






1.前言
JDK21 计划23年9月19日正式发布,尽管一直以来都是“版随意出,换 8 算我输”,但这么多年这么多版本的折腾,若是之前的 LTS 版本JDK17你还觉得不错,那 JDK21还是有必要关注一下,因为会有一批重要更新发布到生产环境中,特别是被众人期待已久的虚拟线程,纵然说这东西我感觉没有必要的用不到,需要的早已转go了,但作为近几年JDK一个“重要”的更新,在实际开发应用中还是有相当的价值。如果说之前的 JDK17你还觉得没必要折腾,那 JDK21确实有必要关注一下了。因为 JDK21 引入了一种新型的并发编程模式。当前 Java 中的多线程并发编程绝对是另我们都非常头疼的一部分,感觉就是学起来难啃,用起来难用。但是转头看看使用其他语言的朋友们,根本就没有这个烦恼嘛,比如 GoLang,感觉人家用起来就很丝滑因此这篇文章主要摘录了这次更新中个人觉得相对有价值的几点做个基本的介绍,想要体验新功能的同学可以阅读一下。
2.JDK21主要特型
2.1 结构化并发
结构化并发是一种编程范式,旨在通过提供结构化和易于遵循的方法来简化并发编程。使用结构化并发,开发人员可以创建更容易理解和调试的并发代码,并且不容易出现竞争条件和其他与并发有关的错误。在结构化并发中,所有并发代码都被结构化为称为任务的定义良好的工作单元。任务以结构化方式创建、执行和完成,任务的执行总是保证在其父任务完成之前完成。
Structured Concurrency(结构化并发)可以让多线程编程更加简单和可靠。在传统的多线程编程中,线程的启动、执行和结束是由开发者手动管理的,因此容易出现线程泄露、死锁和异常处理不当等问题。
使用结构化并发,开发者可以更加自然地组织并发任务,使得任务之间的依赖关系更加清晰,代码逻辑更加简洁。结构化并发还提供了一些异常处理机制,可以更好地管理并发任务中的异常,避免因为异常而导致程序崩溃或数据不一致的情况。
除此之外,结构化并发还可以通过限制并发任务的数量和优先级,防止资源竞争和饥饿等问题的发生。这些特性使得开发者能够更加方便地实现高效、可靠的并发程序,而无需过多关注底层的线程管理。
2.2 作用域值
作用域值是JDK 20中引入的一项功能,它允许开发人员创建受限于特定线程或任务的值。与线程本地变量类似,作用域值可以与虚拟线程和结构化并发一起使用。通过作用域值,开发人员可以以结构化的方式在任务和虚拟线程之间传递值,而无需复杂的同步或锁定机制。这种特性非常适用于在应用程序的不同部分之间传递上下文信息,如用户身份验证或请求特定数据。使用作用域值,我们可以更加优雅地处理并发编程,并提高代码的可读性和维护性。
2.3 禁止动态加载代理
在运行时动态加载代理时发出警告。这些警告是为了未来的版本做准备,以默认禁止动态加载代理以提高系统完整性。为了平衡下面两点
-
可维护性(对运行代码进行特殊修改的能力) -
完整性(假设运行代码不会被任意更改)
同时,还确保大多数不需要动态加载代理的工具不受影响。另外,该计划要求保持动态加载代理的能力与“超能力”功能(如深度反射)的一致性。代理是一种组件,可以在应用程序运行时更改应用程序代码。这个概念最初在2004年JDK 5的Java平台分析架构中引入,作为一种让工具(特别是分析器)检测类的方法。尽管代理最初被设计用于良性检测,但高级开发人员发现它有一些用例,比如面向切面编程可以以任意方式改变应用程序行为。同样,代理也可以改变JDK本身等代码。因此,JDK 5要求在命令行中指定代理,以确保应用程序所有者批准使用代理。在JDK 21中,计划要求像启动时加载代理一样,需要应用程序所有者批准动态加载代理。这个变化将进一步提高Java平台的默认系统完整性。
2.4 密钥封装机制API
-
RSA密钥封装机制(RSA-KEM)
-
椭圆曲线集成加密方案(ECIES)等KEM算法
-
美国国家标准与技术研究院(NIST)后量子密码学标准化过程的候选算法
另一个目标是能在更高级别的协议(如传输层安全协议TLS)和密码方案(如混合公钥加密HPKE)中使用KEM。安全提供者可以用Java或本机代码实现KEM算法,并包含RFC 9180中定义的Diffie-Hellman KEM(DHKEM)的实现。
2.5 弃用Windows 32位x86端口
提案的目标是在未来的版本中移除特定端口。我们计划更新构建系统,以便在尝试为Windows 32位x86配置构建时发出错误消息。当然,你可以通过新的配置选项来屏蔽这些错误消息。另外,我们还计划将该端口及其相关功能标记为已弃用,并删除相关文档。这样做的原因是,我们注意到最后一个支持32位操作的Windows操作系统——Windows 10将于2025年10月结束生命周期。
2.6 匿名类和实例main方法预览
旨在使Java语言进化,以便学生在无需理解面向大型程序设计的语言特性的情况下编写第一个Java程序。学生可以为单类程序编写简化的声明,然后无缝地扩展程序以使用更高级的特性,而不是使用Java的单独方言。该提案不仅可以为Java提供平稳的入门,而且可以减少编写简单Java程序(如脚本和命令行实用程序)的麻烦。
2.7 无名模式和变量的预览
未命名模式匹配记录组件,而不声明组件的名称或类型,未命名变量可以初始化但不使用。两者都用下划线字符_表示。该提案旨在通过省略不必要的嵌套模式来改善记录模式的可读性,并通过识别必须声明但不会使用的变量来改善所有代码的可维护性。
2.8 Generational ZGC(分代式 ZGC)
主要是增加了对分代的支持,提高垃圾回收的性能,看下整体描述
To ensure a smooth succession, we will initially make Generational ZGC available alongside non-generational ZGC. The
-XX:+UseZGCcommand-line option will select non-generational ZGC; to select Generational ZGC, add the-XX:+ZGenerationaloption:
使用命令行选项 -XX:+UseZGC 将选择非分代式 ZGC;要选择分代式 ZGC,需要添加 -XX:+ZGenerational 选项。
$ java -XX:+UseZGC -XX:+ZGenerational ...
In a future release we intend to make Generational ZGC the default, at which point
-XX:-ZGenerationalwill select non-generational ZGC. In an even later release we intend to remove non-generational ZGC, at which point theZGenerationaloption will become obsolete.
要使用ZGC,你可以在命令行选项中添加-XX:+UseZGC。默认情况下,它是非分代式的GC。如果想要使用分代式的ZGC,则需要将命令改为$ java -XX:+UseZGC -XX:+ZGenerational。而在未来的版本中,分代GC将成为默认设置。
旨在通过为年轻对象和旧对象维护独立的代来改善应用程序性能。年轻对象往往很快就会死亡;维护独立的代将允许ZGC更频繁地收集年轻对象。运行在分代ZGC上的应用程序应会看到以下好处:分配中断风险更低,需要的堆内存开销更低,垃圾收集CPU开销更低。这些好处应该可以在吞吐量不明显下降的情况下实现。
2.9 Record Patterns (记录模式)
这个更新主要简化了类型判断与赋值的使用,类型判断后无需显式强制转换且如果模式匹配,变量被初始化为要匹配的模板值, 这个说起来比较拗口,结合代码大家理解下,我感觉还是挺有用的,这里我把JDK8 JDK17 JDK21 的实现进行一个对比,大家就明白了。
// As of Java 8
record Point(int x, int y) {}
static void printSum(Object obj) {
if (obj instanceof Point) {
Point p = (Point) obj;
int x = p.x();
int y = p.y();
System.out.println(x+y);
}
}
// As of Java 16
record Point(int x, int y) {}
static void printSum(Object obj) {
if (obj instanceof Point p) {
int x = p.x();
int y = p.y();
System.out.println(x+y);
}
}
// As of Java 21
static void printSum(Object obj) {
if (obj instanceof Point(int x, int y)) {
System.out.println(x+y);
}
}
记录模式和类型模式可以嵌套,以启用强大的、声明性的和可组合的数据导航和处理形式。该提案的目标包括扩展模式匹配以解构记录类的实例,添加嵌套模式以启用更可组合的数据查询。此特性与switch表达式和语句的模式匹配(见下文)共同演化。当前的JEP将在继续的经验和反馈的基础上通过进一步完善来最终确定该特性。除了少量编辑变化外,主要变化是删除了记录模式在增强的for语句标题中出现的支持。该特性可能会在未来的JEP中重新提出。
2.10 Pattern Matching for switch (switch模式匹配)
switch 的模式匹配可以与Record Patterns结合使用 允许在任何对象上制定 switch 语句和表达式。看一下代码例子:
static String formatterPatternSwitch(Object obj) {
return switch (obj) {
case Integer i -> String.format("int %d", i);
case Long l -> String.format("long %d", l);
case Double d -> String.format("double %f", d);
case String s -> String.format("String %s", s);
case Position(int x, int y) -> String.format("String %s,String %s", x,y);
default -> obj.toString();
};
}
同时当编译器判断所有分支都已涵盖时,switch不再需要分支default,如下面的代码
void flyJava21(Direction direction) {
switch (direction) {
case CompassDirection.NORTH -> System.out.println("Flying north");
case CompassDirection.SOUTH -> System.out.println("Flying south");
case CompassDirection.EAST -> System.out.println("Flying east");
case CompassDirection.WEST -> System.out.println("Flying west");
case VerticalDirection.UP -> System.out.println("Gaining altitude");
case VerticalDirection.DOWN -> System.out.println("Losing altitude");
}
}
使得switch表达式或语句可以针对许多模式进行测试,每个模式都有特定的操作,这样复杂的数据查询可以安全简洁地表达。
该特性最初在JDK 17中提出,之后在JDK 18、JDK 19和JDK 20中进行了完善。它将在JDK 21中通过进一步的优化最终确定。与前面的JEP相比,主要变化是删除了带括号的模式并允许合格的enum常量,如带switch表达式和语句的常量。目标包括通过允许模式出现在case标签中来扩展switch表达式和语句的表达能力和适用范围,允许switch的历史 null敌意在需要时得到放松,并通过要求模式switch语句覆盖所有潜在的输入值来增加switch语句的安全性。另一个目标是确保现有的switch表达式和语句继续编译而不变,并具有相同的语义。
2.11 向量API的第六个孵化器
该API表达了在支持的CPU体系结构上可靠编译为优化向量指令的向量计算,其性能优于等效的标量计算。向量API此前在JDK 16至JDK 20中进行了孵化。这个最新版本包括性能增强和错误修复。该提案的目标包括清晰简洁,与平台无关,并在x64和AArch64体系结构上提供可靠的运行时编译和性能。其他目标包括在向量计算无法完全表示为向量指令序列时优雅降级。
2.12 外部函数和内存API的第三次预览
使得Java程序能够与Java运行时之外的代码和数据进行互操作。它通过高效调用外部函数和安全访问外部内存,使得Java程序能够调用本机库并处理本机数据,而无需使用JNI(Java本机接口)带来的脆弱性和危险性。这个API之前在JDK 20和JDK 19中进行了预览。JDK 21预览中的改进包括增强布局路径,以解引用地址布局,并引入新的元素;集中管理Arena接口中本地段生命周期;提供备用的本机链接器实现以及删除VaList。该提案旨在提高易用性、性能、通用性和安全性。它的目标不是重新实现JNI,也不会对JNI进行任何改变。
2.13 虚拟线程
先看下官方对虚拟线程(Visual Threads)描述:
Today, every instance of
java.lang.Threadin the JDK is a platform thread. A platform thread runs Java code on an underlying OS thread and captures the OS thread for the code's entire lifetime. The number of platform threads is limited to the number of OS threads.A virtual thread is an instance of
java.lang.Threadthat runs Java code on an underlying OS thread but does not capture the OS thread for the code's entire lifetime. This means that many virtual threads can run their Java code on the same OS thread, effectively sharing it. While a platform thread monopolizes a precious OS thread, a virtual thread does not. The number of virtual threads can be much larger than the number of OS threads.Virtual threads are a lightweight implementation of threads that is provided by the JDK rather than the OS. They are a form of user-mode threads, which have been successful in other multithreaded languages (e.g., goroutines in Go and processes in Erlang). User-mode threads even featured as so-called "green threads" in early versions of Java, when OS threads were not yet mature and widespread. However, Java's green threads all shared one OS thread (M:1 scheduling) and were eventually outperformed by platform threads, implemented as wrappers for OS threads (1:1 scheduling). Virtual threads employ M:N scheduling, where a large number (M) of virtual threads is scheduled to run on a smaller number (N) of OS threads.
以前Java中的线程是基于操作系统线程的平台线程,按照1:1的模式调度,这导致线程的创建和执行都非常耗资源,并且受系统限制。而现在的虚拟线程则是由JDK提供,可以将其视为在平台线程基础上创建的一批线程,它们有效地共享所属的平台线程即操作系统线程的资源,从而提高系统利用率,并且没有数量限制。
目标描述:
1、使采用简单的按请求开启线程方式编写的服务器应用程序能够以接近最佳的硬件利用率进行扩展。
可以每个请求开启一个虚拟线程,实现简单直接的同时可以最大程度地提升硬件利用率;
2、使使用
java.lang.ThreadAPI的现有代码能够以最小的改动采用虚拟线程。之前的多线程实现代码可以在很小的修改下迁移到虚拟线程;
3、使用现有JDK工具方便地进行虚拟线程的故障排除、调试和分析。
使用现有JDK工具可以轻松地对虚拟线程进行故障排除、调试和分析;
简而言之,现在我们可以轻松地创建一个轻量级的虚拟线程,实现简单性,同时充分发挥硬件性能。
以下是一个简单的示例代码:
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
IntStream.range(0, 10000).forEach(i -> {
executor.submit(() -> {
Thread.sleep(Duration.ofSeconds(1));
return i;
});
});
} // executor.close() is called implicitly, and waits
轻量级线程,它承诺大大减少编写、维护和观察高吞吐量并发应用程序的工作量。该计划的目标包括使按线程请求风格编写的服务器应用程序能够在接近最佳硬件利用率的情况下扩展,使使用lang.Thread API的现有代码通过最小更改采用虚拟线程,并使用当前JDK工具轻松调试和分析虚拟线程。虚拟线程在JDK 20和JDK 19中进行了预览,将在JDK 21中最终确定。在JDK 21中,虚拟线程现在始终支持线程本地变量,并使创建不具有这些变量的虚拟线程成为不可能。保证对线程本地变量的支持可以确保更多现有库可以不变地与虚拟线程一起使用,并帮助将面向任务的代码迁移到使用虚拟线程。
2.14 序列集合SequencedCollection Interface(顺序集合 接口)
兄弟们,作为一个天天CRUD,CPU跑不满20%的程序员, 相比上面的虚拟线程,这次关于集合类接口的更新我感觉更实在一些
JDK21中我们常用的Set、List、Deque与Map集合类分别继承实现了SequencedCollection、 SequencedMap 接口,为我们执行一些顺序性操作比如获取头尾值提供了各类接口方法
继承关系如下图所示:
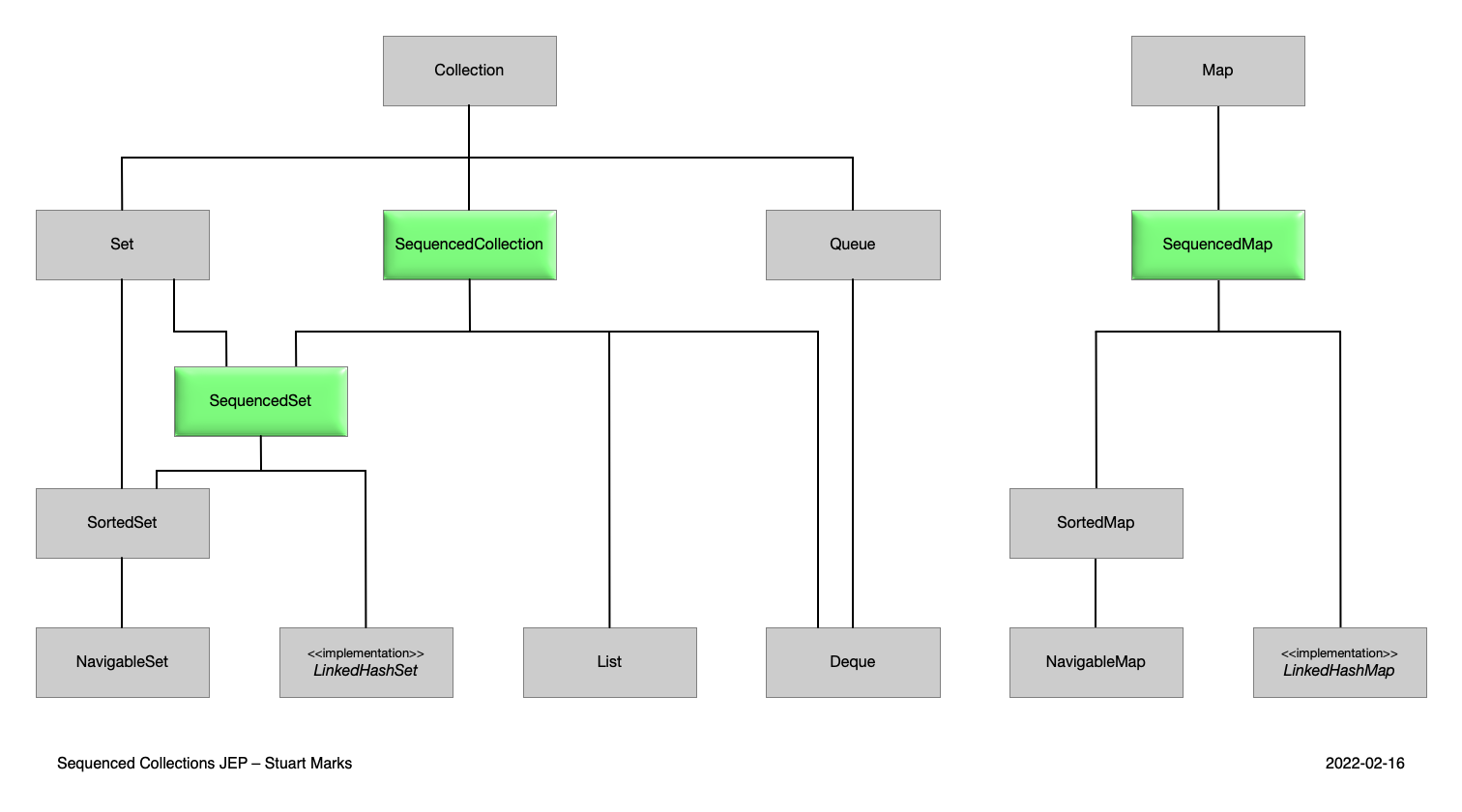
接口定义如下
interface SequencedCollection<E> extends Collection<E> {
// new method
SequencedCollection<E> reversed();
// methods promoted from Deque
void addFirst(E);
void addLast(E);
E getFirst();
E getLast();
E removeFirst();
E removeLast();
}
interface SequencedSet<E> extends Set<E>, SequencedCollection<E> {
SequencedSet<E> reversed(); // covariant override
}
interface SequencedMap<K,V> extends Map<K,V> {
// new methods
SequencedMap<K,V> reversed();
SequencedSet<K> sequencedKeySet();
SequencedCollection<V> sequencedValues();
SequencedSet<Entry<K,V>> sequencedEntrySet();
V putFirst(K, V);
V putLast(K, V);
// methods promoted from NavigableMap
Entry<K, V> firstEntry();
Entry<K, V> lastEntry();
Entry<K, V> pollFirstEntry();
Entry<K, V> pollLastEntry();
}
2.15 字符串模板
JDK 21中的预览功能,它通过将字面文本与嵌入式表达式和处理器结合来补充Java的现有字符串文本块,以产生特定结果。这种语言特性和API旨在通过使动态计算的值易于表示字符串来简化Java程序的编写。它有望增强表达式的可读性,提高程序安全性,保持灵活性,并简化使用以非Java语言编写的字符串的API。启用从字面文本和嵌入式表达式组合派生非字符串表达式的开发也是一个目标。
与这些JDK增强提案分开,据Oracle的Java团队称,JDK 21将更改JDK在Windows上为网络接口分配名称的方式。执行网络多播或使用java.net.NetworkInterface API的应用程序维护人员应注意此更改。
JDK历史上为Windows上的网络接口合成名称。这已更改为使用Windows操作系统分配的名称。此更改可能会影响使用NetworkInterface.GetbyName(String name)方法查找网络接口的代码。JDK 21还将在JDK飞行记录器中进行关键更改,包括使从命令行分析飞行记录更加容易。
总结
以上是我认为JDK21版本中一些有价值的更新的总结。如果你希望进一步了解,请自行查看官网https://openjdk.org/projects/jdk/21/,并在发布后进行实际验证。
近年来Java受到其他各种语言的冲击,给人一种跌落神坛的感觉。因此,我想看看这次的更新是否能给Java带来一些活力。当前Java语言的下降趋势也可以说是国内IT行业兴衰起伏的一个缩影。当然,作为一个提供生产力的编程语言,整个建立在Java周边的完整、稳定、强大的生态系统仍然在适当领域发挥着重要作用,这是短时间内无法改变的。但如果你指望靠它干到退休,恐怕连那些收了你学费的培训机构也不敢这样承诺。程序员的职业寿命从来不是某种编程语言决定的。
本文由 mdnice 多平台发布














 1001
1001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









