






 本文档介绍了一个使用TensorFlow.js在前端进行手写数字识别的项目。通过加载mnist_images.png精灵图和mnist_labels_unit8标签文件,创建MnistData对象,并利用TensorFlow.js训练模型。在训练完成后,用户可以在canvas上手写数字,模型会进行识别。项目包含index.html、data.js、script.js等文件,详细解释了每个部分的代码和功能。
本文档介绍了一个使用TensorFlow.js在前端进行手写数字识别的项目。通过加载mnist_images.png精灵图和mnist_labels_unit8标签文件,创建MnistData对象,并利用TensorFlow.js训练模型。在训练完成后,用户可以在canvas上手写数字,模型会进行识别。项目包含index.html、data.js、script.js等文件,详细解释了每个部分的代码和功能。
gitee仓库地址:李平/tensorflow.js
文件名称:tensorflow-js-2.1
1、项目结构
index.html 页面
data.js 用于分割精灵图
script.js js代码
mnist_images.png 手写数字的精灵图
mnist_labels_unit8 精灵图的标签
tf.min.js tfjs-vis.umd.min.js tf的依赖
2、html文件代码
1、引入TensorFlow.js的依赖
<script src="tf.min.js"></script>
<script src="tfjs-vis.umd.min.js"></script>2、引入我们写的js
<script src="data.js"></script>
<script src="script.js"></script>3、页面内容
在页面上放一个canvas、img、两个按钮,等训练结束后,用这个canvas手写数字,保存到img上,用来识别我们的训练结果是否准确。
<div>
<canvas id="canvas" width="280" height="280" style="position:absolute;top:100px;left:100px;border:8px solid;"></canvas>
<img id="canvasimg" style="position:absolute;top:10%;left:52%;width:280px;height:280px;display:none;">
<input type="button" value="识别" id="sb" size="48" style="position:absolute;top:400px;left:100px;">
<input type="button" value="清除" id="cb" size="23" style="position:absolute;top:400px;left:180px;">
</div>4、完整的html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js 识别手写文字</title>
<script src="tf.min.js"></script>
<script src="tfjs-vis.umd.min.js"></script>
<script src="data.js"></script>
<script src="script.js"></script>
</head>
<body>
<div>
<canvas id="canvas" width="280" height="280" style="position:absolute;top:100px;left:100px;border:8px solid;"></canvas>
<img id="canvasimg" style="position:absolute;top:10%;left:52%;width:280px;height:280px;display:none;">
<input type="button" value="识别" id="sb" size="48" style="position:absolute;top:400px;left:100px;">
<input type="button" value="清除" id="cb" size="23" style="position:absolute;top:400px;left:180px;">
</div>
</body>
</html>
3、data.js
这个文件包含了 Minsdata类,而这个类可以帮助我们从经络图的数据集中获取到任意的一些。
这个文件中引入了精灵图和标签文件,因为网络的原因,我将这两个文件下载到了本地项目中。
const IMAGE_SIZE = 784;
const NUM_CLASSES = 10;
const NUM_DATASET_ELEMENTS = 65000;
const TRAIN_TEST_RATIO = 5 / 6;
const NUM_TRAIN_ELEMENTS = Math.floor(TRAIN_TEST_RATIO * NUM_DATASET_ELEMENTS);
const NUM_TEST_ELEMENTS = NUM_DATASET_ELEMENTS - NUM_TRAIN_ELEMENTS;
const MNIST_IMAGES_SPRITE_PATH ='./mnist_images.png';
// 'https://storage.googleapis.com/learnjs-data/model-builder/mnist_images.png';
const MNIST_LABELS_PATH ='./mnist_labels_uint8';
// 'https://storage.googleapis.com/learnjs-data/model-builder/mnist_labels_uint8';
/**
* A class that fetches the sprited MNIST dataset and returns shuffled batches.
*
* NOTE: This will get much easier. For now, we do data fetching and
* manipulation manually.
*/
class MnistData {
constructor() {
this.shuffledTrainIndex = 0;
this.shuffledTestIndex = 0;
}
async load() {
// Make a request for the MNIST sprited image.
const img = new Image();
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const imgRequest = new Promise((resolve, reject) => {
img.crossOrigin = '';
img.onload = () => {
img.width = img.naturalWidth;
img.height = img.naturalHeight;
const datasetBytesBuffer =
new ArrayBuffer(NUM_DATASET_ELEMENTS * IMAGE_SIZE * 4);
const chunkSize = 5000;
canvas.width = img.width;
canvas.height = chunkSize;
for (let i = 0; i < NUM_DATASET_ELEMENTS / chunkSize; i++) {
const datasetBytesView = new Float32Array(
datasetBytesBuffer, i * IMAGE_SIZE * chunkSize * 4,
IMAGE_SIZE * chunkSize);
ctx.drawImage(
img, 0, i * chunkSize, img.width, chunkSize, 0, 0, img.width,
chunkSize);
const imageData = ctx.getImageData(0, 0, canvas.width, canvas.height);
for (let j = 0; j < imageData.data.length / 4; j++) {
// All channels hold an equal value since the image is grayscale, so
// just read the red channel.
datasetBytesView[j] = imageData.data[j * 4] / 255;
}
}
this.datasetImages = new Float32Array(datasetBytesBuffer);
resolve();
};
img.src = MNIST_IMAGES_SPRITE_PATH;
});
const labelsRequest = fetch(MNIST_LABELS_PATH);
const [imgResponse, labelsResponse] =
await Promise.all([imgRequest, labelsRequest]);
this.datasetLabels = new Uint8Array(await labelsResponse.arrayBuffer());
// Create shuffled indices into the train/test set for when we select a
// random dataset element for training / validation.
this.trainIndices = tf.util.createShuffledIndices(NUM_TRAIN_ELEMENTS);
this.testIndices = tf.util.createShuffledIndices(NUM_TEST_ELEMENTS);
// Slice the the images and labels into train and test sets.
this.trainImages =
this.datasetImages.slice(0, IMAGE_SIZE * NUM_TRAIN_ELEMENTS);
this.testImages = this.datasetImages.slice(IMAGE_SIZE * NUM_TRAIN_ELEMENTS);
this.trainLabels =
this.datasetLabels.slice(0, NUM_CLASSES * NUM_TRAIN_ELEMENTS);
this.testLabels =
this.datasetLabels.slice(NUM_CLASSES * NUM_TRAIN_ELEMENTS);
}
nextTrainBatch(batchSize) {
return this.nextBatch(
batchSize, [this.trainImages, this.trainLabels], () => {
this.shuffledTrainIndex =
(this.shuffledTrainIndex + 1) % this.trainIndices.length;
return this.trainIndices[this.shuffledTrainIndex];
});
}
nextTestBatch(batchSize) {
return this.nextBatch(batchSize, [this.testImages, this.testLabels], () => {
this.shuffledTestIndex =
(this.shuffledTestIndex + 1) % this.testIndices.length;
return this.testIndices[this.shuffledTestIndex];
});
}
nextBatch(batchSize, data, index) {
const batchImagesArray = new Float32Array(batchSize * IMAGE_SIZE);
const batchLabelsArray = new Uint8Array(batchSize * NUM_CLASSES);
for (let i = 0; i < batchSize; i++) {
const idx = index();
const image =
data[0].slice(idx * IMAGE_SIZE, idx * IMAGE_SIZE + IMAGE_SIZE);
batchImagesArray.set(image, i * IMAGE_SIZE);
const label =
data[1].slice(idx * NUM_CLASSES, idx * NUM_CLASSES + NUM_CLASSES);
batchLabelsArray.set(label, i * NUM_CLASSES);
}
const xs = tf.tensor2d(batchImagesArray, [batchSize, IMAGE_SIZE]);
const labels = tf.tensor2d(batchLabelsArray, [batchSize, NUM_CLASSES]);
return {xs, labels};
}
}4、script.js
重点就是这个文件,用来加载模型,训练模型,验证结果。
1、全局变量
定义一些全局变量
classNames手写识别结果
canvas、ctx用于操作canvas,绘制鼠标点击后的轨迹图,
saveButton将手绘后的canvas保存成图片
clearButton清空canvas
rawImage手写后canvas生成的图片
pos手写时的坐标点
model TensorFlow模型
const classNames = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'];
var canvas, ctx, saveButton, clearButton, rawImage;
var pos = {x: 0, y: 0};
var model;2、文档就绪
在文档就绪后,我们执行了run函数
document.addEventListener('DOMContentLoaded', run);3、run
函数所有代码
async function run() {
// 创建MnistData对象
const data = new MnistData();
// 等待精灵图数据加载完成
await data.load();
// 渲染部分训练集中的图片到页面上
await showExamples(data);
// 创建训练模型
model = getModel();
// 将训练过程中每个迭代的变化以表格的形式展示到页面上
tfvis.show.modelSummary({name: '模型结构', tab: '模型'}, model);
// 开始训练
await train(model, data);
// 显示训练过程图
await showAccuracy(model, data);
await showConfusion(model, data);
// 初始化手写工具
init();
alert("Training is done, try classifying your drawings!");
}1、创建MnistData对象用于加载精灵图,用的现成的方法。
// 创建MnistData对象
const data = new MnistData();
// 等待精灵图数据加载完成
await data.load();2、渲染一些训练图片到页面上
// 渲染部分训练集中的图片到页面上
await showExamples(data);
showExamples函数
async function showExamples(data) {
// Create a container in the visor
// 用tfvis创建一个tab
const surface =
tfvis.visor().surface({name: '训练数据示例', tab: '训练数据'});
// Get the examples
// 获取10个要训练的数据
const examples = data.nextTestBatch(10);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
// 创建canvas将每个数据的图像绘制出来
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
// 分割图集,将图像重塑为28*28大小的图片
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
// 将图片画到画布上
await tf.browser.toPixels(imageTensor, canvas);
// 将画布添加到visor中
surface.drawArea.appendChild(canvas);
// 销毁图片,释放内存
imageTensor.dispose();
}
}3、创建训练模型
// 创建训练模型
model = getModel();getModel函数
function getModel() {
// 创建一个线性堆叠模型
const model = tf.sequential();
// 定义图片属性 28*28
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
// 深度为 1,这是因为我们的图片只有1个颜色
const IMAGE_CHANNELS = 1;
// 给模型添加卷积层
model.add(tf.layers.conv2d({
// 这个数据的形状将回流入模型的第一层
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
// 划过卷积层过滤窗口的数量将会被应用到输入数据中去。
// 这里,我们设置了 kernalSize 的值为5,也就是指定了一个5 x 5的卷积窗口。
kernelSize: 5,
// 这个 kernelSize 的过滤窗口的数量将会被应用到输入数据中,我们这里将8个过滤器应用到数据中
filters: 8,
// 即滑动窗口每一步的步长。比如每当过滤器移动过图片时将会由多少像素的变化。
// 这里,我们指定其步长为1,这意味着每一步都是1像素的移动。
strides: 1,
// 这个 activation 函数将会在卷积完成之后被应用到数据上。
// 在这个例子中,我们应用了 relu 函数,这个函数在机器学习中是一个非常常见的激活函数。
activation: 'relu',
// 这个方法对于训练动态的模型是非常重要的,
// 他被用于任意地初始化模型的 weights。
// 我们这里将不会深入细节来讲,
// 但是 VarianceScaling (即这里用的)真的是一个初始化非常好的选择。
kernelInitializer: 'varianceScaling'
}));
// 给模型添加池化层(pooling layer)
// 这一层将会通过在每个滑动窗口中计算最大值来降频取样得到结果。
// 注意:因为 poolSize 和 strides 都是2x2,
// 所以池化层空口将会完全不会重叠。这也就意味着池化层将会把激活的大小从上一层减少一半。
model.add(tf.layers.maxPooling2d({
// 这个滑动池窗口的数量将会被应用到输入的数据中。
// 这里我们设置 poolSize为[2, 2],
// 所以这就意味着池化层将会对输入数据应用2x2的窗口。
poolSize: [2, 2],
// 这个池化层的步长大小。
// 比如,当每次挪开输入数据时窗口需要移动多少像素。
// 这里我们指定 strides为[2, 2],
// 这就意味着过滤器将会以在水平方向和竖直方向上同时移动2个像素的方式来划过图片。
strides: [2, 2]
}));
// 添加第二层卷积层
// 重复使用层结构是神经网络中的常见模式。我们添加第二个卷积层到模型
// 我们没有指定 inputShape,因为它可以从前一层的输出形状中推断出来
model.add(tf.layers.conv2d({
kernelSize: 5,
// 将滤波器数量从8增加到16。
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// 添加第二层池化层
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// 接下来,我们添加一个 flatten 层,将前一层的输出平铺到一个向量中:
model.add(tf.layers.flatten());
// 输出数量
const NUM_OUTPUT_CLASSES = 10;
// 最后,让我们添加一个 dense 层(也称为全连接层),
// 它将执行最终的分类。
// 在 dense 层前先对卷积+池化层的输出执行 flatten 也是神经网络中的另一种常见模式:
model.add(tf.layers.dense({
// 激活输出的数量。由于这是最后一层,
// 我们正在做10个类别的分类任务(数字0-9),因此我们在这里使用10个 units。
units: NUM_OUTPUT_CLASSES,
// 我们将对 dense 层使用与卷积层相同的 VarianceScaling 初始化策略。
kernelInitializer: 'varianceScaling',
// 分类任务的最后一层的激活函数通常是 softmax。
// Softmax 将我们的10维输出向量归一化为概率分布,使得我们10个类中的每个都有一个概率值。
activation: 'softmax'
}));
const optimizer = tf.train.adam();
// 为了编译模型,我们传入一个由优化器,损失函数和一系列评估指标(这里只是'精度')组成的配置对象
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}4、显示训练变化
// 将训练过程中每个迭代的变化以表格的形式展示到页面上
tfvis.show.modelSummary({name: '模型结构', tab: '模型'}, model);5、开始训练
// 开始训练
await train(model, data);train函数
async function train(model, data) {
// 为迭代回调设置以下指标 'loss', 'val_loss', 'acc', 'val_acc' 显示到页面tab上
// loss:训练集损失值
// val_loss:测试集损失值
// accuracy:训练集准确率
// val_accruacy:测试集准确率
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
// 创建一个容器,用于显示训练过程
const container = {
name: '模型训练', tab: '模型', styles: {height: '1000px'}
};
// 使用tfvis.show.fitCallbacks()设置回调。
// 使用上面定义的容器和度量作为参数。
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
// 设置训练批次数量,以及大小
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
// 获取训练批次并调整其大小
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
// 获取测试批次并调整其大小。
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
//开始训练
return model.fit(trainXs, trainYs, {
// 每个训练 batch 中包含多少个图像。之前我们在这里设置的BATCH_SIZE是 512
batchSize: BATCH_SIZE,
// 我们的评估度量(准确度)将在此数据集上计算(用测试数据来测试准确度)
validationData: [testXs, testYs],
// 迭代次数
epochs: 10,
// 是否再每轮迭代之前混洗数据
shuffle: true,
// 函数回调
callbacks: fitCallbacks
});
}6、显示训练过程
// 显示训练过程图
await showAccuracy(model, data);
await showConfusion(model, data);7、初始化canvas
// 初始化手写工具
init();init函数
function init() {
canvas = document.getElementById('canvas');
rawImage = document.getElementById('canvasimg');
ctx = canvas.getContext("2d");
ctx.fillStyle = "black";
ctx.fillRect(0, 0, 280, 280);
canvas.addEventListener("mousemove", draw);
canvas.addEventListener("mousedown", setPosition);
canvas.addEventListener("mouseenter", setPosition);
saveButton = document.getElementById('sb');
saveButton.addEventListener("click", save);
clearButton = document.getElementById('cb');
clearButton.addEventListener("click", erase);
}
8、训练结束
当浏览器弹出下图的框时,代表着训练结束,可以在页面左侧的框中用鼠标点击拖动输入数字,然后点击下面的识别,来测试模型。
alert("Training is done, try classifying your drawings!");4、完整的script.js
console.log('Hello TensorFlow');
const classNames = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'];
var canvas, ctx, saveButton, clearButton, rawImage;
var pos = {x: 0, y: 0};
var model;
async function showExamples(data) {
// Create a container in the visor
// 用tfvis创建一个tab
const surface =
tfvis.visor().surface({name: '训练数据示例', tab: '训练数据'});
// Get the examples
// 获取10个要训练的数据
const examples = data.nextTestBatch(10);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
// 创建canvas将每个数据的图像绘制出来
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
// 分割图集,将图像重塑为28*28大小的图片
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
// 将图片画到画布上
await tf.browser.toPixels(imageTensor, canvas);
// 将画布添加到visor中
surface.drawArea.appendChild(canvas);
// 销毁图片,释放内存
imageTensor.dispose();
}
}
function getModel() {
// 创建一个线性堆叠模型
const model = tf.sequential();
// 定义图片属性 28*28
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
// 深度为 1,这是因为我们的图片只有1个颜色
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
// 给模型添加卷积层
model.add(tf.layers.conv2d({
// 这个数据的形状将回流入模型的第一层
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
// 划过卷积层过滤窗口的数量将会被应用到输入数据中去。
// 这里,我们设置了 kernalSize 的值为5,也就是指定了一个5 x 5的卷积窗口。
kernelSize: 5,
// 这个 kernelSize 的过滤窗口的数量将会被应用到输入数据中,我们这里将8个过滤器应用到数据中
filters: 8,
// 即滑动窗口每一步的步长。比如每当过滤器移动过图片时将会由多少像素的变化。
// 这里,我们指定其步长为1,这意味着每一步都是1像素的移动。
strides: 1,
// 这个 activation 函数将会在卷积完成之后被应用到数据上。
// 在这个例子中,我们应用了 relu 函数,这个函数在机器学习中是一个非常常见的激活函数。
activation: 'relu',
// 这个方法对于训练动态的模型是非常重要的,
// 他被用于任意地初始化模型的 weights。
// 我们这里将不会深入细节来讲,
// 但是 VarianceScaling (即这里用的)真的是一个初始化非常好的选择。
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
// 给模型添加池化层(pooling layer)
// 这一层将会通过在每个滑动窗口中计算最大值来降频取样得到结果。
// 注意:因为 poolSize 和 strides 都是2x2,
// 所以池化层空口将会完全不会重叠。这也就意味着池化层将会把激活的大小从上一层减少一半。
model.add(tf.layers.maxPooling2d({
// 这个滑动池窗口的数量将会被应用到输入的数据中。
// 这里我们设置 poolSize为[2, 2],
// 所以这就意味着池化层将会对输入数据应用2x2的窗口。
poolSize: [2, 2],
// 这个池化层的步长大小。
// 比如,当每次挪开输入数据时窗口需要移动多少像素。
// 这里我们指定 strides为[2, 2],
// 这就意味着过滤器将会以在水平方向和竖直方向上同时移动2个像素的方式来划过图片。
strides: [2, 2]
}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
// 添加第二层卷积层
// 重复使用层结构是神经网络中的常见模式。我们添加第二个卷积层到模型
// 我们没有指定 inputShape,因为它可以从前一层的输出形状中推断出来
model.add(tf.layers.conv2d({
kernelSize: 5,
// 将滤波器数量从8增加到16。
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// 添加第二层池化层
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
// 接下来,我们添加一个 flatten 层,将前一层的输出平铺到一个向量中:
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
// 输出数量
const NUM_OUTPUT_CLASSES = 10;
// 最后,让我们添加一个 dense 层(也称为全连接层),
// 它将执行最终的分类。
// 在 dense 层前先对卷积+池化层的输出执行 flatten 也是神经网络中的另一种常见模式:
model.add(tf.layers.dense({
// 激活输出的数量。由于这是最后一层,
// 我们正在做10个类别的分类任务(数字0-9),因此我们在这里使用10个 units。
units: NUM_OUTPUT_CLASSES,
// 我们将对 dense 层使用与卷积层相同的 VarianceScaling 初始化策略。
kernelInitializer: 'varianceScaling',
// 分类任务的最后一层的激活函数通常是 softmax。
// Softmax 将我们的10维输出向量归一化为概率分布,使得我们10个类中的每个都有一个概率值。
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
// 为了编译模型,我们传入一个由优化器,损失函数和一系列评估指标(这里只是'精度')组成的配置对象
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
async function train(model, data) {
// 为迭代回调设置以下指标 'loss', 'val_loss', 'acc', 'val_acc' 显示到页面tab上
// loss:训练集损失值
// val_loss:测试集损失值
// accuracy:训练集准确率
// val_accruacy:测试集准确率
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
// 创建一个容器,用于显示训练过程
const container = {
name: '模型训练', tab: '模型', styles: {height: '1000px'}
};
// 使用tfvis.show.fitCallbacks()设置回调。
// 使用上面定义的容器和度量作为参数。
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
// 设置训练批次数量,以及大小
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
// 获取训练批次并调整其大小
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
// 获取测试批次并调整其大小。
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
//开始训练
return model.fit(trainXs, trainYs, {
// 每个训练 batch 中包含多少个图像。之前我们在这里设置的BATCH_SIZE是 512
batchSize: BATCH_SIZE,
// 我们的评估度量(准确度)将在此数据集上计算(用测试数据来测试准确度)
validationData: [testXs, testYs],
// 迭代次数
epochs: 10,
// 是否再每轮迭代之前混洗数据
shuffle: true,
// 函数回调
callbacks: fitCallbacks
});
}
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: '准确度', tab: '训练结果'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: '混淆矩阵', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
function draw(e) {
if (e.buttons != 1) return;
ctx.beginPath();
ctx.lineWidth = 24;
ctx.lineCap = 'round';
ctx.strokeStyle = 'white';
ctx.moveTo(pos.x, pos.y);
setPosition(e);
ctx.lineTo(pos.x, pos.y);
ctx.stroke();
rawImage.src = canvas.toDataURL('image/png');
}
function setPosition(e) {
pos.x = e.clientX - 100;
pos.y = e.clientY - 100;
}
function save() {
var raw = tf.browser.fromPixels(rawImage, 1);
var resized = tf.image.resizeBilinear(raw, [28, 28]);
var tensor = resized.expandDims(0);
var prediction = model.predict(tensor);
var pIndex = tf.argMax(prediction, 1).dataSync();
console.log('写下了:', pIndex, classNames[pIndex])
}
function erase() {
ctx.fillStyle = "black";
ctx.fillRect(0, 0, 280, 280);
}
function init() {
canvas = document.getElementById('canvas');
rawImage = document.getElementById('canvasimg');
ctx = canvas.getContext("2d");
ctx.fillStyle = "black";
ctx.fillRect(0, 0, 280, 280);
canvas.addEventListener("mousemove", draw);
canvas.addEventListener("mousedown", setPosition);
canvas.addEventListener("mouseenter", setPosition);
saveButton = document.getElementById('sb');
saveButton.addEventListener("click", save);
clearButton = document.getElementById('cb');
clearButton.addEventListener("click", erase);
}
async function run() {
// 创建MnistData对象
const data = new MnistData();
// 等待精灵图数据加载完成
await data.load();
// 渲染部分训练集中的图片到页面上
await showExamples(data);
// 创建训练模型
model = getModel();
// 将训练过程中每个迭代的变化以表格的形式展示到页面上
tfvis.show.modelSummary({name: '模型结构', tab: '模型'}, model);
// 开始训练
await train(model, data);
// 显示训练过程图
await showAccuracy(model, data);
await showConfusion(model, data);
// 初始化手写工具
init();
alert("Training is done, try classifying your drawings!");
}
// 文档就绪函数
document.addEventListener('DOMContentLoaded', run);
5、结果展示
训练中
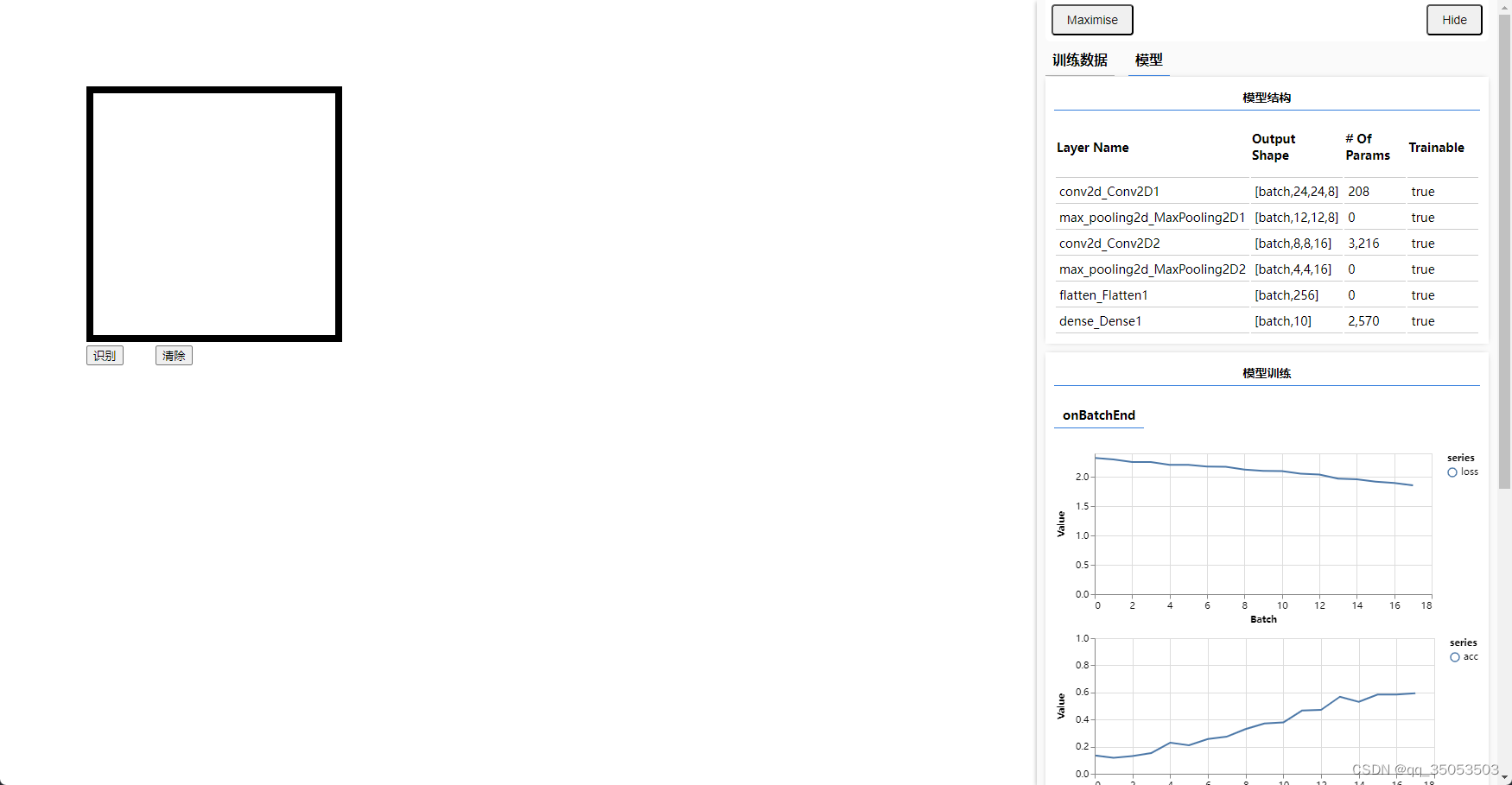
训练结束

输入手写数字并识别
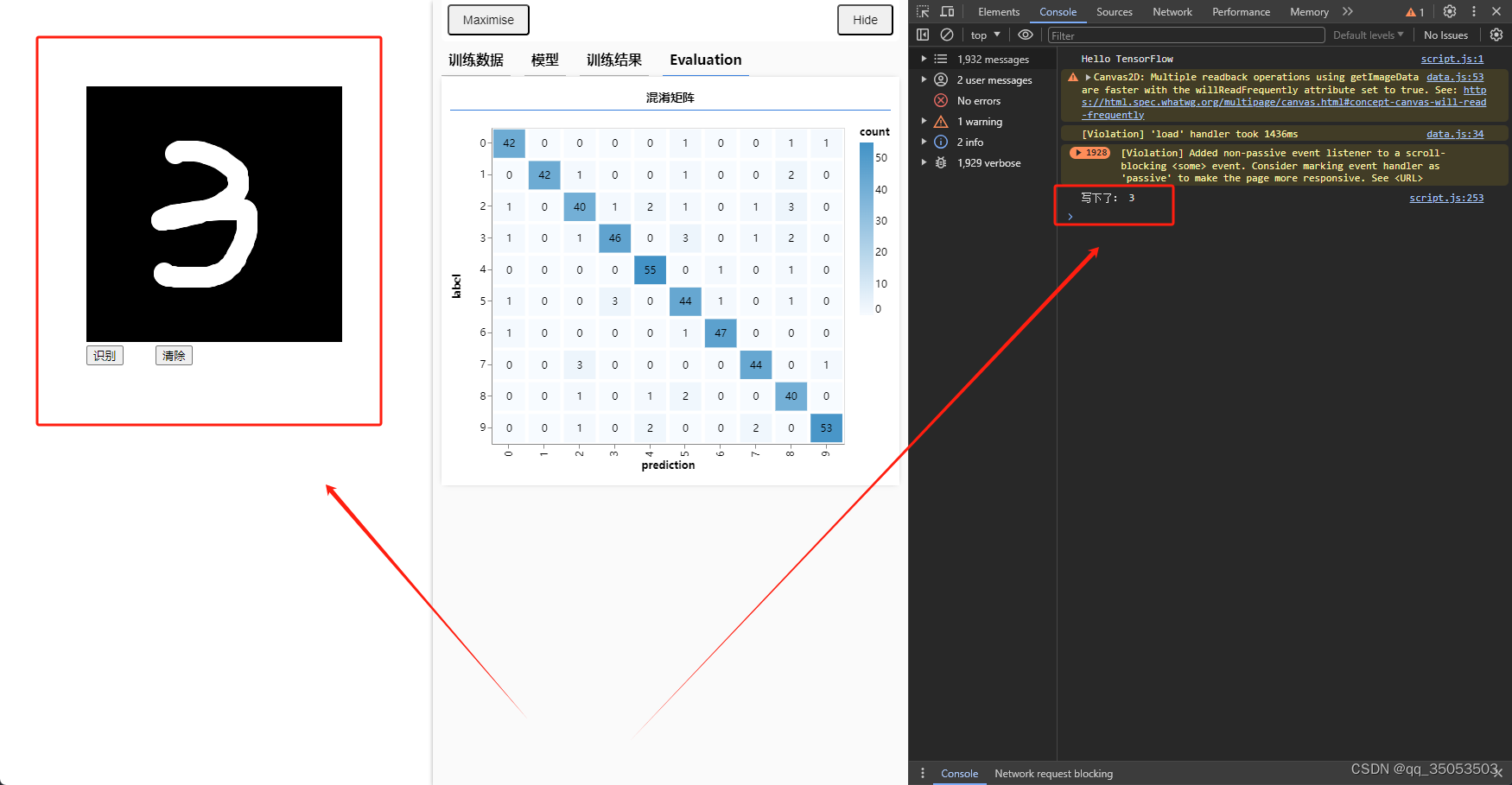
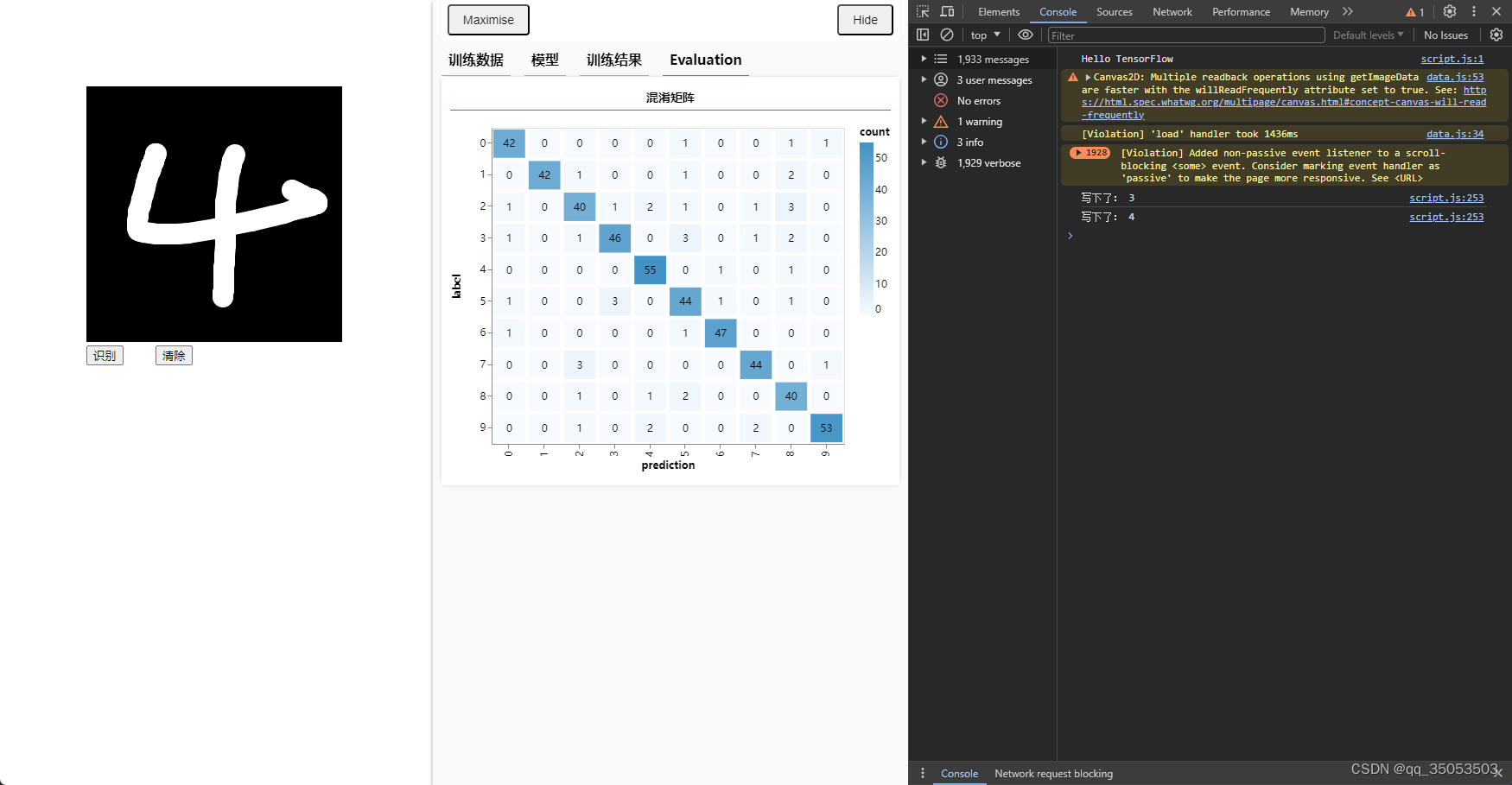

















 378
378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









