






**
一.KNN算法介绍
**
K最近邻(k-Nearest Neighbor,KNN)分类算法,是机器学习算法之一。
该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
KNN算法用于分类和回归。
**
二.KNN算法原理
**
存在一个样本数据集合,即训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。
输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签。
一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。
最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
注:这里的Python主要针对KNN分类问题
**
三.KNN算法实现流程
**
收集数据:可以使用爬虫进行数据的收集,也可以使用第三方提供的免费或收费的数据。
一般来讲,数据放在txt文本文件中,按照一定的格式进行存储,便于解析及处理。
准备数据:使用Python解析、预处理数据。
分析数据:可以使用很多方法对数据进行分析,例如使用Matplotlib将数据可视化。
测试算法:计算错误率。
使用算法:错误率在可接受范围内,就可以运行k-近邻算法进行分类。
注:在下面的程序中,我们直接创建模拟数据
**
四.主要代码
**
在这里,我们使用Python代码来实现一个KNN算法的二分类问题。
(1)创建模拟数据:
# 生成模拟数据(data generation)# 二分类(0/1)# 随机种子
np.random.seed(271)# 数据集1:点的数量
data_size_1 = 300
# 特征1
x1_1 = np.random.normal(loc=5.0,scale=1.0,size=data_size_1)
# 特征2
x2_1 = np.random.normal(loc=4.0,scale=1.0,size=data_size_1)
# 类别值:0
y_1 = [0 for _ in range(data_size_1)]
# 数据集2:点的数量
data_size_2 = 400
# 特征1
x1_2 = np.random.normal(loc=10.0,scale=2.0,size=data_size_2)
# 特征2
x2_2 = np.random.normal(loc=8.0,scale=2.0,size=data_size_2)
# 类别值:1
y_2 = [1 for _ in range(data_size_2)] # 合并
x1 = np.concatenate((x1_1,x1_2),axis=0)
x2 = np.concatenate((x2_1,x2_2),axis=0)x = np.hstack((x1.reshape(-1,1),x2.reshape(-1,1)))
y = np.concatenate((y_1,y_2),axis=0)
(2)打乱两组模拟数据集,进行分组
# 洗牌后的数据(即打乱所有的数据)dat
a_size_all = data_size_1 + data_size_2# numpy.random.permutation():随机排列序列
# 得到一个0-699的索引数组
shuffled_index = np.random.permutation(data_size_all)
x = x[shuffled_index]
y = y[shuffled_index]
# 切分成两组,一组训练,一组测试
split_index = int(data_size_all * 0.7)
# 训练集0-split_index
x_train = x[:split_index]
y_train = y[:split_index]
# 测试集split_index-(data_size_all-1)
x_test = x[split_index:]
y_test = y[split_index:]
(3)展示数据
# 展示数据visualize data
# 训练集
plt.scatter(x_train[:,0],x_train[:,1],c=y_train,marker='.')
plt.show()
# 测试集
plt.scatter(x_test[:,0],x_test[:,1],c=y_test,marker='.')
plt.show()
(4)归一化
# data preprocessing归一化x_train = (x_train - np.min(x_train,axis=0)) / (np.max(x_train,axis=0) - np.min(x_train,axis=0))x_test = (x_test - np.min(x_test,axis=0)) / (np.max(x_test,axis=0) - np.min(x_test,axis=0))
(5)knn.py
import numpy as npimport operator# 类KNN
class KNN(object):
# 函数1
def __init__(self, k=3):
self.k = k
# 把x,y传进去
def fit(self, x, y):
self.x = x
self.y = y
# 计算任意两点的距离的平方
def _square_distance(self, v1, v2):
return np.sum(np.square(v1-v2))
# 投票机制
def _vote_(self, ys):
# 取ys得唯一值
ys_unique = np.unique(ys)
# 字典
vote_dict = {}
for y in ys:
if y not in vote_dict.keys():
vote_dict[y] = 1
else:
vote_dict[y] += 1
sorted_vote_dict = sorted(vote_dict.items(),key=operator.itemgetter(1), reverse=True)
# 返回最大的值
return sorted_vote_dict[0][0]
def predict(self, x):
y_pred = []
for i in range(len(x)):
# 当前x[i]和所有训练样点的平方距离,保存在dist_arr数组中
dist_arr = [self._square_distance(x[i], self.x[j]) for j in range(len(self.x))]
sorted_index = np.argsort(dist_arr)
# 提取从开始到self.k的索引数组,保存在top_k_index数组中
top_k_index = sorted_index[:self.k]
y_pred.append(self._vote_(ys=self.y[top_k_index]))
return np.array(y_pred)
# 计算精度
def score(self, y_true=None, y_pred=None):
if y_true is None or y_pred is None:
y_pred = self.predict(self.x)
y_true = self.y
score = 0.0
for i in range(len(y_true)):
if y_true[i] == y_pred[i]:
score += 1
# 计算正确率
score /= len(y_true)
return score
(6)创建分类器
# knn classifier# 建立分类器
clf = KNN(k=3)
# 把x_train,y_train传进去
clf.fit(x_train,y_train)
# 得到训练集的精度
score_train = clf.score()
# 保留三位小数输出
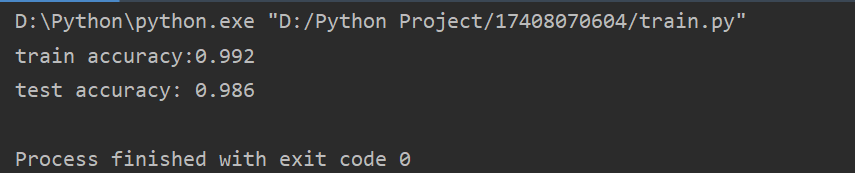
print('train accuracy:{:.3}'.format(score_train))
# 传入测试集,与训练集进行比较,得到其预测值
y_test_pred = clf.predict(x_test)
# 得到测试集的精度,并保留三位小数
print('test accuracy: {:.3}'.format(clf.score(y_test,y_test_pred)))
注:完整代码及注释见源程序
五.运行结果
训练集:

测试集:

六.个人总结
这次的作业是用Python程序实现KNN算法,我个人觉得还是挺难的。主要是因为刚接触到机器学习,常用库里面的一些函数弄不清楚,似懂非懂的很模糊,理解起来也比较难。
所以,我们首先要好好理解KNN算法的原理,能解决的问题。
在这里,我写的程序是一个KNN二分类问题。实现过程比较容易的是模拟数据的创建,难点为推测,主要通过距离公式以及数学运算。
要注意的问题有k值的选择,k值较小,容易发生过拟合;k值较大,容易
发生欠拟合。另外,如果我们没有考虑每个特征的量纲问题,则计算距离的时候可能会出现误差,这是,我们就需要用到归一化,来解决不同的数据在不同列数据的数量级相差过大的话,计算起来大数的变化会掩盖掉小数的变化。在这里,我们用到归一化形式中的min-max标准化(也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间):
总的来说,这次的作业让我们更加深刻的理解了KNN算法,进入了机器学习的大门。机器学习是一门很深的课程,需要我们不断去理解、探索,也需要我们去不断地实践。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









