







参考:https://blog.csdn.net/jiaoyangwm/article/details/80808235
https://blog.csdn.net/a2392008643/article/details/81781766
https://mp.weixin.qq.com/s/vn3KiV-ez79FmbZ36SX9lg
本文仅是将他人博客经个人理解转化为简明的知识点,供各位博友快速理解记忆,并非纯原创博客,如需了解详细知识点,请查看参考的各个原创博客。
目录
第一章 数据结构
1.1 数据关系

- 数据项:数据项组成数据元素,数据项是不可分割的最小单位
- 数据元素:组成数据的基本单位
- 数据对象:性质相同的数据元素的集合
- 数据:描述客观事物的符号
数据结构:相互之间存在一种或多种特定关系的数据元素的集合
1.2 逻辑结构和物理结构
逻辑结构:数据对象中数据元素的相互关系
- 逻辑结构包括:集合结构、线性结构、树形结构、图形结构
物理结构:数据的逻辑结构在计算机中的存储形式,也就是将数据元素存储到存储器
- 物理结构包括:顺序存储结构、链式存储结构
- 顺序存储结构:把数据元素存放在地址连续的存储单元,数据间逻辑关系和物理关系是一样
- 链式存储结构:把数据元素存储到任意存储单元中,这些单元可以是连续的也可以是不连续的链式存储很灵活,不用在意存储的位置,只要有一个存放地址的指针就好了。
第二章 算法
算法是解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列。
2.1 算法特性
输入、输出、有穷性、确定性、可行性
- 输入输出:算法具有输入和输出
- 有穷性:算法不会出现无限循环,并且每个步骤可在可接受时间内完成
- 确定性:每个步骤都有确定的含义
- 可行性:算法的每一步都是可行的,也就是每一步都能够通过执行的有限次完成
2.2 算法设计要求
- 正确性、可读性、健壮性、时间效率高、存储量低
2.3 算法时间复杂度
背景:一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。
时间频度:一个算法中的语句执行次数称为语句频度或时间频度,记为T(n)。
时间复杂度:时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。但有时我们想知道它变化时呈现什么规律。为此,我们引入时间复杂度概念。若有某个辅助函数f(n),存在一个正常数c使得fn*c>=T(n)恒成立,记作T(n)=O(f(n)),则称O(f(n)) 为算法的时间复杂度。
通常来说,时间复杂度的分析方法有5种方法,分别如下:
1)直接看嵌套层数
例如外层循环n次,内层循环m次,时间复杂度即为O(nm)。
2)级数嵌套求和
除了直接看嵌套层数,还可用级数嵌套求和的方式(适合嵌套变量相关的情况)
for(int i = 1; i <= n; i++)
for(int j = 1; j <= i; j++
for(int k = 1; k <= j; k++)
x = x + 1;从语句频度推导出时间复杂度的全过程:
3)对数级复杂度

4)时间复杂度会随输入数据集变化

5)T(n)分解估算

2.4 算法空间复杂度
空间复杂度是对一个算法在运行过程中临时占用存储空间大小的量度,记做S(n)=O(f(n))。
S(n)与辅助变量的个数有关:

第三章 线性表
线性表(List):由同类型数据元素构成有序序列的线性结构。
元素之间是有顺序的:第一个元素无前驱,最后一个元素无后继,其他元素都有前驱和后继
线性表是有限的
线性表可以利用数组来实现(顺序存储结构),也可以用链表来实现(链式存储结构)。
3.1 线性表的顺序存储结构
顺序存储结构:用一段地址连续的存储单元一次存储线性表的数据元素
顺序存储结构的三个属性:
- 存储空间的起始位置:数组data,它的存储位置就是存储空间的起始位置
- 线性表的最大存储容量:数组长度MaxSize
- 线性表的当前长度:length
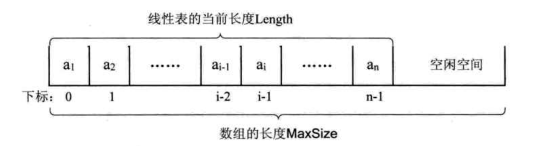
顺序存储结构中
- 查找元素的时间复杂度为O(1)
- 插入元素的平均时间复杂度为O(n)。插入最后一个位置时间复杂度为O(1),插入第一个位置时间复杂度为O(n)
- 删除元素的平均时间复杂度为O(n)。删除最后一个位置时间复杂度为O(1),删除第一个位置时间复杂度为O(n)
3.2 线性表的链式存储结构
链式存储结构:用一组任意的存储单元存储线性表的数据元素。(这组存储单元可以是连续的,也可以是不连续的,即这些数据元素可以存在内存中未被占用的任意位置)
链式存储结构中的每个结点包含:存储数据元素信息的域(数据域)+存储后继元素地址的域(指针域)
- 单链表:每个结点只包含一个指针域的线性链表
- 双向链表:每个结点包含两个指针域,分别指向直接前驱和直接后继
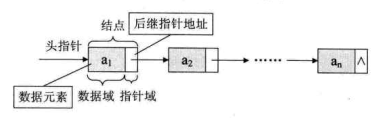
- 头指针:头指针是指向链表第一个结点的存储位置的指针,其是链表的必要元素。
- 头结点:第一个结点前设一个结点,可以不存储任何信息,也可以存储长度等附加信息,其是为了操作的统一和方便而设置的,不是链表的必要元素。

在链式存储结构中:
- 查找元素,需要从头开始找,直到第i个元素未知,时间复杂度为O(n)
- 插入和删除元素,只需要简单改变结点的后继即可,时间复杂度为O(1)
注:无论是顺序结构还是链式结构(逻辑结构),都可以用数组和链表(物理结构)来实现。两者的特点如下:
数组的特点:数组将元素在内存中连续存放,由于每个元素占用内存相同,可以通过下标迅速访问数组中任何元素(内存地址固定累加),也就是说,它的随机查找效率很高,但插入、删除效率低。同时,数组需要预留空间,在使用前要先申请占内存的大小,可能会浪费内存空间。并且数组不利于扩展,数组定义的空间不够时要重新定义数组。
//声明并初始化一个一维数组
int arr1[m];
memset(arr1, 0, m);
//声明一个多维数组
int arr2[m][n][k];
int *arr3 = new int[m][n][k];链表的特点:链表的元素在内存中任意存放,通过存在元素中的指针联系到一起。其插入和删除效率高,查找元素效率低。同时,链表不用指定大小,扩展方便,内存利用率高。
//声明链表结点结构体
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};
//创建一个结点
ListNode* node = new ListNode(1);3.3 相关面试题
Q:数组和链表的区别?
A:如上所述。
Q:有什么方法能结合数组和链表的优点?
A:哈希表是数组和链表的折中方案,增加,删除,改写数据的复杂度平均都是O(1),效率非常高。
Q:如何防止数组越界?
A:1)检查传入参数的合法性;2)传参时把数组和数组长度一起传;3)打印数组索引方便检查;4)使用异常捕获。
Q:判断两个链表是否相交?
A:链表相交之后,后面的部分节点全部共用,可以用2个指针分别从这两个链表头部走到尾部,最后判断尾部指针的地址信息是否一样,若一样则代表链表相交。
Q:找出相交链表开始相交的结点?
A:首先计算出两个链表的长度,然后设置两个指针分别指向两个链表,让指向长链表的指针先走长度的差值步(长链长度-短链长度),此后两个指针一起走,直到找到相等的节点。
Q:判断单链表是否有环?
A:定义快慢指针,同时从链表的头结点出发,快指针每次走两步,慢指针每次走一步。如果快指针和慢指针相遇,则链表有环。此时,若要找出入环结点,可以在相遇后令快指针回到头结点,两个指针每次均走一步,第二次相遇的结点即为入环的第一个结点。
Q:给定一个链表的头指针和结点指针,用O(1)时间删除它?
A:用下一个节点数据覆盖要删除的节点,然后删除下一个节点。但是如果节点是尾节点时,该方法就行不通了。
第四章 栈、队列和堆
- 栈是限定仅在表尾进行插入和删除操作的线性表
- 队列是只允许在一端进行插入操作、而在另一端进行删除操作的线性表
- 堆(Heap)是计算机科学中一类特殊的数据结构的统称,其通常是一个可以被看做一棵完全二叉树的数组对象。
4.1 栈的定义
栈是一种后进先出的线性表(LIFO),栈顶是允许插入和删除的一端,栈底不允许任何操作。其包含的操作有:进栈和出栈。
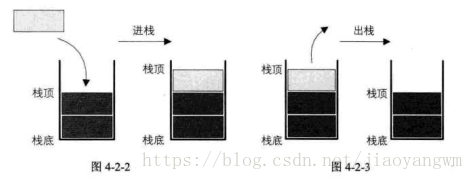
4.2 队列的定义
队列是一种先进先出的线性表的线性表(FIFO),队头是允许删除的一端,队尾是允许插入的一端。

双向队列
双向队列,顾名思义就是队列头尾均可以操作的队列,它允许在容器头部快速插入和删除,C++中使用deque来表示。
优先队列
优先队列中,元素被赋予优先级,当删除元素时,具有最高优先级的元素最先删除,即具有最高级先出 (First In, Largest Out)的特点。
//升序队列,小顶堆
priority_queue <int,vector<int>,greater<int>> q;
//降序队列,大顶堆
priority_queue<int> a; //写法一
priority_queue <int,vector<int>,less<int>>q; //写法二
4.3 堆的定义
堆是一棵具有特定性质的完全二叉树,它满足堆中所有结点大于等于(或小于等于)其孩子结点的基本特性。

4.4 相关面试题
Q:栈的溢出
A:栈溢出是指程序向栈中某个变量写入的字节数超过了这个变量本身所申请的字节数,因而导致栈中与其相邻的变量的值被改变。
原因:
1)局部数组过大。局部变量是存储在栈中的,当函数内部的数组过大时,有可能导致堆栈溢出。
2)递归调用层次太多。递归函数在运行时会执行压栈操作,当压栈次数太多时,也会导致堆栈溢出。
3)指针或数组越界。
Q:堆和栈的区别
A:
1)申请方式:栈由系统自动分配和管理,堆由程序员手动分配和管理。
2)效率:栈由系统分配,计算机底层对栈提供了一系列支持:分配专门的寄存器存储栈的地址,压栈和入栈有专门的指令执行,因此,其速度快,不会有内存碎片;堆由程序员分配,堆是由C/C++函数库提供的,机制复杂,需要一些列分配内存、合并内存和释放内存的算法,因此效率较低,可能由于操作不当产生内存碎片。
3)扩展方向:栈从高地址向低地址进行扩展,堆由低地址向高地址进行扩展。
4)程序局部变量是使用的栈空间,new/malloc动态申请的内存是堆空间;同时,函数调用时会进行形参和返回值的压栈出栈,也是用的栈空间。
第五章 串
- 串是由零个或多个字符组成的有限序列,又称字符串。
串这个数据结构本身没什么好讲的,而关于串的算法面试题很多,参见:https://github.com/CyC2018/CS-Notes/blob/master/notes/Leetcode%20%E9%A2%98%E8%A7%A3%20-%20%E5%AD%97%E7%AC%A6%E4%B8%B2.md
第六章 树
树是n个结点的有限集(n=0时,称为空树),在任意一颗非空树中:
- 有且仅有一个根结点(Root)
- 当n>1时,其余结点可分为m个互不相交的有限集合,其中每个集合本身又是一棵树,并且称为根的子树(Subtree)
6.1 树的定义
1、树的度
树的结点包含一个数据元素及若干个指向其子树的分支,结点拥有的子树数量称为结点的度。
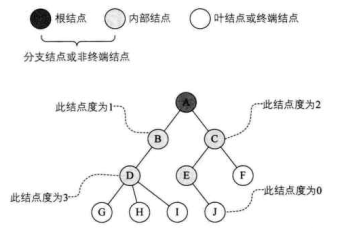
2、树结点间的关系
树中结点的关系包括:双亲、兄弟、孩子,下面用一张图简明表达:
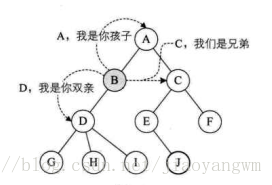
3、树的层次
树中有深度和高度两种定义,深度定义是从上往下的,高度定义是从下往上的。(此处约定深度和高度均从1开始,空树为0)
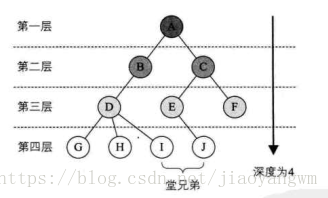
6.2 二叉树的定义
二叉树(Binary tree)是n个结点的有限集合(该集合或为空集),由一个根节点和两棵互不相交、分别称为根节点的左子树和右子树的二叉树组成,二叉树中不存在度大于2的结点。
6.2.1 特殊二叉树
1、斜二叉树
所有结点都只有左子树的二叉树叫左斜树,所有结点都只有右子树的二叉树叫右斜树。
2、满二叉树
所有分支节点都存在左子树和右子树,并且所有叶子都在同一层上的二叉树。
3、完全二叉树
高度为h的二叉树,除了h层外其余层次的结点数均达到最大,且h层的所有结点都连续集中在最左边。
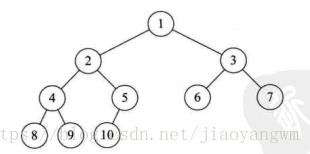
6.2.2 二叉树的重要性质</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5275
5275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









