







卫星影像的AI分类与识别参赛笔记
标签(空格分隔): 图像分割
文章目录
前言
因为看到卫星影像的AI分类与识别这个比赛和正在研究的卫星遥感影像分割类型很相似,就报名参加了。比赛分A,B榜提交,最终成绩为复赛A榜23/867,B榜12/867,没机会进决赛[-_-]。现在把之前的一些经验做下笔记。
数据集介绍
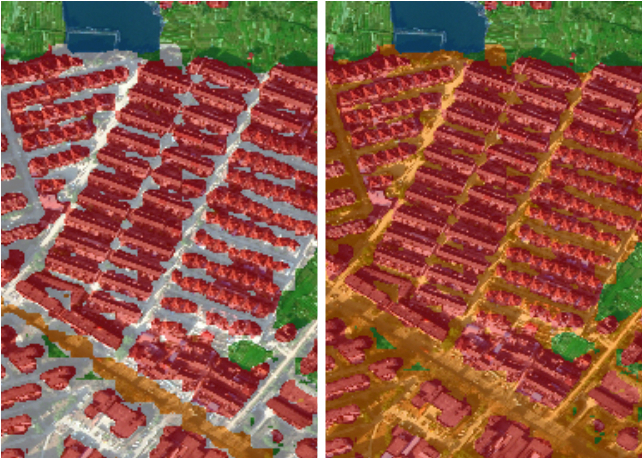
数据来自2015年中国南方某地区的高分辨率无人机遥感影像,分辨率为亚米级,光谱为可见光波段(R,G,B),提供的训练样本分为五类:植被(标记1)、建筑(标记2)、水体(标记3)、道路(标记4)以及其他(标记0),耕地、林地、草地均归为植被类。初赛训练集是2张大的png格式图片,图片大小是79397969,预测集是三张大的png格式图片,图片大小为51905204,复赛训练集增加了3张大的png格式图片,复赛预测集也是三张png图片。相比其他类型比赛的数据,遥感影像可视化较为方便,可以对遥感影像有个整体直观的了解。下面第一张图是初赛训练集,第二张图片是初赛预测原图与预测结果(准确率60%),第三张图片是复赛预测原图和预测结果(准确率91%)。



初赛由于训练集较少,只有2张,预测集有3张,使用神经网络来进行预测效果普遍不好,准确率都在80%以下,参赛队伍中使用传统地物提取方法的队伍可以达到85%左右的准确率,长期稳坐第一的位置,到复赛的时候新增加了3张训练集,数据集增后,神经网络的效果就出来了,使用神经网络的队伍准确率都达到了90%以上,最高的能达到95%,可参考他的gitub,大神的准确率大概在95%左右。
训练集的标注整体质量不错,但也存在少部分标注错误的情况,比如上面第一张图中左上角区域将背景类错误地标注为建筑类;同时由于遥感影像地物类型复杂,存在着预测集中出现训练集中不存在的几种地物导致不能识别的情况,这也是导致初赛中神经网络预测误差较大的原因。
采用分类总精度(Overall Accuracy)来衡量,即统计样本预测值与实际值一致的情况占整个样本的比例(衡量样本被正确标注的数量),即score = 正确数/总数。
这里要仔细读下竞赛的相关要求,比如他们说明,竞赛中其他类(标记为0)的分类精度不算入最后精度评判标准,最后结果只统计植被、道路、建筑、水体四类的分类精度,也就是说预测集中他们标注为第0类的你预测出来随便是哪一类都算你预测正确的,那么提交的时候就可以不需要提交第0类啊,可以直接转为道路类(标记4),因为其他类和道路类最为相似。
解决方案
和imagenet等比赛不一样的是,竞赛所给图片都比较大(比如79397969),受服务器GPU的限制,训练中把原始影像喂给神经网络前,需要切割成小图片,在预测结束后,再将预测的小图片拼接成大的原始影像。这个时候需要确定小图片的大小为多少合适,一开始认为在服务器GPU允许的情况下,小图片的大小应该越大越好,因为这个尺寸越大,被切割的次数就越少,能够降低切割边缘识别不准的错误率。所以刚开始切割成512512的大小,因为使用公司服务器为两块GTX 1080的GPU,在显存允许的情况下最大的batch size为8,但是预测效果并不好,后来切割成小图片的时候,随着batch size增大,发现效果越来越好,原因可参考旷视研究院解读COCO2017物体检测冠军论文,分析认为是训练集中各分类目标所占比例不均衡,有的类别所占比例多,有的类别所占比例小导致。最后参考kaggle比赛中的经验,将切割图片大小设置为80*80,GPU显存允许的最大batch_size为128。切割后图片如下图所示

然后是训练集和验证集划分的问题,一个合理的验证集是非常重要的,是判断哪个模型好坏的依据,但是在训练的时候,验证集中的图片不能参与神经网络的训练,相当于这部分数据不能用了,在数据量小的时候就希望尽可能少分数据给验证集,但模型验证的准确率就会下降,解决措施一般是使用k折交叉验证,具体可参考交叉验证参考,但是在数据量大的时候就没太大必要。复赛中当切割的图片大小为80*80的时候,数据集大概有接近4万张左右,就直接按照5:1的比例来划分训练集和验证集,具体划分的时候每张大图训练集占5/6,验证集占1/6,这样划分是为了保证验证集和训练集中各类别所占比例接近。
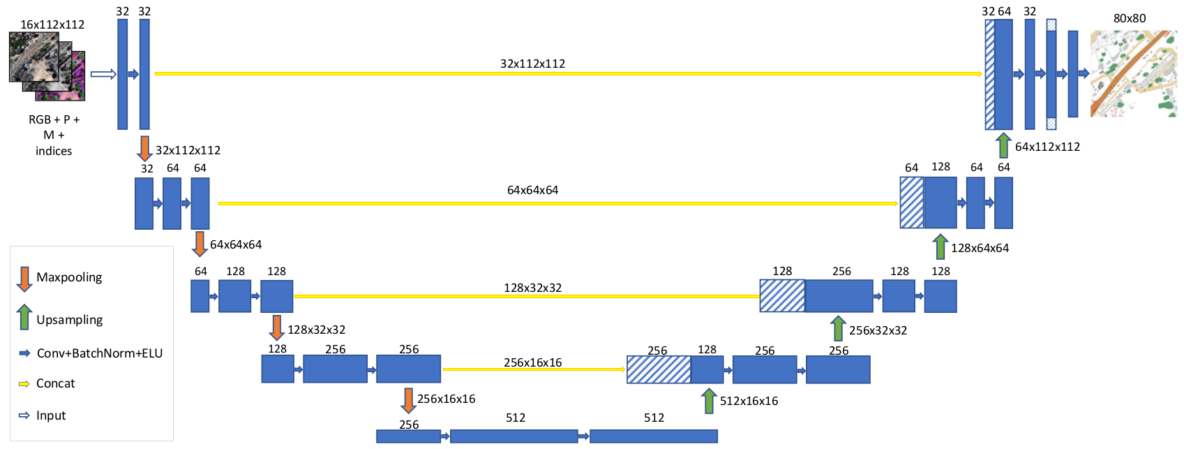
参考了kaggle比赛Dstl Satellite Imagery Feature Detection和Ultrasound Nerve Segmentation的相关经验,在Dstl Satellite Imagery Feature Detection卫星影像分割中,Vladimir Iglovikov和Sergey Mushinskiy 使用UNet网络获得了Public Leaderboard第八, Private Leaderboard第三的成绩,所以主要使用UNet网络来进行分割,比赛中也尝试了SegNet和PSPNet网络,发现UNet的效果还是最稳定的,PSPNet可能我的网络结构有些问题,可参考PSPNet,这位同学在比赛中使用的PSPNet网络,听他qq上说在不加任何trick的时候,大概能达到92%的准确率(他们最终准确率在95%左右,应该是妥妥的前三了)。
同时使用Adam优化器进行训练,一共训练200个epoch,前150个epoch的learning rate为10^-3,后50个epoch的learning rate为10^-4,droupout=0.5,weight decay=510^-4,输入图片大小为8080,batch size=128。
预处理:
竞赛给的数据集是jpg格式,是16位深度,但是只有第四个波段(透明度)是16位深度,其余的RGB值都是8位深度,所以用opencv处理的时候需要注意,需要采用16位深度进行读取数据,再进行一次颜色空间转换。
image=cv2.imread(path,cv2.IMREAD_UNCHANGED)
image=cv2.cvtColor(image, cv2.COLOR_RGBA2RGB)
image=image*256
其他的预处理包括将数据转换到0-1范围,这个是pytorch框架ToTensor()函数自动转的,然后进行归一化操作(各通道减均值除标准差,使用Normalize(mean, std)函数)。
数据增强:
为了避免神经网络在小数据集产生过拟合现象,常用的方法是对已有训练集进行数据增强,丰富图像训练集,提升网络的泛化能力。在卫星遥感影像的处理中,常用的处理方法是随机旋转(random rotate)和水平/垂直翻转(Horizontal/Vertiacal Filp),同时添加了影像的扭曲。下图左上是原图,右上是随机旋转的结果,左下是随机翻转的结果,右下是随机扭曲的结果。

在UNet论文中,作者提出了一种影像重叠策略的方式,来避免大影像切割成小图片的时候边缘预测不准的情况,也就是说在切割成小图片的时候,由于小图片边缘被人为切割,比如大影像中的建筑物刚好被切割到两张小图片中,导致神经网络不能识别小图片边缘部分的建筑物。直接切割,不采用影像重叠策略的效果如下图所示,由于每张小图片边缘部分预测的效果比中间部分差很多,拼接后会产生明显的裂痕感。使用该策略后,效果明显提升,初赛时准确率提升在10%左右。

影像重叠策略是在原始影像内部切割的时候进行重叠,在原始影像边缘部分进行镜像反射外推。如下图所示,原始影像做镜像反射外推padding=16,影像内部切割重叠部分padding=16,大的黄色框和红色框是切割图片时的大小,小的黄色框和红色框是实际有用的区域。

针对测试数据也进行数据增强,然后输入神经网络再进行预测,因为时间来不及就没有做集合,这个小trick在一定程度上也起到了集合预测的效果,准确率提升在1%左右。先将切割完的80*80的小图片进行90°,180°,270°旋转,然后再输入到神经网络进行预测,然后将预测结果进行相应的旋转还原,最后对四个结果取平均。
还有另外一种集合预测的方式,就是先对大的原始卫星影像进行旋转,然后将旋转后的原始影像进行切割成小图片,将预测后的结果拼接起来后再旋转还原取平均值。














 504
504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









