










一、简介:
PANDA(gigaPixel-level humAN centric video Dataset)是清华大学团队构建的国际上首个动态大场景多对象数据平台,场景平均覆盖平方千米级范围,可同时观测数千人,百米外人脸清晰可识别,视频分辨率近10亿像素。本数据集的目的是吸引更多的计算机视觉研究者关注动态大场景多对象数据处理算法的研究,促使检测、追踪等视觉任务在十亿像素视频数据上得以解决。

官网:gigavision.cn
论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9156646
本数据集已举办过ECCV workshop,天池—全球人工智能技术创新大赛【赛道二】
据官方所说,之后会举办ACM MM2021 和ICCV2021 的workshop。
🎇但是现在并没有针对于Gigavision场景所开源的baseline(端到端),为此我们开源了天池竞赛的代码,它很简单却性能优异,希望可以为后来参赛者提供一个性能强劲的Baseline。
二、CSTrack_panda:
我们基于CSTrack做了一些简单的改进,使其更适应于Gigavision场景的跟踪,最终取得A榜0.67/B榜0.625的性能(第五名)。
🔺数据预处理,训练及测试已经更新到CSTrack开源Github中:https://github.com/JudasDie/SOTS
🔺因为我们的改进比较简单,CStrack_panda单张图片处理速度在5s~15s左右。
🔺关于CSTrack可见:https://blog.csdn.net/qq_34919792/article/details/109783123
接下来,我们简述下我们对该数据集的一些分析,在CSTrack上做了些什么改进,以及很多我们因为资源不够原因没有试过的思路(大概率能work)。
1、数据集分析
这次比赛的多目标跟踪场景和MOT Challenge有很大的区别,主要可以分为检测的差异和跟踪的差异。
1) 检测
本数据集的检测相比于MOT Challenge有很大的难度提高,全图是大分辨率的输入图像,不能直接将图像resize进行输入,这样有很多的目标会直接检测不到。所以检测一般需要对图片进行滑窗裁剪成不同尺度大小的图,并送入网络中进行检测,将最终获得的每一个尺度的结果通过一定的策略拼接起来。这个过程也比较困难,因为不同尺度对同一个目标都会有检测结果,而且小的尺度往往不能包含大目标,大的尺度感知不到小目标。而且尺度的选择和如何融合都会决定最终的检测结果。此外在一些场景中,目标与目标之间的遮挡,目标被物体严重遮挡,目标模糊等情况也很影响检测结果。
2) 跟踪
对于跟踪来说,最大的问题就是帧数太低了,比赛时2fps,目标在相邻帧之间存在更大的位移,传统运动模型不适用该场景,易造成轨迹断裂。更通俗易懂的说就是会造成原来CSTrack的很多跟踪参数不能适配这个场景。我们在实验中发现,对参数做一些简单的调参可以获得很好的跟踪效果。此外,在这个场景中,由于场景的覆盖范围广,由于光照等原因容易照成同一个目标在不同的尺度上存在较大的外观差异,这个会造成ID Embeddings的更新策略不可靠而增加匹配难度,造成较大的ID Sw.
2、改进
CSTrack推理过程:
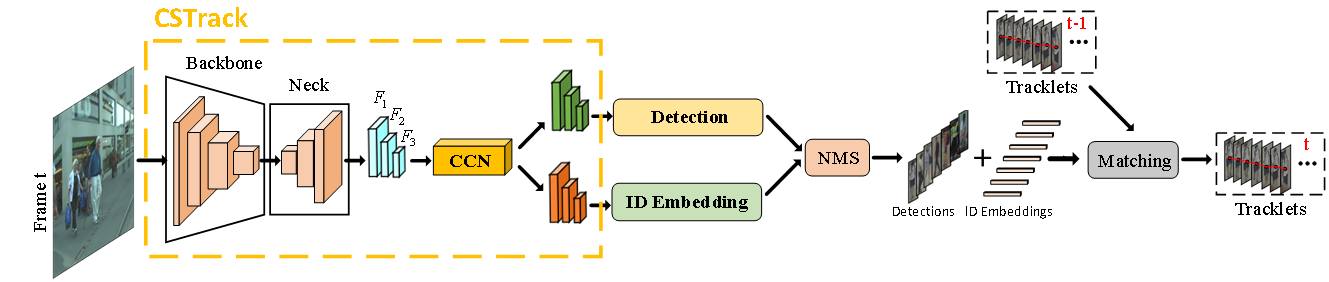
我们基于CSTrack的改进主要如下:
1、多尺度训练和测试
2、NMS -->Dense Mask & WBF
3、匹配参数调节
4、离线增强(后处理和模型堆叠)
1)多尺度训练和测试
这个很好理解,也是基本上所有队伍都会用到的训练方法,为了让模型在训练的过程中适应不同尺度的目标。我们取了几个裁剪尺度[2560, 1440], [5120, 2880], [10240, 5760]和全图,图像之间的重叠率取0.3。
| 方法 | JDE(官方baseline) | CSTrack(开源模型,未训练) | CSTrack(训练) |
|---|---|---|---|
| A榜分数 | 0.3147 | 0.4726 | 0.5062 |
以上对比了训练带来的提升,相比于官方提供的baseline,CSTrack未训练直接做多尺度测试(没有其他改进,融合只用NMS)也可以取得较高的效果(+0.15),训练之后可以为CSTrack带来0.03的提升。
2)NMS -->Dense Mask & WBF
这一部分的调整大概涨了0.03,到0.5350,主要的目的是为了抑制误检。
出发点:
1)通过Dense Mask自适应预估行人的密集程度,替代人为设置的阈值。
2)结合WBF对框加权获得更准确的检测框。

Dense Mask的训练

在线推理
1)计算DIoU,从Dense Mask中相应位置获得DIoU阈值,如果DIoU大于阈值的框和ID Embeddings归为一个集合Ti。
2)通过WBF对集合T中的框和ID Embeddings做加权融合。
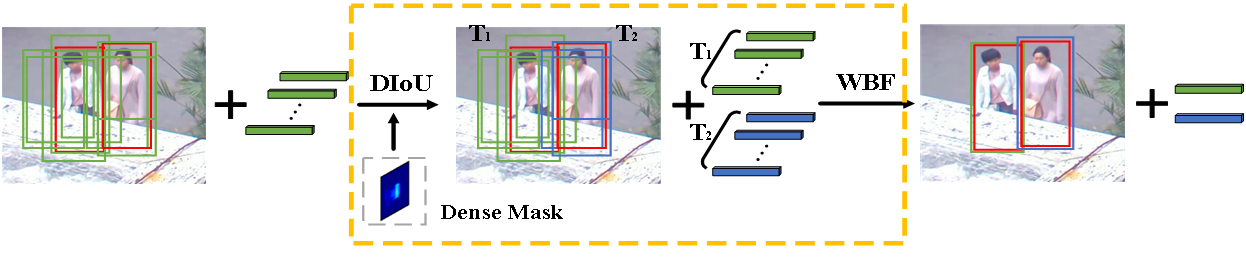
3)匹配参数调节
这个超参数的调节在这个数据集上特别重要,直接从0.5350提升到0.6479左右,提升幅度很明显。主要调参的有以下参数:
| 参数 | 修改前后 | 原因 |
|---|---|---|
| Kalman 滤波参数 | 2➡8 | 太小即使ReID匹配上也会被设置为inf |
| ReID的匈牙利匹配算法阈值 | 0.4➡0.6 | 一秒只抽2帧,外观变化可能会比较大,阈值设置大一点 |
| 每个序列的ID embeddings的线性更新权重 | 0.9➡0.5 | 更相信更邻近帧的外观特征(抽帧太少了) |
| IOU matching的匈牙利匹配算法阈值 | 0.5➡0.9 | 同样抽帧问题,目标都运动太远了,iou会比较小 |
| 第一次检测到的目标都active为轨迹 | - | 很多轨迹跟当前帧没有匹配上,activate带来的FN的下降比FP多,FP可以通过其他方法降低 |
我们分析了CSTrack的跟踪过程,发现上述这些原因造成了CSTrack的跟踪潜力被极大的限制,调节这些超参后获得的结果也显示出我们逐渐释放了CSTrack的高性能。
4)离线增强
1)后处理我们用了一些简单又常用的trick,大概带来0.01的提升,性能A榜接近0.6629。
| 方法 | 原因 |
|---|---|
| 插值 | 对同一个id的轨迹中间断裂的部分通过前后进行线性插值,在mot中大概率能work,但是这种简单粗暴没有判断的做法,在ID sw的情况下很容易带来FP |
| 删除短轨 | 将长度低于一定阈值的轨迹删除,这一部分轨迹大概率是误检,同时如果是断裂的轨迹的话,他们带来的IDsw也使得这部分轨迹在评分的时候不会带来正行增益 |
| 轨迹缝合 | 这个trick在非密集场景是有用的,通过判断一条的轨迹结束的时候在它同方向一定范围内几帧之内是否有新的开始的轨迹,那么认为他们是同一个id,只能在中间的一些位置用,边缘和密集容易带来ID sw |
5)模型堆叠
模型堆叠是在比赛中比较常用的一种手段,可以提高检测的效果。我们堆叠了一个yolov5x,带来了0.01的提升,性能A榜达到0.6712(我们开始比赛太晚了,初赛结束前几天才开始很多检测的东西来不及调整)。
为了方便之后的扩展,我们将这一部分的写成了外接接口,可以更换成其他的性能优异的检测模型进行堆叠。由于检测是没法获得reid特征的,我们做了一个比较巧妙地设计,先运行检测模型,获得额外的检测结果,保存成txt,然后CSTrack在测试的过程中会去读取相应的检测结果,将这些检测结果分配到合适的尺度图上获得对应的ID embeddings,如果直接用CSTrack_panda工程的话,堆叠检测器只需要按相应的格式保存txt并读取就好了,方便堆叠(具体操作见github)。
三、其他的一些个人改进想法(大概率能work):
这些方法因为时间和设备原因,我们并没有来的及做实验,希望能提供进一步改进的思路。
1、训练参数
这次比赛中,我们初赛结束前几天才参与的,失去了很多的检测的调参时间,事实上这一部分对我们模型最终的成绩影响非常大,主要表现在MOTP的分数一直要不前排其他人低一大截。在复赛的时候由于数据集太大了和计算资源有限,我们只是做了两次无调参的训练。所以说CSTrack的训练参数调整和训练策略实际上通过调整还能带来很大的提升。
2、WBF的参数
WBF会抑制掉太多的正确检测(也有可能会把正确检测拉偏),这个并不合理,可以做更多的参数实验,当然,这有很大的原因可能是因为我们的模型训练不够好的问题。
3、Redetection
其实这是一个很有用的trick,我们可以称它为“Redetection”,因为这个数据集有些目标的尺度非常小,如果裁剪太小的尺度来做检测会花费大量时间。因此,对一些小的目标,即使模型检测到,也是一个不匹配的较大框,这时候我们可以通过通过统计图中小目标的位置,然后以小目标为中心裁剪更小的尺度做redetection,这样可以找回一些找不到的,或者框不匹配的目标。
4、时序信息利用
CSTrack实际上检测还是基于image-based的检测器,这一类检测器在视频任务中没有利用时序信息很容易带来漏检。其中利用时序信息最简单的一个思路是额外加一个单目标跟踪器,对每个序列激活一个,提供额外的检测结果(我们Github的库中集成了一些单目标的SOTA跟踪器,如Ocean,方便试试work不work)。而用多目标跟踪的话,可以试试Tracktor的思路,通过回归来增加额外的检测框,或者SiamMOT/CSTrackv2的思路,大概率能work。
5、ID embeddings的表征问题
在实验中,其实不难发现,在如此低的抽帧率下,原有的CSTrack学习到以外观信息为基础的ID embeddings并不具有绝对的鲁棒性。可以试试去增加ID embeddings的学习表征,如DMIP的环境增强思路,CorrTracker的时空表征学习。感觉都会在这个场景中获得增强。
6、GNN替代匈牙利
这个是一个比较容易work且大概率能work的方法,一般我们会将当前帧的检测框和轨迹建立一个图来求解最优匹配,连接边对应的一个值(如余弦距离,iou距离等),匈牙利算法的作用是找到成本最低的匹配方案,但是并不是最优的,可以用一些GNN的思路来替代匈牙利算法,可以参考文章有MPNTrack(CVPR2020)、LPC_MOT(CVPR2021)。
7、堆叠检测结果
引入性能更好的检测模型,或者和CSTrack互补的检测模型。
此外也可以阅读下近几年的MOT/SOT文章,或许还有很多优秀可work的idea可以应用到这个场景中,也推荐我们做的一个方法比较库,里面集合了2017-2021的顶会文章和其他一些有影响力的文章:
https://github.com/JudasDie/Comparison


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









