







图片公式转latex、tex、mathtype代码
推荐两种方法:pix2tex包、snip软件
- pix2tex包的好处是免费,缺点是对多行公式反应不太理想且有时候速度不够快,这也可能是本人电脑比较慢的原因,毕竟在官方介绍中反应挺快的。。(点击这里进入官方github库)
- snip软件的好处是响应速度快对多行公式表现也较好,但是需要注册账号且每月只有50个或100个的限度
pix2tex包
pix2tex是python的一个包,安装该包即可将图片转换为latex代码,命令行使用pip安装:
pip install pix2tex[gui]
安装后命令行输入pix2tex_gui打开pix2tex的图形界面,效果如下图(电脑比较慢,见谅):
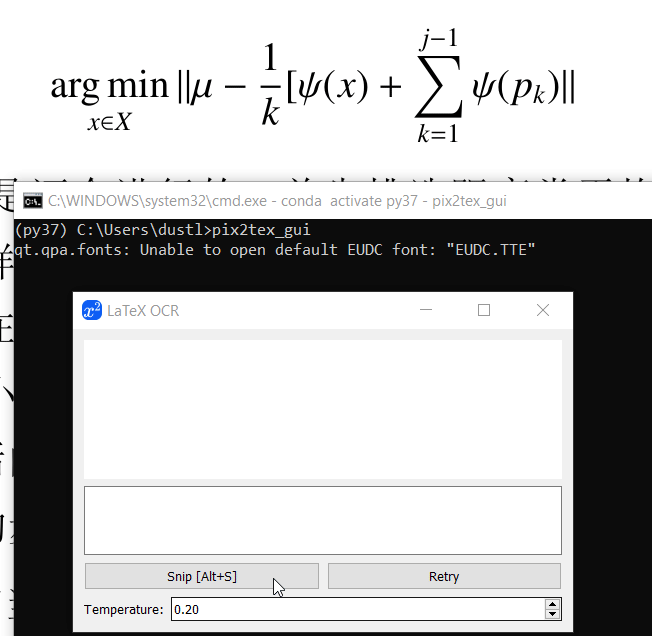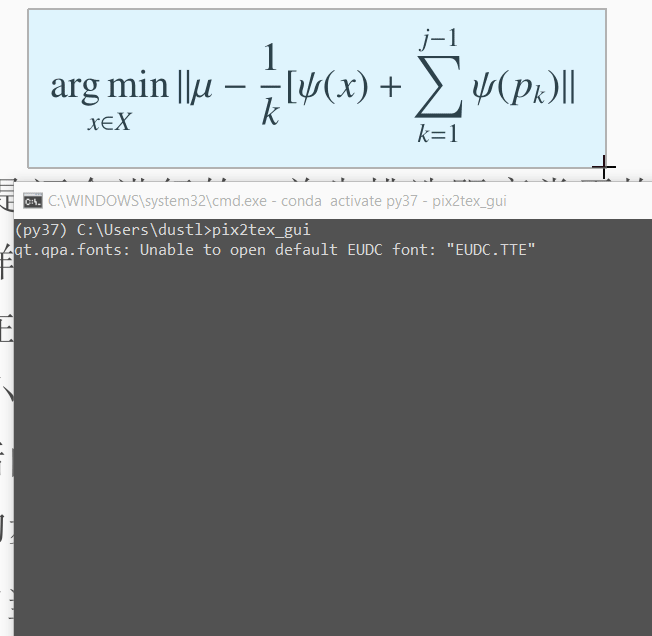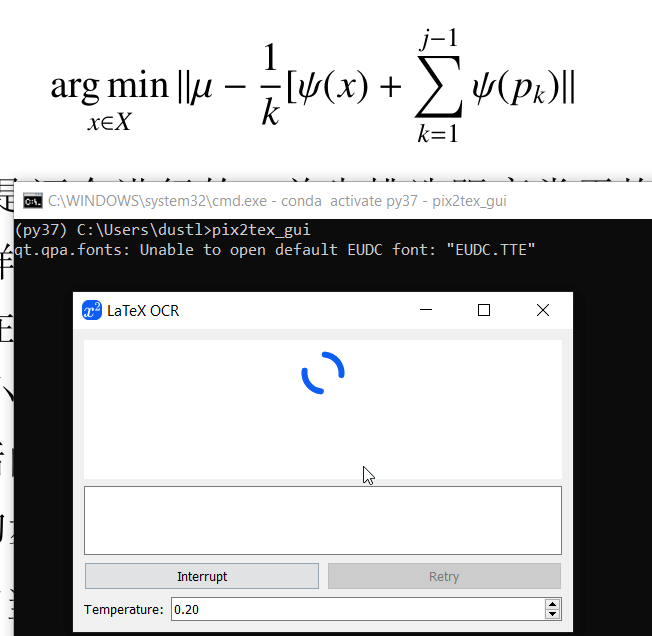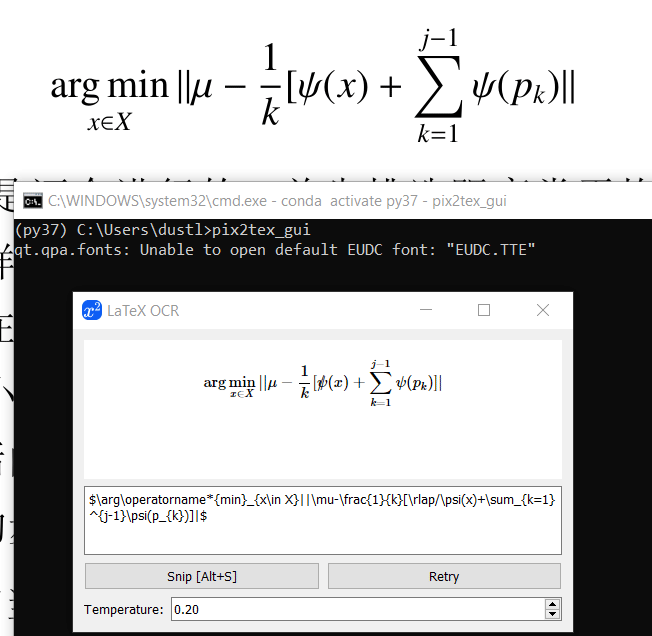
snip工具
使用mathpix snip。注册后下载软件,需要注意每个普通邮箱每月50次转换机会,每个edu邮箱(教育机构邮箱)每月100次机会,如果需要次数多就多注册几个号,相当于免费。snip容易上手,需求量大多注册几个邮箱即可。

















 1354
1354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









