decimal == INT_MIN)
{
print_int_min();
}
else if (decimal < 0)
{
print_char('-'); /* 对于负数,先输出一个负号'-' */
decimal = -decimal; /* 将decimal变为相反数(正数),之后进行整除和取余 */
}
if (decimal > 0)
{
/* 排除INT_MIN的情形 */
/* 逐个获取数位,先入栈后出栈 */
int count = 0;
char ch;
while (decimal)
{
int num = decimal % 10;
decimal /= 10;
/* 手动实现汇编push指令 */
_SP -= 2;
*(int *)_SP = num;
count++;
}
while (count)
{
/* 手动实现汇编pop指令 */
ch = *(char *)_SP; /* 获取代表字符的低位字节 */
_SP += 2;
ch += 0x30; /* 将数字变为对应的数字字符 */
print_char(ch);
count--;
}
}
}
}
/*
* 对INT_MIN进行特殊处理
* 在相对于BASE偏移量为str_index的位置,输出"-32768"
*/
void print_int_min()
{
*(char far *)(BASE + 2 * str_index) = '-';
str_index++;
*(char far *)(BASE + 2 * str_index) = '3';
str_index++;
*(char far *)(BASE + 2 * str_index) = '2';
str_index++;
*(char far *)(BASE + 2 * str_index) = '7';
str_index++;
*(char far *)(BASE + 2 * str_index) = '6';
str_index++;
*(char far *)(BASE + 2 * str_index) = '8';
str_index++;
}运行效果(每次运行前须执行cls命令清屏,以便更好地观察输出):
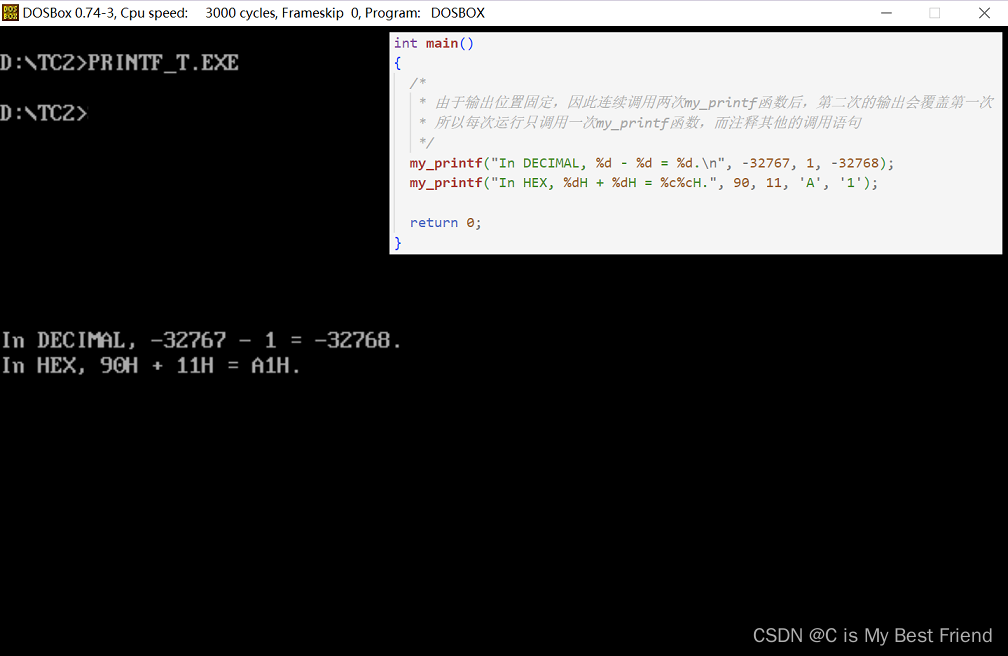
踩坑总结
下面开始细数编程过程中踩过的坑。
1. my_printf的format参数
format是一个用于格式控制的字符串。最初我以为汇编代码会把字符串中的每个字符都依次入栈,于是我想着该如何确定其他参数在栈中的偏移......看了大佬的分析才发现,对于format字符串,和其他参数一样,处理器也只会将其入栈1次,入栈的值是format的起始地址。后面的汇编代码会有JMP指令,跳转到该地址,从而逐个读取format中的每个字符。
2. 执行my_printf函数第一条代码前,栈的状态
我们以main函数中如下调用语句为例说明。
my_printf("In DECIMAL, %d + %d = %d. ", -32767, -1, -32768);在跳转到my_printf之前,main函数会将所有实参自右向左依次入栈,故栈的状态为:
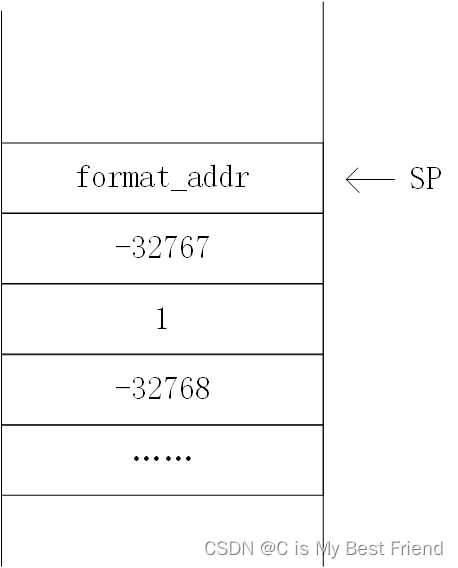
其中,format_addr是一个指向格式控制字符串的指针。原生printf函数的实现也是如此。
现在,程序调用my_printf函数。程序调用在汇编中会被翻译为CALL指令,而CALL指令会将IP入栈。所以刚进入汇编中my_printf对应的子程序时,栈的状态为:

而子程序的前两条汇编代码,就是:
PUSH BP
MOV BP, SP
这是为了用基于BP的偏移量,方便地定位子程序的参数和局部变量。所以执行my_printf函数第一条代码前,栈的状态为:

在8086的栈中,每个元素的长度为1个字(2字节,16位)。现在,我们要想获取format之后的任何一个参数,只需要借助SS和BP即可:
第0个参数(-32767)——SS:[BP + 6]
第1个参数(-1)——SS:[BP + 8]
第2个参数(-32768)——SS:[BP + 10]
第k个参数(k从0开始)——SS:[BP + 6 + 2 * k]
这正是C语言实现不定数量参数的原理。
3. 遍历格式控制字符串format
在原生printf函数的实现中,完成参数入栈和保存现场的准备工作后,程序将会执行JMP指令,跳转到format的起始地址。用汇编指令可表示为:
JMP [BP + 4] ; 等价于JMP [format_addr]
而后,程序将会设置CX等寄存器的值,从而开始遍历字符串;对于每个字符,根据它是普通字符/格式控制字符('%')/转义字符,采用不同的输出方式。
在C语言代码中,我们使用指针遍历字符串,来模拟这个过程,即:
while (*p)
{
/* 处理当前字符 */
p++;
}4. 直接输出普通字符
print_char()函数最为简单,直接输出普通字符。
这个函数也是print_decimal()函数的基础——因为后者最终也需要调用print_char()函数,将代表数字的字符,逐个打印到屏幕上。
/* 在相对于BASE偏移量为str_index的位置,打印单个字符c */
void print_char(char c)
{
/*
* 重坑提醒:一定不要遗漏far!
* 在16位的8086处理器中,int类型长度为一个字(16位)
* 如果不写far,那么地址会被当做字型(16位)而不是双字型(32位)来处理
* 而BASE = 0xb8000000 + 160 * 12,必须用双字型才能完整表示
* 如果使用默认的字类型,则高位字将会丢失,实际地址将会是(160 * 12 + 2 * index),
* 而不是(0xb8000000 + 160 * 12 + 2 * index)
*/
*(char far *)(BASE + 2 * str_index) = c;
str_index++;
}读者很容易注意到函数的第一条语句——它有点复杂,并且对指针的使用方式,与我们平常编程有一些不同。
(char far *)表示将后面的值强制类型转换为字符型指针。
这时读者一定会问:用(char *)不就可以吗?为什么要加一个far?
嗯,这就是本实验中最大的坑之一。
根据我们的宏定义:
#define BASE (0xb8000000 + 160 * 12)为了方便后续表述,我们直接计算出BASE = 0xb8000780。这个值代表了开始打印字符的起始地址。
可以看到,BASE是一个32位整型数值。但是,8086是16位机器,整型(int)的默认长度为16位。如果我们不加far,那么当编译器试图获取(BASE + 2 * str_index)的值时,它会按照默认的整型长度(16位)来获取。由于8086是小端机器,所以被获取到的将会是BASE的低16位,即0x0780!
而加上far以后,编译器就会正确地按照32位整型格式,来获取(BASE + 2 * str_index)的值,而后将其转换为字符型指针。也就是说,这个far关键字,实际上是用来修饰后面要被强制类型转换的值,而不是char * 指针。
最后,在char far *之前还有一个*运算符,表示取该地址(BASE + 2 * str_index)的内容。
所以,这条语句的含义便是:将字符c写入地址(BASE + 2 * str_index)。是不是很简单?
不要忘了,将BP作为偏移时,默认段寄存器为SS。
结合要点2中的分析,这条C语句的意思就是:取栈中当前的参数的低位字节,赋值给字符型变量ch。注意:我们需要的值是一个字符,其取值范围为[0, 255]。由于8086是小端机器,低位字节保存数值的低位,所以我们要取的是低位字节,而不是高位字节。虽然说起来有点绕口,但是读者只要认真学习了本书前面的章节,对此概念一定是十分清楚的。
代码中其他类似语句,也是基于相同的原理,本文不再赘述。
5. 换行
如果当前字符串是'\n',则需要换行。换行的实质是,令str_index的值,代表下一行的起始位置。由于每行是80个字符,因此,只需要让str_index加上(80 - str_index)即可。
else if (*p == '\n')
{
str_index += (80 - str_index);
p++;
}值得注意的是,我们在C语言代码的format中写是'\n',在内存中会被整体视作一个字符。所以,在判断换行符时,直接使用'\n'即可,而不要将其拆分成两个字符'\\'和'\n'来判断,那样是错误的。代码注释中也已经提到了这一点。
6. 按字符类型输出("%c")
if (*p == '%') /* 遇到'%'字符,则读取下一个字符 */
{
p++;
if (*p == 'c')
{
/*
* 将栈中当前参数(字型,2字节)按字符类型输出
* 对于这个2字节的参数,我们只需要代表字符的那个字节
* 8086是小端机器,因此实际需要输出的字符保存在低位字节
*/
char ch = *(char *)(_BP + 6 + 2 * param_index); /* 获取低位字节,详见后文分析 */
param_index++;
print_char(ch);
}
/* ...... */
}param_index是就是第2节中提到的k,代表当前要处理的实参在栈中的顺序。
重点看这条语句:
char ch = *(char *)(_BP + 6 + 2 * param_index);经过前面的分析,读者应该能看懂*(char *)的含义。这里没有加far是因为后面的值本来就是16位整数。
_BP代表BP寄存器。Turbo C 2.0允许程序员在C代码中直接获取寄存器的值。(_BP + 6 + 2 * param_index),正对应了第2节中的分析,表示栈中当前实参的下标。取地址时,由于下标寄存器是_BP,所以默认的段寄存器是SS,也就是从栈中获取相应下标的值。
所以这条语句赋值符右边的含义是,获取栈中当前实参的值(16位整数,2字节)。
这里需要注意的是,我们需要保存到ch当中,是1个char类型值,它只占1个字节。而我们从栈中获取到的数据,占2字节。事实上,生成汇编指令时,对于char型参数,编译器会自动将它的值放在一个字中的低位字节,而高位字节用0填充,而后将这个字型数据入栈。所以,我们只需要获取这个字型数据的低位字节即可;而低位字节就是这个字型数据的起始地址。
将赋值符右边的表达式用汇编指令表述,则会更加直观:
MOV AL, SS:[BP + 6 + 2 * param_index]
***作为对比,如果我们需要获取字型数据的高位字节,则C语言和汇编语言代码分别应当写作:
char ch = *(char *)(_BP + 6 + 2 * param_index + 1); /* C语言代码 */
MOV AL, SS:[BP + 6 + 2 * param_index] ; 汇编语言代码
7. 按十进制整型输出("%d"格式)
总体逻辑很简单:获取栈中当前的参数,逐个截取其数位,并打印在屏幕上。
获取十进制数的各个数位的算法,大家肯定十分熟悉,阅读代码即可。
需要特别提醒的有两点:
7.1 对于INT_MIN(-32768)的特殊处理
在8086中,int型变量的长度为16位,取值范围为[-32768, 32767]。
代码中要输出负数时,通常的流程是:先打印一个负号;而后将负数转换为其相反数(取绝对值);之后反复对10取余和整除,获取数位,并入栈;最后依次出栈。
但是,-32768的相反数32768,超出了int的上限,不能采用如上方法处理。因此,我们必须对其进行特殊处理,依次输出负号和其各个数位。
7.2 借助_SP,在C语言中手动实现汇编中的push和pop指令
由于我们输出数位的顺序,与获取数位的顺序相反,因此,需要使用栈来暂存数位。
我们常常用模板库或是自定义数组,来实现栈的push和pop功能。但在Turbo C 2.0中,由于我们可以直接用C语言操作寄存器,所以可以轻易模拟栈的PUSH和POP指令。比起自定义数组来实现栈,直接操作栈寄存器_SP,无论是从时间、空间效率,还是代码可读性来说,都有巨大的提升。
值得一提的是,这里用到的栈,和我们前面提到的保存参数的栈,是同一个栈。不过,只要操作得当,代码逻辑就不会有任何问题。
/* 手动实现汇编push指令 */
_SP -= 2;
*(int *)_SP = num;/* 手动实现汇编pop指令 */
ch = *(char *)_SP; /* 获取代表字符的低位字节 */
_SP += 2;***这里留一个小彩蛋:可否不用count变量,就能得知print_decimal函数的第二个while循环的终止条件呢?
while (count) /* 思考:如果不使用count,可否得知循环何时结束? */
{
/* 手动实现汇编pop指令 */
ch = *(char *)_SP; /* 获取代表字符的低位字节 */
_SP += 2;
ch += 0x30; /* 将数字变为对应的数字字符 */
print_char(ch);
count--;
}总结
个人觉得这个试验设计得非常好,如果有心从头到尾理清逻辑,将会极大加深对C和汇编关系的理解。正因如此,我才写这篇博客,分享个人的学习收获,与大家交流经验。
读者如有兴趣,也可继续完善我这个半成品程序,使其功能更接近stdio.h文件中的printf函数。
最后,感谢阅读!















 1402
1402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









