









 博主在训练深度学习模型时遇到GPU显存占用高但利用率低的问题,发现是由于数据预处理(padding)导致的。通过查看`DataLoader`源码,确认在每次迭代时会调用`collate_fn`进行padding。尝试预先处理所有数据并未改善速度。最终,发现真正的原因是训练过程中频繁调用`gc.collect()`进行垃圾回收,这成为了性能瓶颈。移除`gc.collect()`后,训练速度显著提升,实现了GPU资源的有效利用。
博主在训练深度学习模型时遇到GPU显存占用高但利用率低的问题,发现是由于数据预处理(padding)导致的。通过查看`DataLoader`源码,确认在每次迭代时会调用`collate_fn`进行padding。尝试预先处理所有数据并未改善速度。最终,发现真正的原因是训练过程中频繁调用`gc.collect()`进行垃圾回收,这成为了性能瓶颈。移除`gc.collect()`后,训练速度显著提升,实现了GPU资源的有效利用。
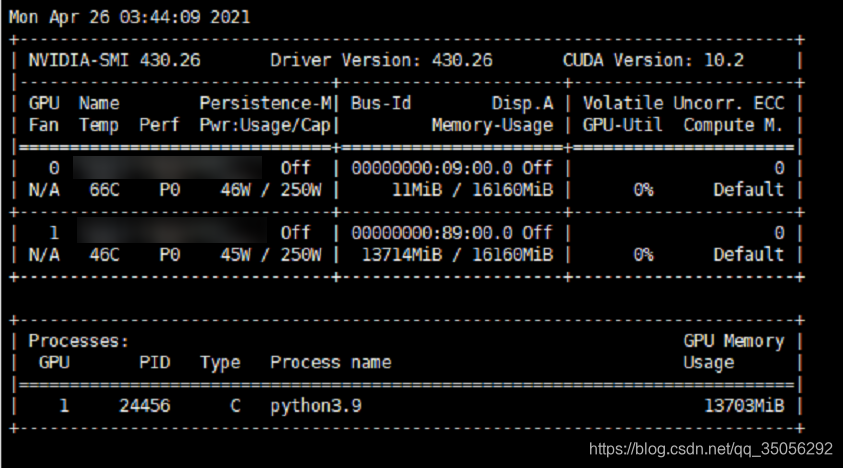
今天在训练模型的时候,发现GPU的显存都快满了,但是GPU的利用率很低,基本是隔几秒才会到100%,然后马上恢复为0。
如下图所示。训完一个epoch要一天左右,心态都给我整崩了
在网上找到了一些不错的资料:
- 训练效率低?GPU利用率上不去?快来看看别人家的tricks吧~
- 深度学习PyTorch,TensorFlow中GPU利用率较低,CPU利用率很低,且模型训练速度很慢的问题总结与分析
- GPU: high memory usage, low GPU volatile-util
猜测在train函数中,在cpu上运行的时间太长了,毕竟我是确实看到有那么一瞬间GPU的利用率很高的。然后我做了以下尝试:
-
修改DataLoader中的num_workers和pin_memory参数,都没效果。
-
猜测是每次生成batch时,padding的时间太长导致的。我先去看了dataloader.py和fetch.py的源码,发现每次迭代的时候,确实都会调用collate_fn,然后把padding后的数据返回。
class DataLoader(Generic[T_co]): ... def __iter__(self) -> '_BaseDataLoaderIter': # When using a single worker the returned iterator should be # created everytime to avoid reseting its state # However, in the case of a multiple workers iterator # the iterator is only created once in the lifetime of the # DataLoader object so that workers can be reused if self.persistent_workers and self.num_workers > 0: if self._iterator is None: self._iterator = self._get_iterator() # 这里这里 else: self._iterator._reset(self) return self._iterator else: return self._get_iterator() def _get_iterator(self) -> '_BaseDataLoaderIter': if self.num_workers == 0: return _SingleProcessDataLoaderIter(self) # 这里这里 else: self.check_worker_number_rationality() return _MultiProcessingDataLoaderIter(self) class _SingleProcessDataLoaderIter(_BaseDataLoaderIter): def __init__(self, loader): super(_SingleProcessDataLoaderIter, self).__init__(loader) assert self._timeout == 0 assert self._num_workers == 0 # 这里这里 self._dataset_fetcher = _DatasetKind.create_fetcher( self._dataset_kind, self._dataset, self._auto_collation, self._collate_fn, self._drop_last) def _next_data(self): index = self._next_index() # may raise StopIteration # 这里这里 data = self._dataset_fetcher.fetch(index) # may raise StopIteration if self._pin_memory: data = _utils.pin_memory.pin_memory(data) return data class _DatasetKind(object): Map = 0 Iterable = 1 @staticmethod def create_fetcher(kind, dataset, auto_collation, collate_fn, drop_last): if kind == _DatasetKind.Map: # 这里这里 return _utils.fetch._MapDatasetFetcher(dataset, auto_collation, collate_fn, drop_last) else: return _utils.fetch._IterableDatasetFetcher(dataset, auto_collation, collate_fn, drop_last) class _MapDatasetFetcher(_BaseDatasetFetcher): def __init__(self, dataset, auto_collation, collate_fn, drop_last): super(_MapDatasetFetcher, self).__init__(dataset, auto_collation, collate_fn, drop_last) def fetch(self, possibly_batched_index): if self.auto_collation: data = [self.dataset[idx] for idx in possibly_batched_index] else: data = self.dataset[possibly_batched_index] return self.collate_fn(data) # 这里这里,调用了collate_fn做padding于是,我事先遍历data_loader,取出所有padding好的数据,再去训练。发现时间还是没有缩短= =她还是这么慢…
最后,我在训练函数中,对每次batch data的加载、模型的forward以及gc.collect()函数都做了性能测试。
发现其实加载数据和模型forward都不会很耗时,真正的罪魁祸首是gc.collect()函数!
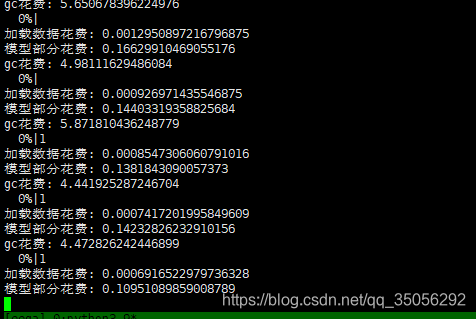
为什么要加这个函数呢?
在之前的模型中,因为forward里写的太复杂,结果训练的时候只训了几百个batch就爆显存,所以我在每次step都做一次垃圾回收。也就是这个操作,成为了一次step中最耗时的操作 [:捂脸
所以,把这个gc.collect()删掉就可以了。
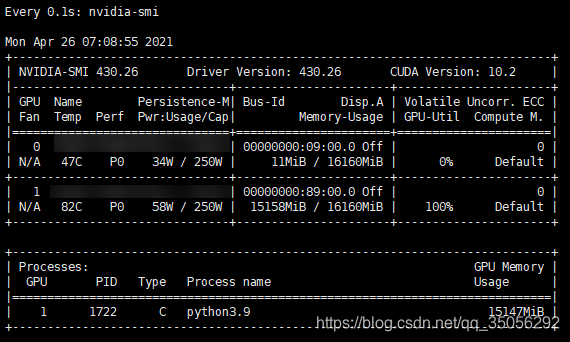
现在,每次step中耗时较短,GPU刚干完一个batch我们又马上给它一个,不给它休息的机会。
终于可以比较好地压榨GPU了😈

















 1517
1517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









