










什么是特征转换
特征转换就是将原始资料(不容易数据化)转换为有意义的资料(能够数据化),或者说是计算机能够处理的资料。
比如说我们可以将像素点转换为一些有强度特制的,对称性的资料以便我们从中找出规律。还比如我们上次提到的X空间-->Z空间-->X空间的方法(一个非线性分割的例子详情请点击打开链接)。
特征转换遇到的问题
当我们将一个低维度的非线性的模型转换成高维度的线性模型的时候我们会有3方面的复杂度的增加:①空间转换成本聚增,②存储的消耗量聚增,③模型复杂度的聚增这样会导致我们的学习十分困难。
空间转换的成本
在X空间的d维资料从原始X空间转换到Z空间的过程可以看作是一个低维度的空间到高纬度空间的转换。如下图:

我们可以看出d维资料在Q次的多项式转换后的维度(使用排列组合的方法去计算)如下:

从计算上的代价来看,假设我们由2维的资料变成6维的资料我们在进行一次的权重更新的时候放到以前我们只需要做2次的更新而放到现在我们需要做6次的更新。
从存储上也成为了原来的3倍。
模型复杂度的聚增
在X空间中我们的VC维度为d+1,而在Z空间中空间的复杂度变成了它的O(Q^d)倍。在VC维度增大之后模型复杂度会增加我们能够做更加复杂的动作使得Ein≈0而Ein与Eout相差很远。所以我们需要做到以下的均衡。

如何降低复杂度
人脑计算降维以一个正圆分割为例:

我们写一个普适性的式子的话需要写6项但是我们通过观察这个图像进而将这个式子降维成3项2项甚至是一项。这当然是一种选择但是这不是机器学习这加入了我们脑子的模型复杂度这个过程带有人脑学习的过程!
另一种安全的方法
我们从0维的转换到Q维的转换的过程如下:
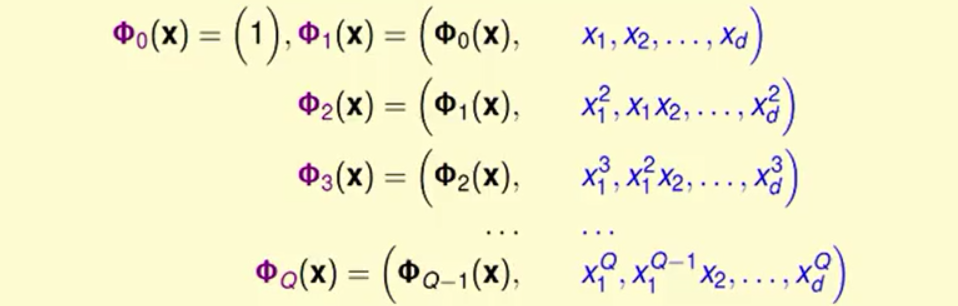
我们会发现前一种转换是后一种转换的子集,体现在模型上就是后面的复杂度高的模型会是简单模型的更加通用的版本而前面的简单模型是后面模型的特殊情况。
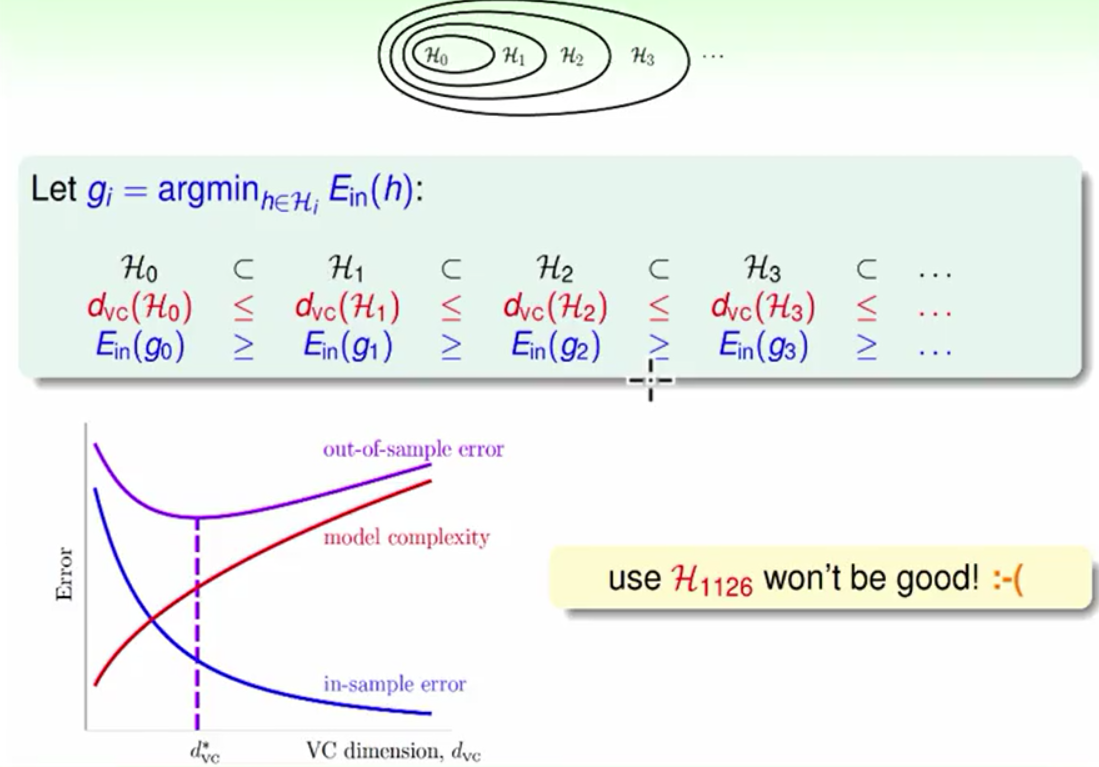
越往后面dvc就越大,H的功能就越强能够shatter的点就越多,模型复杂度就越高,Ein就越小。从以前的Error-VC的图来看我们需要的是一个适当的复杂度,在这里我们的解决方法就是从低的维度开始走向高维度可以实现有效的降维与均衡。
总结:这两种方法都不是非常高效的方法,接下来我们会间接提出更为有效的方案。不过在提出之前首先介绍一下过拟合。
过拟合
事实上在整个机器学习的过程中我们一直都在与过拟合作斗争,从未停止。
一个案例

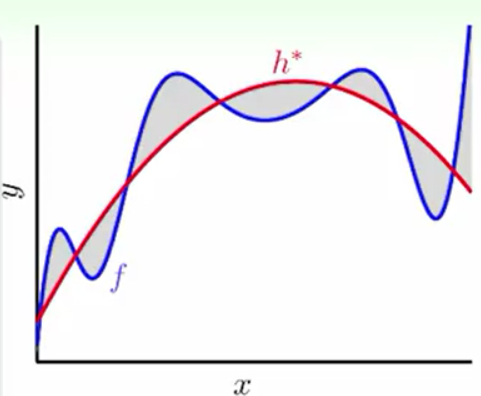
上图所示,我们想要做一个一维的回归分析的模型我们要输出一个实数,假设我们提前知道了我们的目标函数是一个2次函数(Target),但是由于有杂讯的存在我们的2次函数只能在大部分的点上作对,同时我们能后教好的预测资料(泛化能力很强)。与此同时可能有一个4次的多项式(Fit)它比2次多项式在样本上也做得好甚至把杂讯的资料都做对了,但是它在预测新的资料上做的很差(泛化能力弱)。我们就说这个4次多项式发生了过拟合。
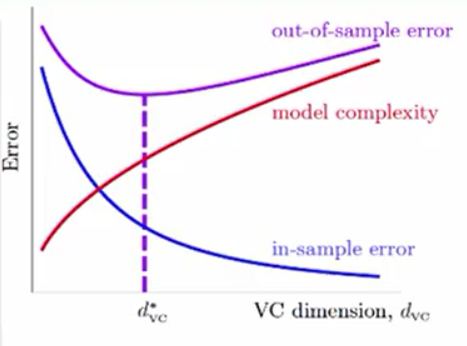
从Error-VC图上来讲,我们称d*vc到dvc很大的时候就是Overfit(过拟合),这时Ein减小,Eout增大。我们做的过头了!
与过拟合相对的是欠拟合但是我们可以提高模型复杂度很轻易的解决它,所以我们的大部分经历是去解决过拟合问题。
过拟合的原因
如果把Overfit比喻成一场车祸那么造成它的原因就会有以下3种情况:
①使用了强有力的dvc(开车太快)
②资料中有噪音(坏的路况)
③资料量太少(知道的路况少)
一些过拟合的实例
我们现在分别使用两笔资料第一笔资料是由一个10次的多项式加上杂讯产生,第二笔资料是由无杂讯的50次多项式产生。分别使用2次的与10次的学习模型去学习这两比资料它们所犯的错误如下:
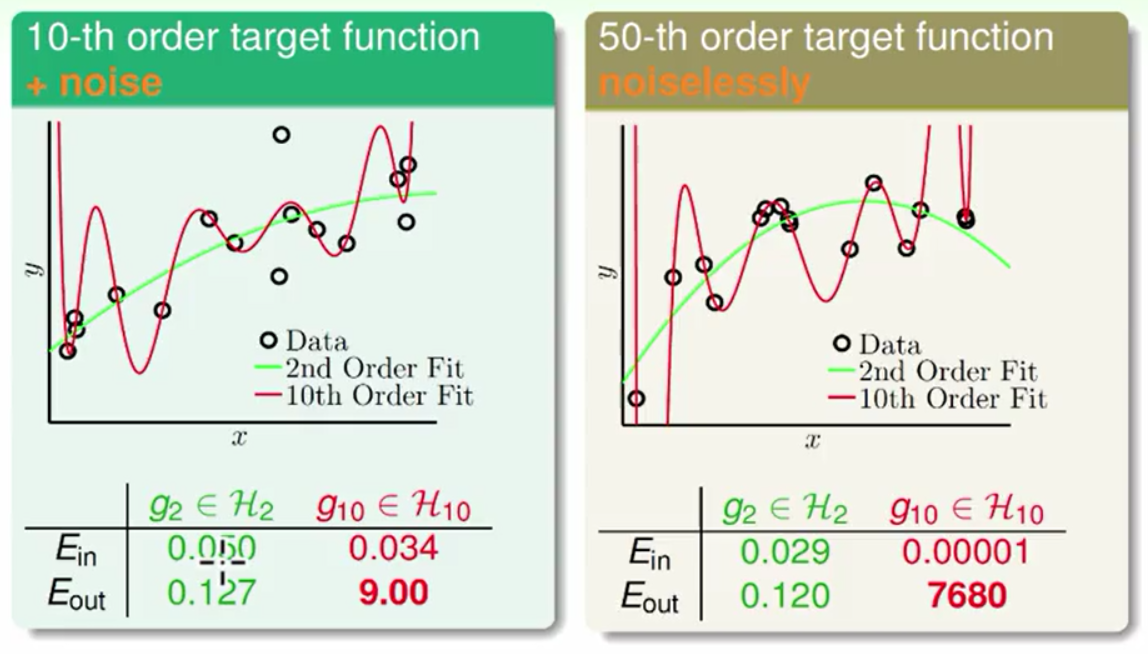
我们可以看出无论是在哪张图上由于10次多项式的学习能力强所以它的Ein都小于2次多项式,但是由于10次多项式出现了过拟合所以它的Eout比2次多项式大几个数量级。这是一个自然规律我们的目标资料是带有杂讯的10次多项式产生的(或者是50次的多项式产生的)但是我们用10次的学习模型反而做不好。体现在学习曲线上如下图所示:
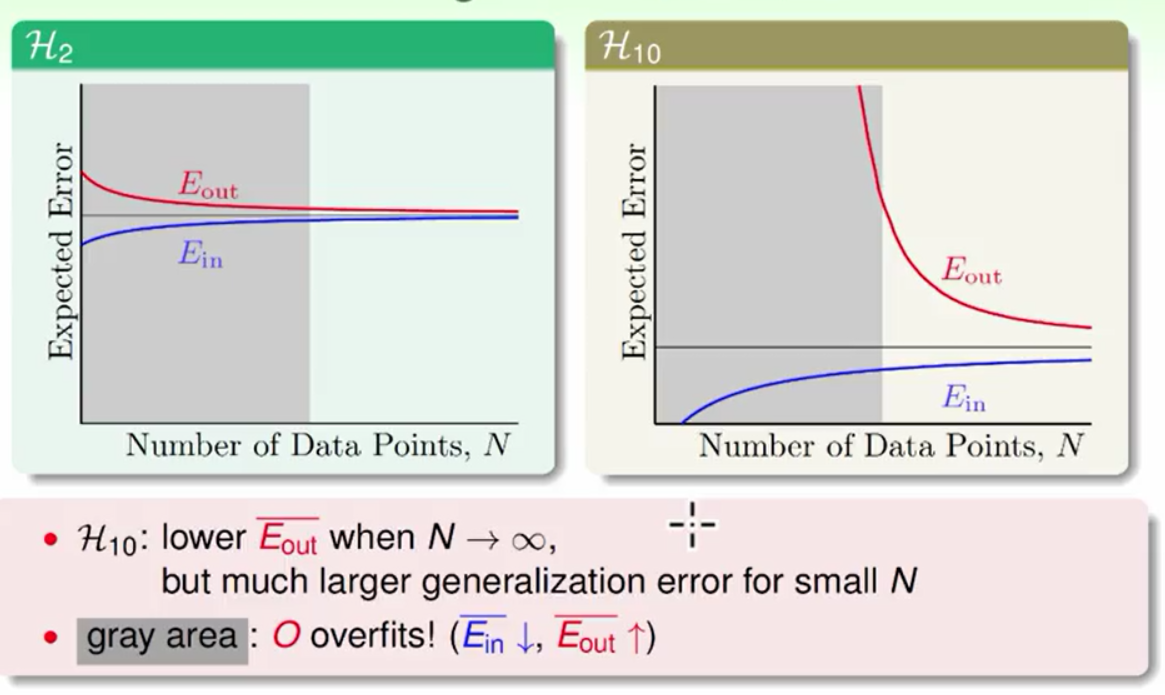
由于我们是拿着样本来做训练的所以我们在样本上的表现要好于样本外的结果,这也就说明了为什么图中的Ein<Eout。随着数据量的增大Ein就会越来越接近Eout,但是在资料量小的时候就会出现Ein较小Eout较大的情况,而且在模型复杂度高的情况下相差很大这时就发生了过拟合。
一个特殊的杂讯
在上述的案例中我们无论是用一个10次的多项式加上杂讯产生资料,还是由无杂讯的50次多项式产生资料多项式的表现大体相似,事实上在第二笔资料中隐藏了一个杂讯。第二笔资料是由一个非常复杂的多项式产生,2次与10次都无法去拟合它,这些差距就产生了一种由模型复杂度产生的杂讯。就好比是电脑中的随机数都是一个确定的非常复杂的计算所产生的,我们看起来它是一个随机的数字事实上它是有确定性的。
深入了解过拟合
我们假设杂讯服从正态分布杂讯的强度是σ²,假设产生资料的多项式的最高次为Qf,资料量的大小为N则有如下的结论。
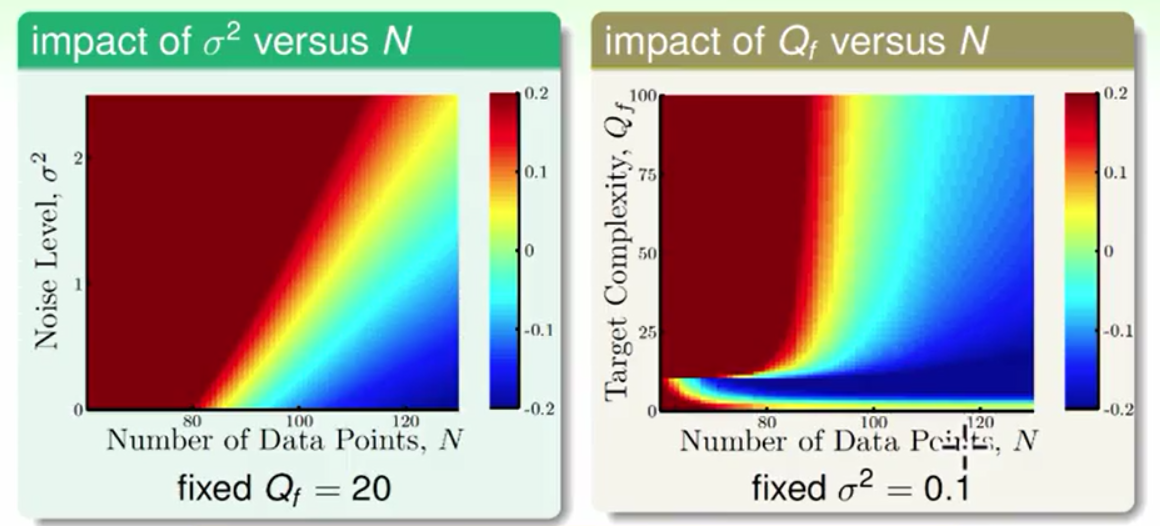
左图是杂讯强度σ²-资料量N对过拟合的影响,右图是模型复杂度Qf-资料量N对模型复杂度的影响。图像说明:越往蓝色的部分越不容易过拟合,越往红色部分越容易过拟合。我们看出在左上角上角很容易过拟合,而右下角不容易过拟合。结论就是在其它条件不变的情况下增加资料量会减少过拟合,在资料量一定的情况下减少杂讯或者是模型复杂度都会减少过拟合。同时又看出了模型复杂度所产生的杂讯与随机的杂讯有相似的性质。
围绕这些产生过拟合的原因机器学习领域有一些高效的防止过拟合的技法:
如果把Overfit比喻成一场车祸那么造成它的原因就会有以下3种解决方法:
增加资料量(知道更多的路况)
正则化(不要开得太快)
不断检查(看仪表盘),这些技法我们下次介绍。
















 577
577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











