










《DO DIFFERENT TRACKING TASKS REQUIRE DIFFERENT APPEARANCE MODELS?》——阅读笔记
Paper:https://arxiv.org/pdf/2107.02156.pdf
Github :https://github.com/Zhongdao/UniTrack
摘要:
跟踪视频中感兴趣的对象是计算机视觉中最流行和最广泛适用的问题之一。然而,随着近些年的发展,大量关于案例和数据集基准的探索已经将跟踪问题分散到了不同的实验设置中。因此,文章也是碎片化的,现在社区提出的新方法通常只专门适合一个特定的设置。为了理解这种专业化在多大程度上是必要的,在这项工作中,我们提出了UniTrack,一种解决在同一框架内解决五个不同任务的解决方案。UniTrack由一个单一的和与任务无关的外观模型组成,它可以以监督或自我监督的方式学习,以及多个“头”来处理单个任务,并且不需要训练。我们展示了如何在这个框架内解决大多数跟踪任务,并且可以使用相同的外观模型来获得与所考虑的所有五个任务的特定方法具有竞争力的性能。该框架还允许我们分析使用最新的自监督方法获得的外观模型,从而显著地扩展它们的评估和比较到更多的重要问题。
🔺 JDE同作者的一篇文章,第一次看到摘要的时候感觉到很惊艳,作者想将所有的tracking任务整合在一个框架中,且不同训练,毕竟惊艳。因为在做tracking的任务的时候,通常可以需要完成两个子任务,一个是相似性比较关联(MOT)或者说传播预测相似性的位置(SOT),另一个是框或者mask的回归,这两个要做到通用所有的任务感觉都挺难的。
1、摘要:
在分类中,作者将现有的跟踪任务视为传播问题或关联问题。当任务为传播问题的时候(即SOT和VOS),我们需要通过上一帧给定的信息来定位当前帧目标的位置。相反,在关联问题(MOT、MOTS和PoseTrack)中,给出了之前和当前帧中的目标状态,其目标是确定两组观测结果之间的对应关系。我们展示了目前文献中考虑的大多数跟踪任务如何可以简单地从传播或关联的初衷开始表示。对于传播任务,我们采用了现有的框和mask传播算法(SiamFC、DCF)。对于关联任务,我们提出了一种新的基于重建的度量,它利用细粒度对应来度量观察结果之间的相似性。
在提出的框架中,每个单独的任务被分配给一个专门的“头”,允许以适当的格式表示对象,以与相关基准上的现有技术进行比较。
请注意,处理传播和关联原语的组件,以及特定于任务的头,都不包含可学习的参数;只有基本外观模型可以学习。重要的是,我们不在单个目标任务上训练外观模型。相反,我们采用了在社区中流行的与任务不可知的监督或自我监督模型,这些模型已经在基于图像的任务中证明了它们的有效性。通过这种方式,我们的工作还用于评估和比较从自我监督学习方法(见图1)中获得的外观模型,超出了文献中常见的有限的基于图像的问题集。
🔺 作者将多个任务统一到一个框架中的思路共用了一个特征学习网络,通过这个网络来学习适用于所有任务的外观信息,然后通过不同的head来实现不同的任务。
2、The UniTrack Framework:
1)Overview
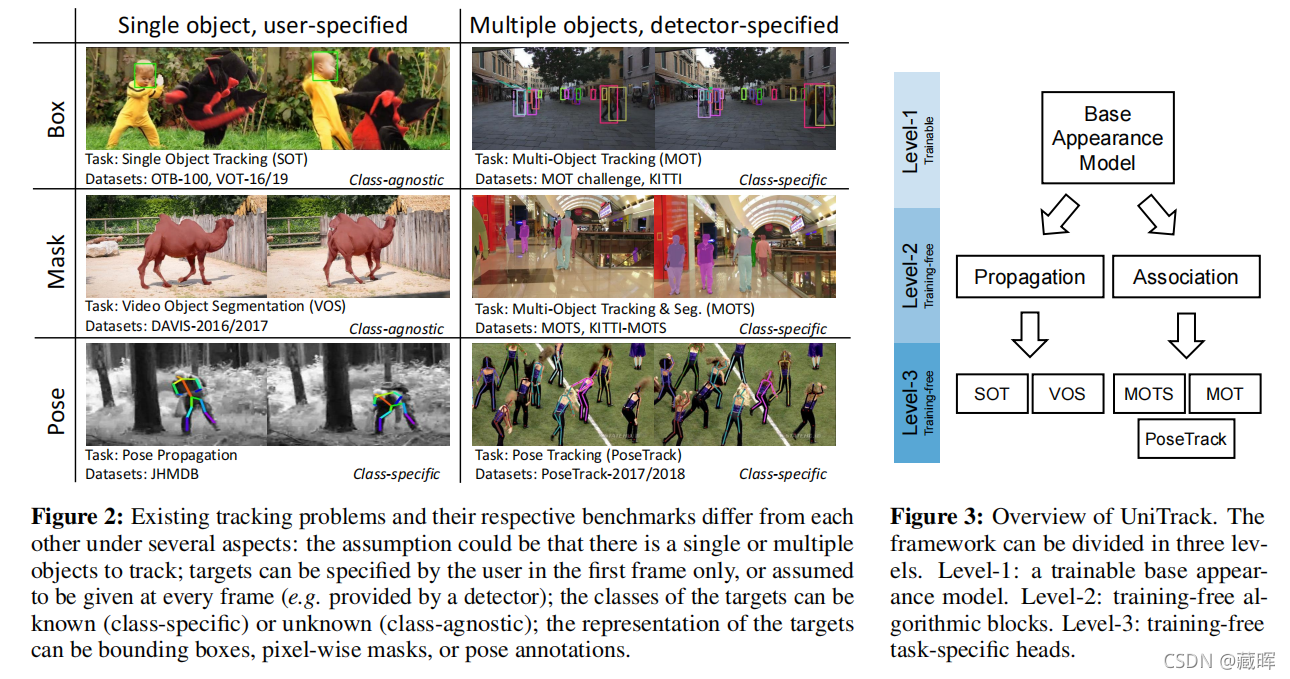
在检查现有的跟踪任务和基准测试时,我们注意到它们的差异可以大致跨四个轴进行分类,如图2所示,详细说明如下:
1、是需要跟踪单个对象(SOT[32]、[82]、VOS[54]),还是需要跟踪多个对象(MOT[54]、MOTS[69]、PoseTrack[1])。
2、目标是只由用户只在第一帧中(SOT,VOS)指定,还是在每帧中给出,例如。通过预先训练的探测器(MOT,MOTS,PoseTrack)。
3、目标对象是由边界框(SOT、MOT)、像素级掩码(VOS、MOTS)还是姿态注释(PoseTrack)表示。
4、任务是否与阶级不可知论。目标对象可以属于任何类(SOT、VOS);或者,如果它们来自预定义的类集(MOT、MOTS、PoseTrack)。
图3描述了所提出的UniTrack框架的示意图概述,它可以理解为在概念上分为三个“级别”。
第一层由外观模型表示,负责从输入帧中提取高分辨率的特征图(第2.2节)。
第二级由两个基本算法构建成,包括传播(propagation,第2.3节)和关联(association,第2.4节)。
最后,最后一级包括直接使用第二级的输出进行多个特定于任务的算法。
2)基础外观模型(Base appearance model)
基本外观模型φ以二维图像I作为输入,并输出特征图X=φ(I)∈RH×W×C。由于理想情况下,用于对象传播和关联的外观模型应该能够利用图像之间的细粒度语义对应,我们选择一个小步幅为r=8的网络,使其在特征空间中的输出具有相对较大的分辨率。我们将特征图中单个点的向量(沿信道维数)称为点向量。我们期望特征图X1中的点向量xi1∈RC与X2中的“真正匹配”点向量xi2具有很高的相似性。而与X2中所有的“假匹配”点向量xj2相差很远。我们期望s(xi1, xi2) > s(xi1, xj2), ∀j = ˆi,其中s表示相似性计算方程。
为了学习细粒度的对应关系,完全监督的方法只适用于合成数据集。对于真实世界的数据,很难以完全监督的方式来获得像素级的对应标记和训练模型。为了克服这一障碍,我们在本文中探讨了两种可能的解决方案。第一个是灵感来自于之前的工作,这些工作指出了细粒度对应是如何出现在中层特征中的。因此,一个以前训练过的分类或度量学习模型可以作为我们的基本外观模型。第二种灵感来自自监督学习方法的进展,该方法专门利用像素级的pretext任务。在本文中,我们通过测量它们在五个不同的跟踪问题上的性能来通过经验探讨哪种表示是最好的。
🔺看了这些自监督的引用的工作后,对这个能这样学出来感觉很神奇,知乎上有一些总结做的也不错(https://zhuanlan.zhihu.com/p/150224914?from_voters_page=true),像我一样不大懂自监督为啥可以学出这些表示的可以参考一下,大牛跳过。
3)传播(Propagation)
SOT和VOS中的传播都是给定了上一帧的观测做为输入,然后预测在下一帧中该物体的位置信息。 作者讲这种传播分为三个对象来表示,即边界框,分割掩模和姿势骨架。
Mask propagation
为了传播掩模,我们依赖于最近的视频自我监督方法所推广的(基于注意力的)方法。考虑一对连续帧Xt-1和Xt的特征图,他们都属于RsxC,以及前一帧的mask zt-1∈[0,1]s,其中s = H x W表示空间分辨率。我们计算迁移矩阵Ktt−1=[ki,j]s×s作为Xt−1和Xt之间的亲和矩阵。每个元素ki,j都被定义为:
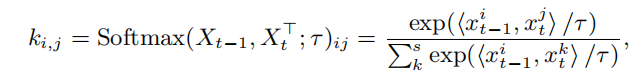
对于Ktt−1,只保留每行的top k的值,并将其他值设置为0。然后,通过传播之前的预测:zt=Ktt−1zt-1来预测当前t帧的掩模。掩码传播以循环方式进行:当前帧的输出掩码用作下一个帧的输入。
Pose propagation
为了表示姿态关键点,我们使用了广泛采用的高斯信念图(Gaussian belief maps)。对于一个关键点p,我们用一个均值等于关键点的位置和方差与受试者的体型成正比的高斯曲线,得到了一个信念图zp∈[0,1]s。为了传播一个姿态,我们可以单独以与掩模传播相同的方式传播每个信念图,同样是zt=Ktt−1zt-1。
Box propagation
物体的位置也可以用四维向量z=(u、v、w、h)更简单地表示,其中(u、v)是边界框中心的坐标,(w、h)是它的宽度和高度。尽管我们可以通过简单地将边界框转换为像素级掩码来重用上述策略,但我们观察到,使用这种策略会导致不准确的预测。相反,我们使用SiamFC的方法,它包括在目标模板zt−1和Xt帧之间执行互相关(XCORR),以寻找目标在t帧的新位置。互相关在不同的尺度上执行,以便边界框表示可以相应地调整大小。我们还提供了一个基于相关过滤器的替代方案(DCF),它也不涉及任何训练。
4)关联(Association)
关联问题用来解决MOT、MOTS和PoseTrack的任务。在这种情况下,对所有帧{Iˆt}Tt=1的观测结果为{Zˆt}Tt=1,通常由预先训练的检测器提供。这里的目标是通过根据相邻帧的观测结果来形成轨迹。
Association algorithm
用了已有的JDE的方案来做。具体来说,我们计算了已经存在的N个轨迹和来自最后一个处理帧的M个“新”检测结果之间的N个×M个距离矩阵。然后,我们以距离矩阵为输入,使用匈牙利算法来计算确定轨迹和检测之间的匹配关系。为了得到该算法所使用的距离矩阵,我们计算了考虑运动和外观线索的两个项的线性组合。对于前者,我们计算一个矩阵,指示一个检测的可能性与卡尔曼滤波器预测的目标状态对应。
🔺 具体可以参考我之前的一篇文章:https://blog.csdn.net/qq_34919792/article/details/107633874
对于后者,外观组件是使用跨帧观察的视觉特征来计算的:一个给定的框架首先由基本外观模型处理,以获得一个帧级的特征映射。然后,虽然通过裁剪帧级特征映射可以直接获得与框和掩模表示对应的对象级特征,但当对象通过姿态表示时,首先需要将其转换为掩模。
此场景的一个关键问题是如何度量实例级特性之间的相似性。我们发现现有的方法都有一定的局限性。首先,通常通过将每一个目标的特征映射合并为一个向量或者其他的表征来计算余弦相似度,用来比较对象之间的关系。然而,平均池化本质上丢弃了局部信息,这对于细粒度识别很重要。有些方法在某种程度上保留了细粒度的信息,例如那些计算(扁平) 特征映射的余弦相似性的方法,不支持具有不同大小表示的对象(例如出现像素级掩码的情况)。为了应对上述限制,我们提出了一种基于重建的相似度度量,它能够处理不同的观察格式,同时仍然保留细粒度的信息。
Reconstruction Similarity Metric (RSM)
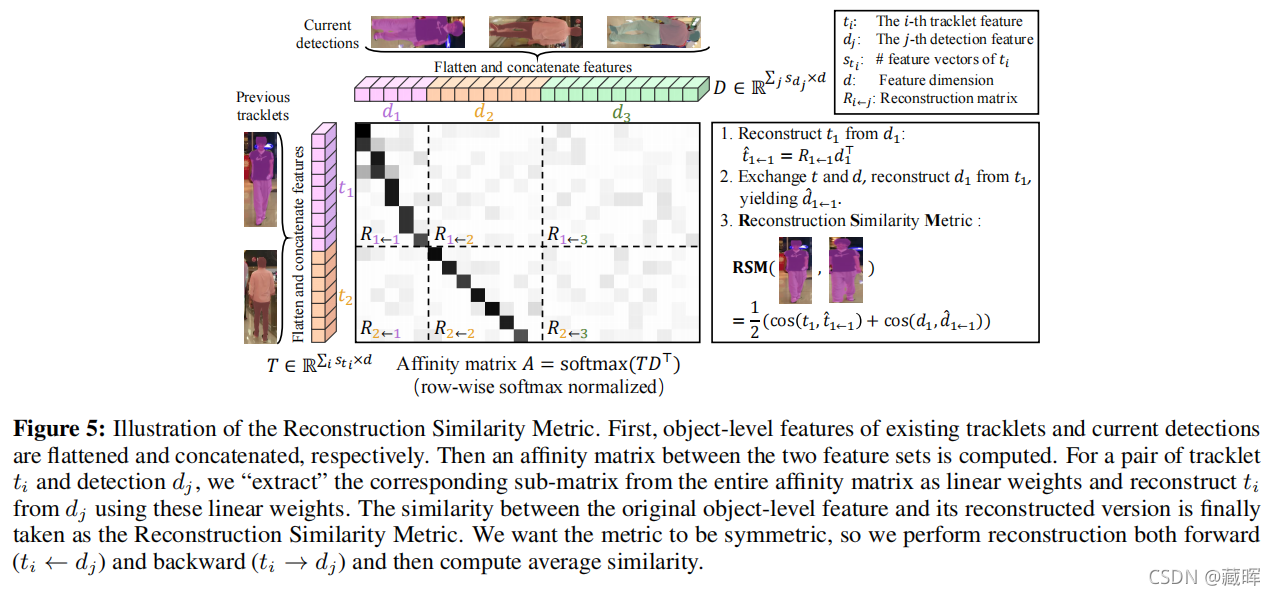
设{ti}Ni=1表示N个现有轨迹的物体级特征,ti∈Rsti×C和sti表示物体的空间大小,即框或者mask内的像素量。类似的,{dj}Mj=1表示M个新检测的对象级特征。为了计算相似性,获得一个N×M亲和矩阵提供给匈牙利算法,我们提出了一种新的基于重建的相似度度量(RSM),其中值的计算如下:
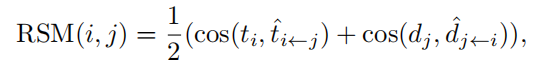
其中tˆi←j表示dj重建的ti,dˆj←i表示ti重建的dj。在多对象跟踪场景中,由于频繁的遮挡,观察往往是不完整的。因此,直接比较特征之间不完整和完整的观察结果常常由于局部特征之间的失调而失败。假设dj是一个代表一个人的半个身体的检测特征,而轨迹特征代表一个人的整体,如果我们直接计算相似性(e.g.使用余弦度量),它们的相似性可能相当小。RSM通过引入重建步骤来解决这个问题,这可以理解为一个对齐过程。重建后,点特征的共现部分被对齐,因此最终的相似性变得更有意义。
重构的对象级特征图tˆi←j是dj的一个简单的线性变换,即 tˆi←j=Ri←jdj,其中Ri←j∈Rsti×sdj是一个变换矩阵,得到如下。我们首先将所有对象级特性扁平并连接为一个长的向量(即与一个物体对应的观测集)成一个单一的特征矩阵T。同样,我们得到了一组新的检测D的所有对象级特征图。之后,我们计算的亲和矩阵A=Softmax(TDT),并“提取”单个Ri←j映射作为A关于相应的(i、j)跟踪检测对的子矩阵。有关刚才描述的过程的示意图,请参见图5。
RSM可以从注意力的角度来解释。被重构的轨迹图的特征图可以看作是一组查询,“源”检测特征dj可以同时解释为键和值。其目标是通过这些值的线性组合来计算查询。线性组合(注意)权重是使用查询和键之间的亲和力来计算的。具体来说,我们首先计算ti和所有dj(j=0,1,…,M)之间的全局亲和矩阵,然后提取ti和dj对应的子矩阵作为注意权值。我们的公式得到了一个期望的性质:如果注意力权值接近零,相应的重构点向量将接近零向量,最后ti和dj之间的RSM将趋于零。
通过重建来测量相似性在少样本显示学习,自我监督学习和行人重识别等问题中很流行。然而,重建通常被定义为一个脊回归或最优输运问题。RSM比岭回归更有效(它在时间上有O(n2)复杂度,而岭回归求解器通常有更高的复杂度),并且在计算最优输运问题的Earth Moving Distance的计算上相似。
🔺在多目标的任务中,这个框架更加关注的是关联问题,采用了其他的框架的box结果(FairMOT)或者mask结果(COSTA),并没有单独生成。在实验上作者说用了在imgenet上预训练的模型,虽然没有取得最优的性能,但是一个框架可以完成怎么多的任务,这个性能也是具有很强的竞争力。其他实验结果和分析推荐去阅读原文。
总结下,本文将五个跟踪任务统一到一个框架UniTrack中进行解决,并分析了在imagenet或者自监督学习到的外观模型为什么能具有这样的区分能力,阅读过程中学习到了很多。在实验上,虽然有一定的限制(如果在指定的数据集上进行专门的训练可能会相对高一些),但是可以同时完成多个任务,具有竞争力的。当然这个框架有一定的限制,并不能真正意义的完成多个tracking任务,在多目标跟踪中的框和mask都是用的现有的结果,只关注了匹配任务。也希望后续有工作可以把这种box、mask、key points的预测也unity到一起。














 3253
3253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









