







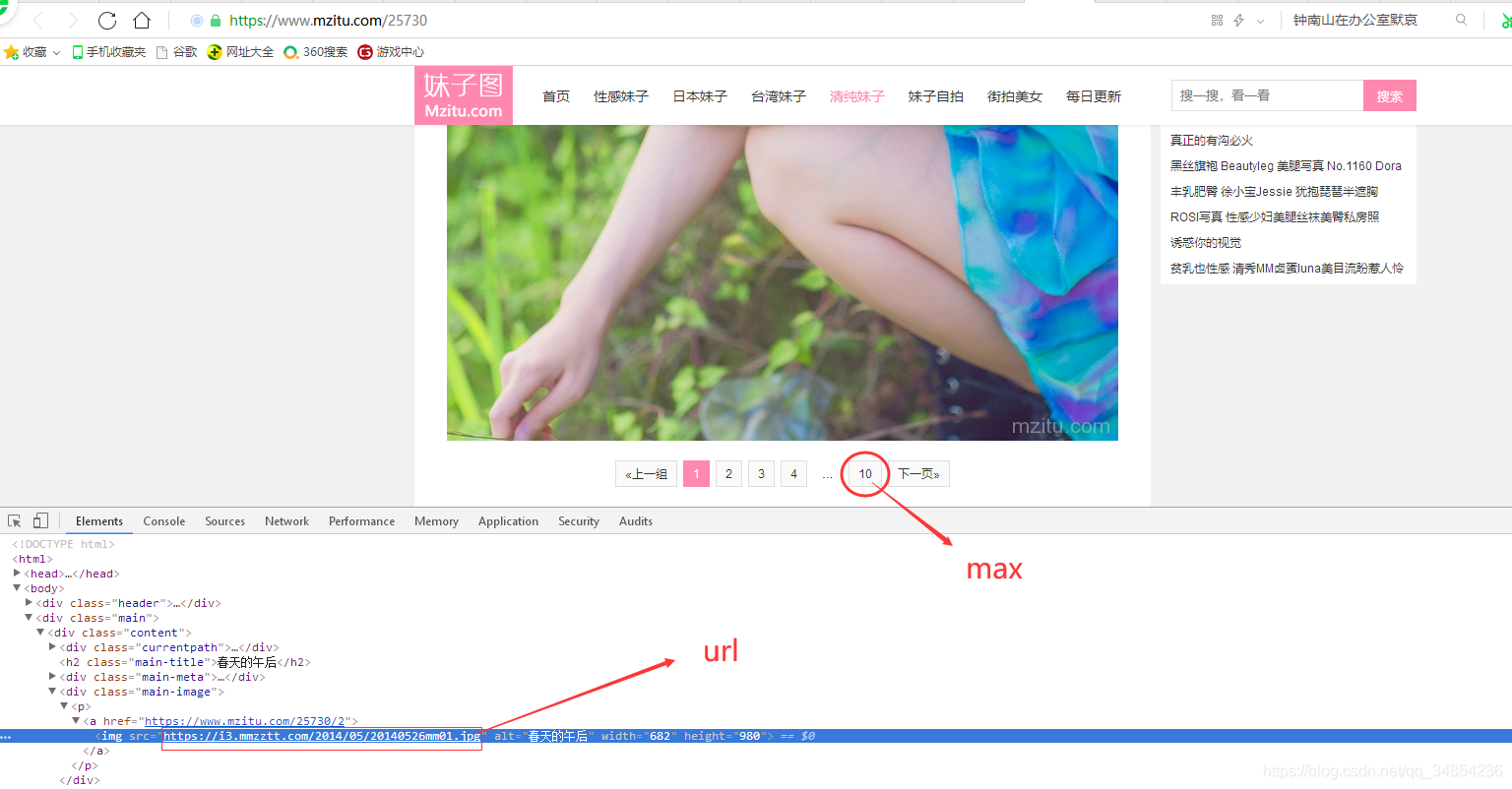
简单写了个爬取妹纸图网站的图片,f12如图下,找到url和max两个关键的参数,修改__main__的下的参数。(没下载一张图片有1秒的休眠)
import requests
import os
import time
def mkdir(path):
paths = path.split('/')
if len(paths) != 3:
print('该路径错误! '+path)
return
a=path.rindex("/");
dir =path[0:a];
if os.path.exists(dir) == False:
os.makedirs(dir)
def downIamge(path,content):
with open(path, "wb")as f:
f.write(content)
def pareUrl(url):
headers = {
"Host": "i3.mmzztt.com"
, "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0"
, "Accept": "image/webp,*/*"
, "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2"
, "Accept-Encoding": "gzip, deflate, br"
, "Connection": "keep-alive"
, "Referer": "https://www.mzitu.com/222376"
, "Cache-Control": "max-age=0"
, "If-Modified-Since": "Sat, 08 Feb 2020 13:08:27 GMT"
, "If-None-Match": "5e3eb2cb-1a360"
}
resp = requests.get(url, data={}, headers=headers)
resp.encoding = 'utf-8'
print(resp)
start = url.index('/', 10);
filePath = url[start + 1:]
print(filePath)
# 创建文件夹
mkdir(filePath)
# 下载图片
downIamge(filePath, resp.content)
def urlAndMax(url,max):
i = 1
index = url.rindex('/')
surl = url[0:index + 4]
eurl = url[index + 4 + 2:]
while i <= max:
param = ""
if i < 10:
param += "0" + str(i)
else:
param += str(i)
url = surl + param + eurl
print("下载地址:" + url)
#休眠1秒
time.sleep(1)
pareUrl(url)
i += 1
if __name__ == '__main__':
url = "https://i3.mmzztt.com/2014/05/20140526mm01.jpg"
max = 10
urlAndMax(url,max)
路漫漫其修远兮














 1351
1351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









