






题目
给你一个非负整数数组 nums 和一个整数 target 。
向数组中的每个整数前添加 '+' 或 '-' ,然后串联起所有整数,可以构造一个表达式:
例如,nums = [2, 1] ,可以在 2 之前添加 '+' ,在 1 之前添加 '-' ,然后串联起来得到表达式 "+2-1" 。
返回可以通过上述方法构造的、运算结果等于 target 的不同表达式的数目。
示例 1:
输入:
nums = [1,1,1,1,1]
target = 3
输出:5
解释:一共有 5 种方法让最终目标和为 3 。
-1 + 1 + 1 + 1 + 1 = 3
+1 - 1 + 1 + 1 + 1 = 3
+1 + 1 - 1 + 1 + 1 = 3
+1 + 1 + 1 - 1 + 1 = 3
+1 + 1 + 1 + 1 - 1 = 3
示例 2:
输入:
nums = [1]
target = 1
输出:1
提示:
1 <= nums.length <= 200 <= nums[i] <= 10000 <= sum(nums[i]) <= 1000-1000 <= target <= 1000
代码
完整代码
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
void dfs(int* nums, int numsSize, int target, int* cnt, bool* flags, int nowIndex) {
if (nowIndex == numsSize) {
int res = 0;
for (int i = 0; i < numsSize; i++) {
if (flags[i]) {
res += nums[i];
} else {
res -= nums[i];
}
}
if (target == res) {
(*cnt)++;
}
return;
}
flags[nowIndex] = true;
dfs(nums, numsSize, target, cnt, flags, nowIndex + 1);
flags[nowIndex] = false;
dfs(nums, numsSize, target, cnt, flags, nowIndex + 1);
}
int findTargetSumWays(int* nums, int numsSize, int target) {
bool* flags = (bool*)calloc(numsSize, sizeof(bool));
int cnt = 0;
dfs(nums, numsSize, target, &cnt, flags, 0);
free(flags);
return cnt;
}
思路分析
这套代码使用深度优先搜索(DFS)方法,通过递归来遍历每个数字的可能符号组合(‘+’ 或 ‘-’),并计算表达式的结果是否等于目标值 target。
拆解分析
dfs函数
void dfs(int* nums, int numsSize, int target, int* cnt, bool* flags, int nowIndex) {
if (nowIndex == numsSize) {
int res = 0;
for (int i = 0; i < numsSize; i++) {
if (flags[i]) {
res += nums[i];
} else {
res -= nums[i];
}
}
if (target == res) {
(*cnt)++;
}
return;
}
flags[nowIndex] = true;
dfs(nums, numsSize, target, cnt, flags, nowIndex + 1);
flags[nowIndex] = false;
dfs(nums, numsSize, target, cnt, flags, nowIndex + 1);
}
dfs函数用于递归遍历所有符号组合。flags数组用于记录每个数字当前的符号。- 当
nowIndex等于numsSize时,表示已经遍历完所有数字。此时计算表达式结果,并与target进行比较。 - 如果结果等于
target,则将计数器cnt加 1。 - 否则,继续递归调用
dfs,分别处理当前数字前添加'+'和'-'的情况。
- 主函数
findTargetSumWays
int findTargetSumWays(int* nums, int numsSize, int target) {
bool* flags = (bool*)calloc(numsSize, sizeof(bool));
int cnt = 0;
dfs(nums, numsSize, target, &cnt, flags, 0);
free(flags);
return cnt;
}
- 初始化
flags数组,用于记录每个数字当前的符号。 - 调用
dfs函数进行递归搜索,计算符合条件的表达式数目。 - 返回结果。
复杂度分析
- 时间复杂度:
O(2^n),其中n是nums的长度。由于每个数字都有两种选择(‘+’ 或 ‘-’),因此共有2^n种组合需要遍历。 - 空间复杂度:O(n),用于存储递归调用栈和
flags数组。
优化
记忆化搜索
通过记忆化搜索(Memoization)可以优化递归计算,避免重复计算相同子问题。
完整代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int dfs(int* nums, int numsSize, int target, int** memo, int sum, int index) {
if (index == numsSize) {
return sum == target ? 1 : 0;
}
if (memo[index][sum + 1000] != -1) {
return memo[index][sum + 1000];
}
int add = dfs(nums, numsSize, target, memo, sum + nums[index], index + 1);
int subtract = dfs(nums, numsSize, target, memo, sum - nums[index], index + 1);
memo[index][sum + 1000] = add + subtract;
return memo[index][sum + 1000];
}
int findTargetSumWays(int* nums, int numsSize, int target) {
int** memo = (int**)malloc(numsSize * sizeof(int*));
for (int i = 0; i < numsSize; i++) {
memo[i] = (int*)malloc(2001 * sizeof(int));
memset(memo[i], -1, 2001 * sizeof(int));
}
int result = dfs(nums, numsSize, target, memo, 0, 0);
for (int i = 0; i < numsSize; i++) {
free(memo[i]);
}
free(memo);
return result;
}
思路分析
通过记忆化搜索,将计算结果存储在二维数组 memo 中,避免重复计算相同子问题。memo[index][sum + 1000] 表示从索引 index 开始,当前累加和为 sum 时能达到目标 target 的方法数。
拆解分析
- 记忆化搜索
dfs函数
int dfs(int* nums, int numsSize, int target, int** memo, int sum, int index) {
if (index == numsSize) {
return sum == target ? 1 : 0;
}
if (memo[index][sum + 1000] != -1) {
return memo[index][sum + 1000];
}
int add = dfs(nums, numsSize, target, memo, sum + nums[index], index + 1);
int subtract = dfs(nums, numsSize, target, memo, sum - nums[index], index + 1);
memo[index][sum + 1000] = add + subtract;
return memo[index][sum + 1000];
}
dfs函数用于递归计算符合条件的表达式数目,并使用memo数组记录中间结果。- 如果
index等于numsSize,判断当前累加和sum是否等于target,返回 1 或 0。 - 如果
memo[index][sum + 1000]已经计算过,直接返回记录的值。 - 否则,递归计算当前数字前添加
'+'和'-'的情况,并将结果记录到memo中。
- 主函数
findTargetSumWays
int findTargetSumWays(int* nums, int numsSize, int target) {
int** memo = (int**)malloc(numsSize * sizeof(int*));
for (int i = 0; i < numsSize; i++) {
memo[i] = (int*)malloc(2001 * sizeof(int));
memset(memo[i], -1, 2001 * sizeof(int));
}
int result = dfs(nums, numsSize, target, memo, 0, 0);
for (int i = 0; i < numsSize; i++) {
free(memo[i]);
}
free(memo);
return result;
}
- 初始化
memo数组
,用于记录中间结果。
- 调用
dfs函数进行递归搜索,计算符合条件的表达式数目。 - 返回结果。
记忆化搜索图解
为了更好地解释记忆化搜索,我们使用一个示例来展示如何通过递归和记忆化来计算表达式的数目。假设输入数组 nums = [1, 1, 1, 1, 1] 和目标 target = 3。
递归树
-
初始调用
dfs(nums, numsSize, target, memo, 0, 0)- 从索引 0 开始,当前累加和为 0。
-
从索引 0 开始,我们有两种选择:
- 加上第一个数字:
sum = 0 + 1 = 1 - 减去第一个数字:
sum = 0 - 1 = -1
- 加上第一个数字:
-
继续递归计算,每个选择都分成两种情况:
- 加上当前数字
- 减去当前数字
(0, 0)
/ \
(1, 1) (1, -1)
/ \ / \
(2, 2) (2, 0) (2, 0) (2, -2)
/ \ / \ / \ / \
(3, 3) (3, 1) (3, 1) (3, -1) (3, 1) (3, -1) (3, -1) (3, -3)
每个节点 (index, sum) 表示当前处理到的索引和累加和。在达到叶节点时,我们检查累加和是否等于目标值 target。如果是,则增加计数。
记忆化
记忆化通过保存已经计算过的子问题的结果来避免重复计算。这里我们使用一个二维数组 memo[index][sum] 来存储结果。
例如,当我们计算 dfs(nums, numsSize, target, memo, 3, 1) 时,我们将结果保存在 memo[3][1] 中。如果再次遇到相同的子问题,可以直接使用存储的结果而不需要再次计算。
图示
初始调用:
dfs(0, 0)
memo 数组初始化为 -1
第一步:
加上第一个数字: dfs(1, 1)
减去第一个数字: dfs(1, -1)
memo[0][0 + 1000] = 5 // 最终结果
第二步:
加上第二个数字: dfs(2, 2)
减去第二个数字: dfs(2, 0)
加上第二个数字: dfs(2, 0)
减去第二个数字: dfs(2, -2)
memo[1][1 + 1000] = 3
memo[1][-1 + 1000] = 2
第三步:
加上第三个数字: dfs(3, 3)
减去第三个数字: dfs(3, 1)
加上第三个数字: dfs(3, 1)
减去第三个数字: dfs(3, -1)
加上第三个数字: dfs(3, 1)
减去第三个数字: dfs(3, -1)
加上第三个数字: dfs(3, -1)
减去第三个数字: dfs(3, -3)
memo[2][2 + 1000] = 1
memo[2][0 + 1000] = 2
memo[2][-2 + 1000] = 1
以此类推,最终我们得到 memo 数组,避免了重复计算。
记忆化搜索流程图
- 初始状态:调用
dfs(0, 0)。 - 递归计算:每次递归计算加上或减去当前数字,更新
index和sum。 - 记忆化存储:如果
memo[index][sum + 1000]已经计算过,则直接返回结果。 - 返回结果:当遍历完整个数组时,检查
sum是否等于target,返回结果。
题目限制与偏移量选择
题目中给出的限制是:
1 <= nums.length <= 200 <= nums[i] <= 1000-1000 <= target <= 1000
为了确保 sum + 1000 不会产生负数并且能作为数组下标,我们需要将 sum 偏移到一个非负的范围。
为什么需要偏移量
假设没有偏移量,我们直接使用 sum 作为数组下标,那么对于 sum 为负的情况,将会导致数组下标越界,进而导致程序崩溃。为了避免这个问题,我们引入偏移量,将所有可能的 sum 偏移到一个非负范围。
偏移量的选择
我们选择 1000 作为偏移量是因为 sum 的最大负值是 -1000,偏移后可以确保 sum 在 [0, 2000] 范围内,这样可以用来作为数组的下标。
memo数组
对于数组 nums 的某个索引 i 和某个和 sum,memo[i][sum + OFFSET] 存储的是从索引 i 开始,通过加减数组元素得到 sum 的所有可能表达式的数目。
例子
假设 nums = [1, 1, 1, 1, 1] 和 target = 3,当我们递归地处理这个问题时,memo 数组会存储以下信息:
memo[0][0 + OFFSET]:从nums[0]开始,能得到和0的所有可能的表达式数目。memo[1][1 + OFFSET]:从nums[1]开始,能得到和1的所有可能的表达式数目。- …
关键点
-
递归终止条件:
if (index == numsSize) { return (sum == target) ? 1 : 0; }当递归达到数组的末尾时,判断当前和
sum是否等于target,如果等于则返回 1(表示找到一种方法),否则返回 0(表示没有找到方法)。 -
记忆化数组的使用:
if (memo[index][sum + OFFSET] != -1) { return memo[index][sum + OFFSET]; }如果
memo[index][sum + OFFSET]已经被计算过,则直接返回其值,避免重复计算。 -
记忆化数组的更新:
memo[index][sum + OFFSET] = dfs(nums, numsSize, target, index + 1, sum + nums[index], memo) + dfs(nums, numsSize, target, index + 1, sum - nums[index], memo);通过递归计算从
index开始的所有可能表达式的数目,并将结果存储在memo[index][sum + OFFSET]中。
memo 数组在处理完成后存储的是每个子问题的解,即从某个索引 index 开始,通过加减数组元素得到某个和 sum 的所有可能表达式的数目。这种方法通过记忆化搜索避免了重复计算,极大地提高了算法的效率。
复杂度分析
- 时间复杂度:O(n * sum),其中
n是nums的长度,sum是nums数组元素的和。通过记忆化搜索,避免了重复计算,提高了效率。 - 空间复杂度:O(n * sum),用于存储
memo数组。
结果
优化前:
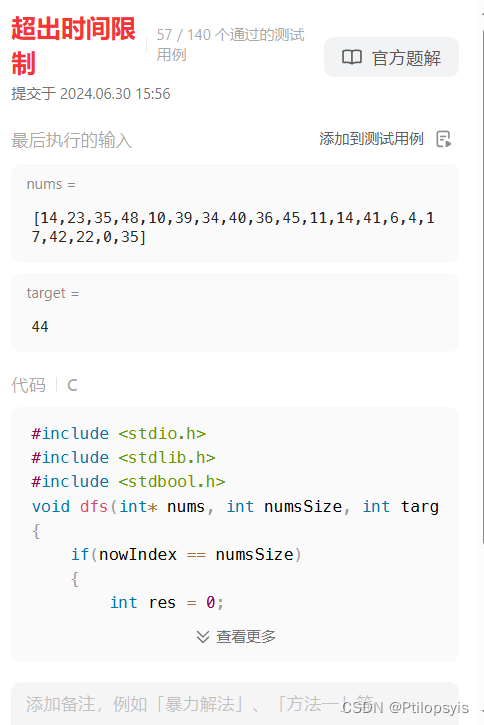
优化后:
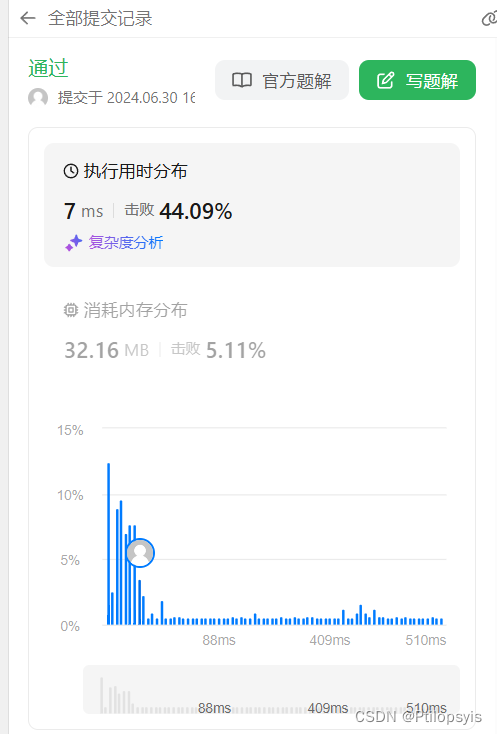















 1805
1805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









