









简介
GEM5 和McPAT 是非常常见的组合,这里介绍了McPAT的论文原理和细节。但不包括如何命令行使用McPAT 工具,不包括具体的文件IO,专注于理解McPAT。
论文
S. Li, J. H. Ahn, R. D. Strong, J. B. Brockman, D. M. Tullsen and N. P. Jouppi, “McPAT: An integrated power, area, and timing modeling framework for multicore and manycore architectures,” 2009 42nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), New York, NY, USA, 2009, pp. 469-480.
这是2009年Micro的论文。
它对比的选择是CACTI。 WATCH。 1他们首先不考虑时序和面积,然后只有动态功耗。2然后WATCH仅对动态功耗进行建模。 3最后WATCH用的简单的线性缩放,对新的(当时是0.8 微米)制成工艺不准,
ORION专门考虑noc,包括面积动态功耗和leakage。但是没有时序的考虑,也没有考虑短路。
初步接触
McPAT是一个读取输入的xml,提供输出结果的程序。
./mcpat -infile input.xml -print_level 5 > output.log
输入大概如下

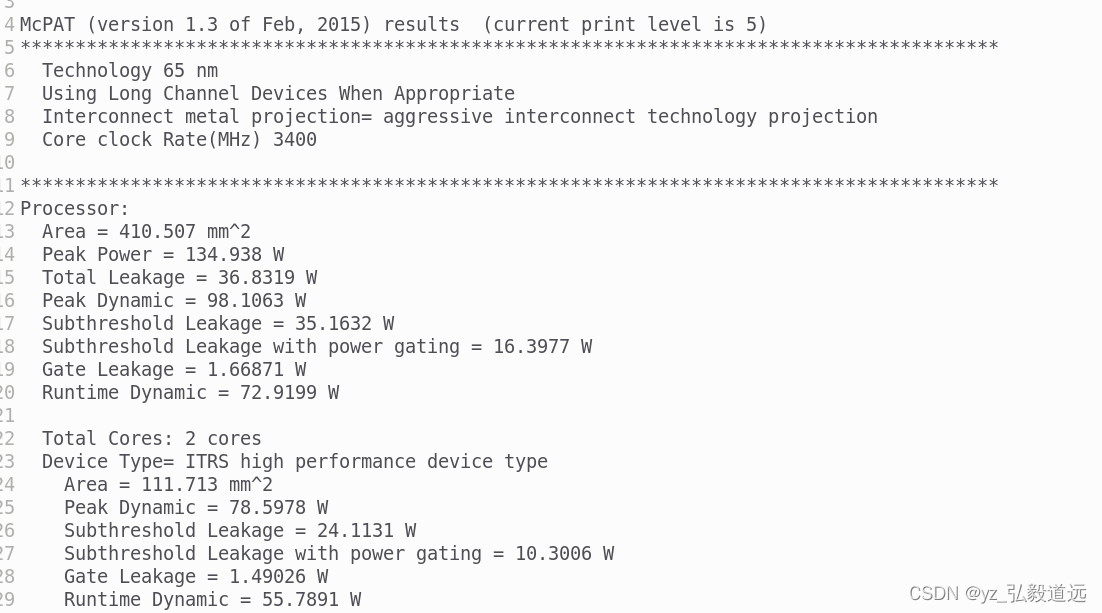
输出如下:
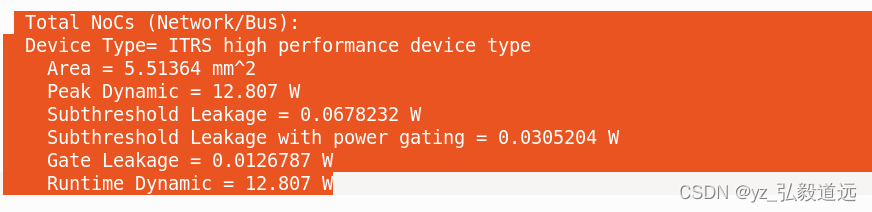
如果只看noc的部分是
用户/使用者角度看过程: two-stage modeling
用户提供目标时钟频率、面积和功率偏差、优化函数以及其他架构/电路/技术参数以后:
1。Mc-PAT 对设计空间进行智能且广泛的搜索。 对于每个处理器组件,McPAT 优化电路级结构以满足时序约束。 然后,如果所得功率或面积不在迄今为止找到的最佳值的允许偏差范围内,则丢弃该配置。 最后,在满足功率和面积偏差的配置中,McPAT应用优化函数来报告最终的功率和面积值。 模块功率、面积和时序模型以及优化器生成的最终芯片表示一起用于计算最终芯片面积、时序和峰值功率。
- 根据统计数据生产运行时功耗。
从设计者角度看过程:集成与三层建模框架
集成指:同时 对功率、面积和时序进行建模的功能。 因此,从电气角度来看,McPAT 能够确保结果相互一致。
分层指:它将模型分解为三个层次:
这为用户提供了跨几代实现技术对各种可能的多核配置进行建模的灵活性。 总而言之,这种集成的分层方法使用户能够绘制设计空间的全面图景,探索设计和技术选择之间在功耗、面积和时序方面的权衡。
下面我们看他怎么介绍架构、电路和技术建模。
架构层次建模
这里有 core 核心,NoC片上网络,onchip caches 片上缓存,内存控制器,时钟电路。
core 核心
“一个核心可以分为几个主要单元:指令获取单元(IFU)、执行单元(EXU)、加载和存储单元(LSU)以及乱序(OOO)发出/调度单元。 OOO 处理器。 它们中的每一个都可以进一步分为硬件结构。 例如,EXU 可以包含 ALU、FPU、旁路逻辑和寄存器文件。 在我们的分层框架中,ALU 和 FPU 映射到电路级的复杂逻辑模型。 旁路逻辑可以映射到线路和逻辑模型的组合,而寄存器文件可以映射到阵列模型。 McPAT 支持基于现有高性能 OOO 处理器的详细且真实的模型。 我们极大地扩展了 Palacharla 等人的基本分析模型。 的工作 [33] 支持基于保留站(数据捕获调度程序)的架构,例如Intel P6架构 [16] 和基于物理寄存器文件(非数据捕获调度程序)的架构,例如如 Intel Netburst [15] 和 DEC Alpha 架构 [19] . McPAT 支持基于 RAM 和 CAM 的重命名逻辑,这些逻辑可以在 Intel 和 Alpha 架构中找到。
McPAT 还对多线程处理器的功率、面积和时序进行建模,无论是有序(例如 Sun Niagara)还是无序(例如 Intel Nehalem)。 由于 McPAT 已包含每个基本处理器的模型,因此通过对硬件资源的共享和重复以及额外的硬件开销进行建模来包含多线程支持。 McPAT 基于 Niagara 处理器 [20] 、 [31] (英特尔超线程技术 [21]) 和 SMT 架构 [42] 的早期研究的设计对多线程架构进行建模。 ”
NoC
NoC 有两个主要组件:信号链路和路由器。 所述 对于信号链路,我们使用分层线路,如第 4.2.2 节 。 我们使用与内核建模相同的分析方法来对路由器进行建模:将路由器分解为基本构建块,例如 flit 缓冲区、仲裁器和交叉开关; 然后为每个构建块构建分析模型。 Orion 2 [18] 与仅对面积和功率建模的 不同,McPAT 对功率、面积和时序建模。 McPAT 是第一个支持双泵浦交叉开关的建模工具 [43] ,它可以减少片上互连密集型设计的芯片面积。
其他还有onchip caches 片上缓存,内存控制器,时钟电路。先不介绍。
电路级建模
这里有4个部分,wire,array,和logic,以及一个时钟分配网络。
工艺水平建模
其实就是90nm、65nm、45nm、32nm 和 22nm 技术节点的数据,
其他亮点:节能模式
这个是主体的框架之外,还实现了一下2种节能模式。
验证
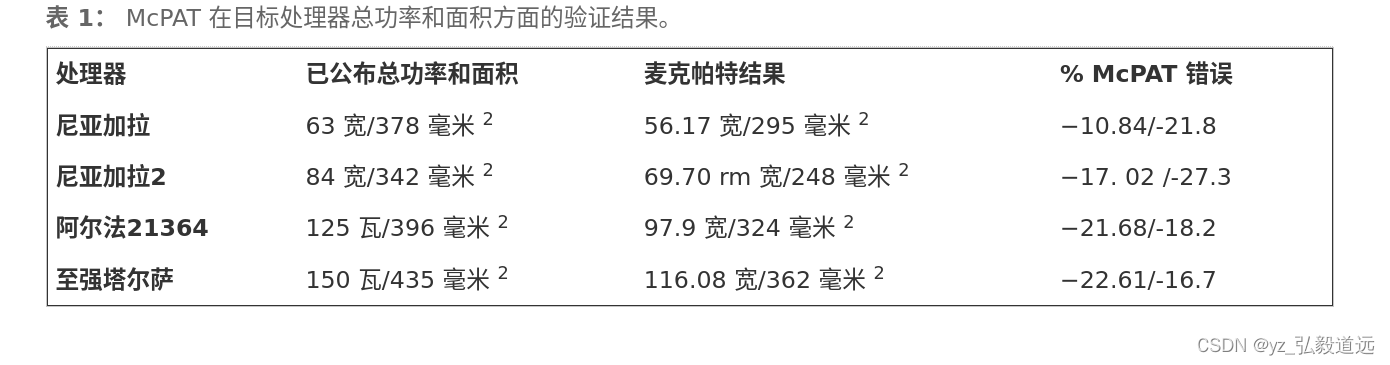
这个三层建模完成后,输出的结果和其他做实物的学者的实际测试结果进行对比。对于 Niagara、Niagara2、Alpha 21364 和 Xeon Tulsa。差距是为 10.84%、17.02%、21.68% 和 22.61%。
McPAT也解释了,这其中有一部分是他们自己不准,也有一部分是这些处理器有很多东西没提供细节,是未知的然后mcpat估计(瞎猜)的。
就比如 Niagara2 的错误较高,因为如上所述,它具有更多 I/O 组件,而这些组件并未在 McPAT 中建模。
结果就如下了:
多核使用
这里大概的意思就是,之前我们建立了一个(黑/白,取决于你是用户还是开发者)盒子,这个盒子作者证明了还不错,能够拟合已有的一些cores。
然后在这一章,他们用这个盒子去尝试了一下多核的情况,得到了一些结果。这有点像GPT,之前训练了一个gpt,然后现在和gpt说我想要有一个多核的,你给我一些结果吧,然后gpt生成了一个结果,作者对这些结果进行分析。
严谨一点说,作者见了一个模型,模型和已有的物理存在的芯片拟合还不错,然后作者将这个模型外推了一下,推测了一堆不物理存在的多核网络。并且对这些推测的结果进行了分析。
推测的依据
频率提升15%
我们每一代都会保守地将时钟频率提高15%左右。 我们还从保守的芯片尺寸开始 200mm2采用 90nm 技术并使用 McPAT 来优化功耗、面积和时序。
核心数
将每一代的核心数量增加一倍。
内存
我们假设内存控制器的数量与集群计数的平方根成正比,因为每个控制器的带宽也会随着时间的推移而增加。 内存通道通过片上网络由所有集群共享,并放置在芯片边缘以最大限度地减少路由开销,如图 4 所示。 所示 如表 2 ,我们还根据主要 DIMM 产品在每个技术节点的预期可用性来扩展主内存的带宽。
推测的值的用处
这些值是基于模型预测的,或者说推测更符合我的理解。
作者认为, 延迟-面积/乘积 (EDA2P)和能量延迟面积积 (EDAP) 是特别有趣的指标。
他分析了工艺从90->22,或者工艺都是22,核心节点从1—>8
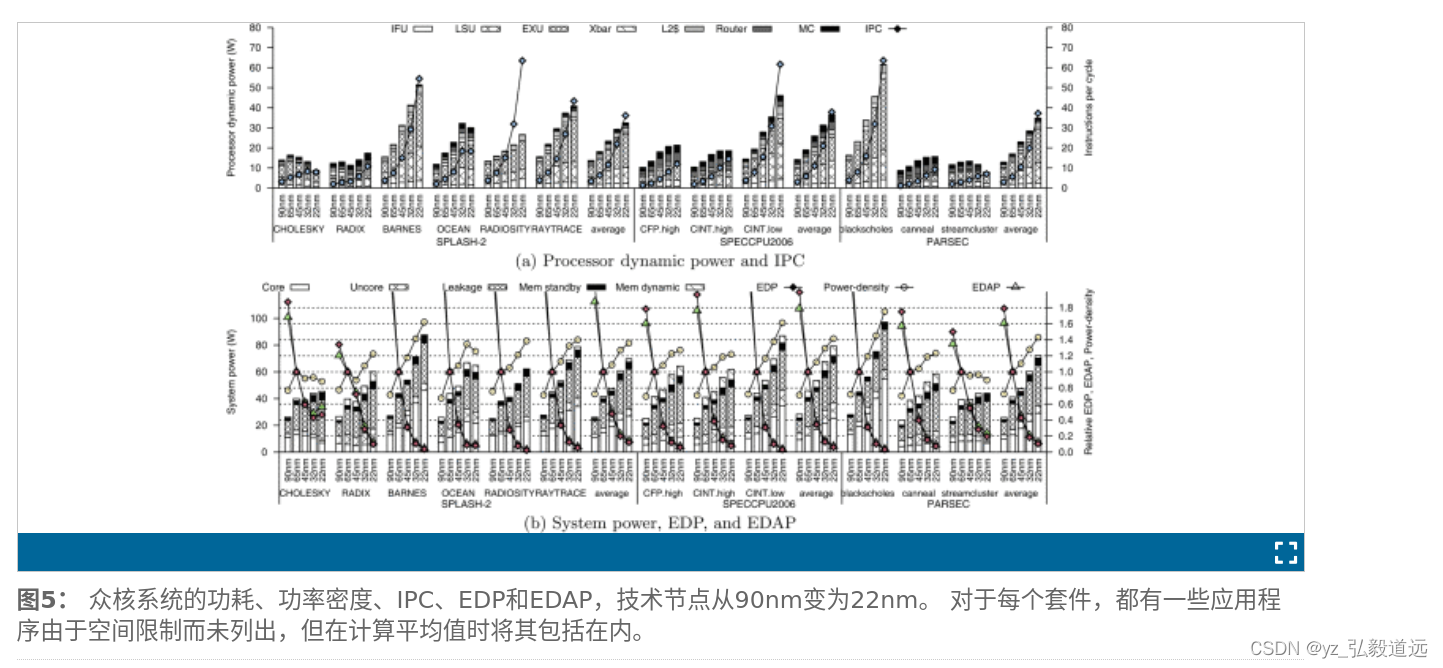
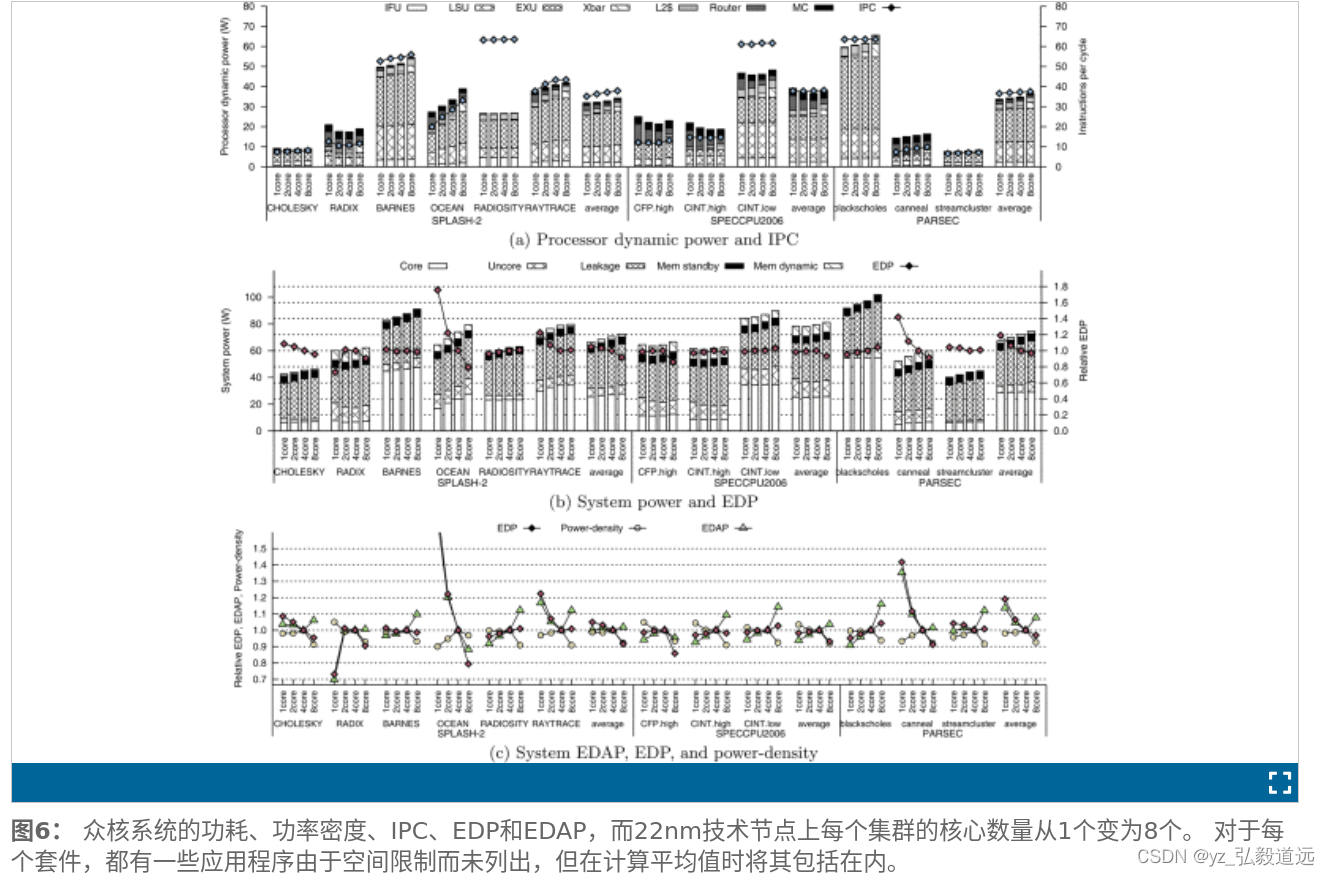
比如他们就说,8个核心有时候不如4个核心好。 “特别是当每个集群的核心数为 8 时。在该配置中,系统能量延迟面积乘积比具有以下配置的配置更差:所有基准测试套件上平均每个集群有 4 个核心。” 注意,这都是他们推测的8个核心的与他们推测的4个核心。
总结
这文章介绍了mcpat,先是介绍了它的工作原理以及和已有的物理存在的芯片对比,然后外推到多核。

















 2407
2407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









