







简单和明了,Storm让大数据分析变得轻松加愉快。
当今世界,公司的日常运营经常会生成TB级别的数据。数据来源囊括了互联网装置可以捕获的任何类型数据,网站、社交媒体、交易型商业数据以及其它商业环境中创建的数据。考虑到数据的生成量,实时处理成为了许多机构需要面对的首要挑战。我们经常用的一个非常有效的开源实时计算工具就是Storm —— Twitter开发,通常被比作“实时的Hadoop”。然而Storm远比Hadoop来的简单,因为用它处理大数据不会带来新老技术的交替。
Shruthi Kumar、Siddharth Patankar共同效力于Infosys,分别从事技术分析和研发工作。本文详述了Storm的使用方法,例子中的项目名称为“超速报警系统(Speeding Alert System)”。我们想实现的功能是:实时分析过往车辆的数据,一旦车辆数据超过预设的临界值 —— 便触发一个trigger并把相关的数据存入数据库。
1. Storm是什么
全量数据处理使用的大多是鼎鼎大名的hadoop或者hive,作为一个批处理系统,hadoop以其吞吐量大、自动容错等优点,在海量数据处理上得到了广泛的使用。
Hadoop下的Map/Reduce框架对于数据的处理流程是:
1、 将要处理的数据上传到Hadoop的文件系统HDFS中。
2、 Map阶段
a) Master对Map的预处理:对于大量的数据进行切分,划分为M个16~64M的数据分片(可通过参数自定义分片大小)
b) 调用Mapper函数:Master为Worker分配Map任务,每个分片都对应一个Worker进行处理。各个Worker读取并调用用户定义的Mapper函数 处理数据,并将结果存入HDFS,返回存储位置给Master。
一个Worker在Map阶段完成时,在HDFS中,生成一个排好序的Key-values组成的文件。并将位置信息汇报给Master。
3、 Reduce阶段
a) Master对Reduce的预处理:Master为Worker分配Reduce任务,他会将所有Mapper产生的数据进行映射,将相同key的任务分配给某个Worker。
b) 调用Reduce函数:各个Worker将分配到的数据集进行排序(使用工具类Merg),并调用用户自定义的Reduce函数,并将结果写入HDFS。
每个Worker的Reduce任务完成后,都会在HDFS中生成一个输出文件。Hadoop并不将这些文件合并,因为这些文件往往会作为另一个Map/reduce程序的输入。
以上的流程,粗略概括,就是从HDFS中获取数据,将其按照大小分片,进行分布式处理,最终输出结果。从流程来看,Hadoop框架进行数据处理有以下要求:
1、 数据已经存在在HDFS当中。
2、 数据间是少关联的。各个任务执行器在执行负责的数据时,无需考虑对其他数据的影响,数据之间应尽可能是无联系、不会影响的。
使用Hadoop,适合大批量的数据处理,这是他所擅长的。由于基于Map/Reduce这种单级的数据处理模型进行,因此,如果数据间的关联系较大,需要进行数据的多级交互处理(某个阶段的处理数据依赖于上一个阶段),需要进行多次map/reduce。又由于map/reduce每次执行都需要遍历整个数据集,对于数据的实时计算并不合适,于是有了storm。
对比Hadoop的批处理,Storm是个实时的、分布式以及具备高容错的计算系统。同Hadoop一样Storm也可以处理大批量的数据,然而Storm在保证高可靠性的前提下还可以让处理进行的更加实时;也就是说,所有的信息都会被处理。Storm同样还具备容错和分布计算这些特性,这就让Storm可以扩展到不同的机器上进行大批量的数据处理。他同样还有以下的这些特性:
- 易于扩展:对于扩展,伴随着业务的发展,我们的数据量、计算量可能会越来越大,所以希望这个系统是可扩展的。你只需要添加机器和改变对应的topology(拓扑)设置。Storm使用Hadoop Zookeeper进行集群协调,这样可以充分的保证大型集群的良好运行。
- 每条信息的处理都可以得到保证。
- Storm集群管理简易。
- Storm的容错机能:一旦topology递交,Storm会一直运行它直到topology被废除或者被关闭。而在执行中出现错误时,也会由Storm重新分配任务。这是分布式系统中通用问题。一个节点挂了不能影响我的应用。
- 低延迟。都说了是实时计算系统了,延迟是一定要低的。
- 尽管通常使用Java,Storm中的topology可以用任何语言设计。
在线实时流处理模型
对于处理大批量数据的Map/reduce程序,在任务完成之后就停止了,但Storm是用于实时计算的,所以,相应的处理程序会一直执行(等待任务,有任务则执行)直至手动停止。
对于Storm,他是实时处理模型,与hadoop的不同是,他是针对在线业务而存在的计算平台,如统计某用户的交易量、生成为某个用户的推荐列表等实时性高的需求。他是一个“流处理”框架。何谓流处理?storm将数据以Stream的方式,并按照Topology的顺序,依次处理并最终生成结果。
当然为了更好的理解文章,你首先需要安装和设置Storm。需要通过以下几个简单的步骤:
- 从Storm官方下载Storm安装文件
- 将bin/directory解压到你的PATH上,并保证bin/storm脚本是可执行的。
Storm集群和Hadoop集群表面上看很类似。但是Hadoop上运行的是MapReduce jobs,而在Storm上运行的是拓扑(topology),这两者之间是非常不一样的。一个关键的区别是: 一个MapReduce job最终会结束, 而一个topology永远会运行(除非你手动kill掉)。
Storm集群主要由一个主节点(Nimbus后台程序)和一群工作节点(worker node)Supervisor的节点组成,通过 Zookeeper进行协调。Nimbus类似Hadoop里面的JobTracker。Nimbus负责在集群里面分发代码,分配计算任务给机器, 并且监控状态。
每一个工作节点上面运行一个叫做Supervisor的节点。Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程。每一个工作进程执行一个topology的一个子集;一个运行的topology由运行在很多机器上的很多工作进程组成。
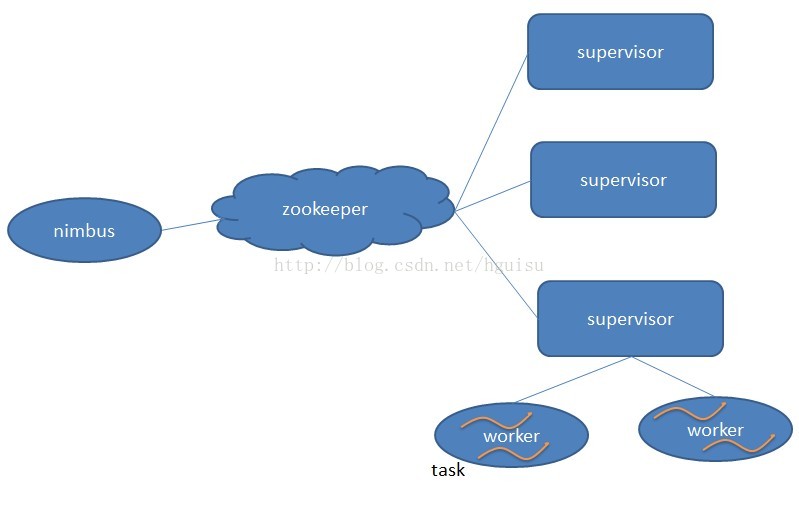
1、 Nimbus主节点:
主节点通常运行一个后台程序 —— Nimbus,用于响应分布在集群中的节点,分配任务和监测故障。这个很类似于Hadoop中的Job Tracker。
2、Supervisor工作节点:
工作节点同样会运行一个后台程序 —— Supervisor,用于收听工作指派并基于要求运行工作进程。每个工作节点都是topology中一个子集的实现。而Nimbus和Supervisor之间的协调则通过Zookeeper系统或者集群。
3、Zookeeper
Zookeeper是完成Supervisor和Nimbus之间协调的服务。而应用程序实现实时的逻辑则被封装进Storm中的“topology”。topology则是一组由Spouts(数据源)和Bolts(数据操作)通过Stream Groupings进行连接的图。下面对出现的术语进行更深刻的解析。
4、Worker:
运行具体处理组件逻辑的进程。
5、Task:
worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,同一个spout/bolt的task可能会共享一个物理线程,该线程称为executor。
6、Topology(拓扑):
storm中运行的一个实时应用程序,因为各个组件间的消息流动形成逻辑上的一个拓扑结构。一个topology是spouts和bolts组成的图, 通过stream groupings将图中的spouts和bolts连接起来,如下图:
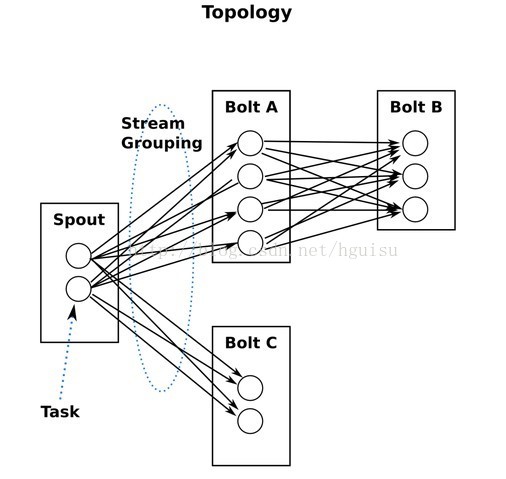
一个topology会一直运行直到你手动kill掉,Storm自动重新分配执行失败的任务, 并且Storm可以保证你不会有数据丢失(如果开启了高可靠性的话)。如果一些机器意外停机它上面的所有任务会被转移到其他机器上。
运行一个topology很简单。首先,把你所有的代码以及所依赖的jar打进一个jar包。然后运行类似下面的这个命令:
storm jar all-my-code.jar backtype.storm.MyTopology arg1 arg2
这个命令会运行主类: backtype.strom.MyTopology, 参数是arg1, arg2。这个类的main函数定义这个topology并且把它提交给Nimbus。storm jar负责连接到Nimbus并且上传jar包。
Topology的定义是一个Thrift结构,并且Nimbus就是一个Thrift服务, 你可以提交由任何语言创建的topology。上面的方面是用JVM-based语言提交的最简单的方法。
7、Spout:
消息源spout是Storm里面一个topology里面的消息生产者。简而言之,Spout从来源处读取数据并放入topology。Spout分成可靠和不可靠两种;当Storm接收失败时,可靠的Spout会对tuple(元组,数据项组成的列表)进行重发;而不可靠的Spout不会考虑接收成功与否只发射一次。
消息源可以发射多条消息流stream。使用OutputFieldsDeclarer.declareStream来定义多个stream,然后使用SpoutOutputCollector来发射指定的stream。
而Spout中最主要的方法就是nextTuple(),该方法会发射一个新的tuple到topology,如果没有新tuple发射则会简单的返回。
要注意的是nextTuple方法不能阻塞,因为storm在同一个线程上面调用所有消息源spout的方法。
另外两个比较重要的spout方法是ack和fail。storm在检测到一个tuple被整个topology成功处理的时候调用ack,否则调用fail。storm只对可靠的spout调用ack和fail。
8、Bolt:
Topology中所有的处理都由Bolt完成。即所有的消息处理逻辑被封装在bolts里面。Bolt可以完成任何事,比如:连接的过滤、聚合、访问文件/数据库、等等。
Bolt从Spout中接收数据并进行处理,如果遇到复杂流的处理也可能将tuple发送给另一个Bolt进行处理。即需要经过很多blots。比如算出一堆图片里面被转发最多的图片就至少需要两步:第一步算出每个图片的转发数量。第二步找出转发最多的前10个图片。(如果要把这个过程做得更具有扩展性那么可能需要更多的步骤)。
Bolts可以发射多条消息流, 使用OutputFieldsDeclarer.declareStream定义stream,使用OutputCollector.emit来选择要发射的stream。
而Bolt中最重要的方法是execute(),以新的tuple作为参数接收。不管是Spout还是Bolt,如果将tuple发射成多个流,这些流都可以通过declareStream()来声明。
bolts使用OutputCollector来发射tuple,bolts必须要为它处理的每一个tuple调用OutputCollector的ack方法,以通知Storm这个tuple被处理完成了,从而通知这个tuple的发射者spouts。 一般的流程是: bolts处理一个输入tuple, 发射0个或者多个tuple, 然后调用ack通知storm自己已经处理过这个tuple了。storm提供了一个IBasicBolt会自动调用ack。
9、Tuple:
一次消息传递的基本单元。本来应该是一个key-value的map,但是由于各个组件间传递的tuple的字段名称已经事先定义好,所以tuple中只要按序填入各个value就行了,所以就是一个value list.
10、Stream:
源源不断传递的tuple就组成了stream。消息流stream是storm里的关键抽象。一个消息流是一个没有边界的tuple序列, 而这些tuple序列会以一种分布式的方式并行地创建和处理。通过对stream中tuple序列中每个字段命名来定义stream。在默认的情况下,tuple的字段类型可以是:integer,long,short, byte,string,double,float,boolean和byte array。你也可以自定义类型(只要实现相应的序列化器)。
每个消息流在定义的时候会被分配给一个id,因为单向消息流使用的相当普遍, OutputFieldsDeclarer定义了一些方法让你可以定义一个stream而不用指定这个id。在这种情况下这个stream会分配个值为‘default’默认的id 。
Storm提供的最基本的处理stream的原语是spout和bolt。你可以实现spout和bolt提供的接口来处理你的业务逻辑。
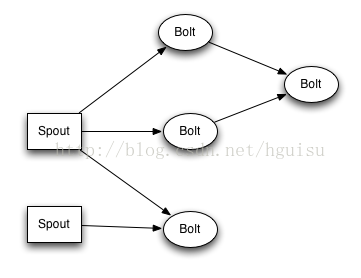
11、Stream Groupings:
Stream Grouping定义了一个流在Bolt任务间该如何被切分。这里有Storm提供的6个Stream Grouping类型:
1). 随机分组(Shuffle grouping):随机分发tuple到Bolt的任务,保证每个任务获得相等数量的tuple。
2). 字段分组(Fields grouping):根据指定字段分割数据流,并分组。例如,根据“user-id”字段,相同“user-id”的元组总是分发到同一个任务,不同“user-id”的元组可能分发到不同的任务。
3). 全部分组(All grouping):tuple被复制到bolt的所有任务。这种类型需要谨慎使用。
4). 全局分组(Global grouping):全部流都分配到bolt的同一个任务。明确地说,是分配给ID最小的那个task。
5). 无分组(None grouping):你不需要关心流是如何分组。目前,无分组等效于随机分组。但最终,Storm将把无分组的Bolts放到Bolts或Spouts订阅它们的同一线程去执行(如果可能)。
6). 直接分组(Direct grouping):这是一个特别的分组类型。元组生产者决定tuple由哪个元组处理者任务接收。
当然还可以实现CustomStreamGroupimg接口来定制自己需要的分组。
storm 和hadoop的对比来了解storm中的基本概念。
| Hadoop | Storm | |
| 系统角色 | JobTracker | Nimbus |
| TaskTracker | Supervisor | |
| Child | Worker | |
| 应用名称 | Job | Topology |
| 组件接口 | Mapper/Reducer | Spout/Bolt |
3. Storm应用场景
Storm 与其他大数据解决方案的不同之处在于它的处理方式。Hadoop 在本质上是一个批处理系统。数据被引入 Hadoop 文件系统 (HDFS) 并分发到各个节点进行处理。当处理完成时,结果数据返回到 HDFS 供始发者使用。Storm 支持创建拓扑结构来转换没有终点的数据流。不同于 Hadoop 作业,这些转换从不停止,它们会持续处理到达的数据。
Twitter列举了Storm的三大类应用:
1. 信息流处理{Stream processing}
Storm可用来实时处理新数据和更新数据库,兼具容错性和可扩展性。即Storm可以用来处理源源不断流进来的消息,处理之后将结果写入到某个存储中去。
2. 连续计算{Continuous computation}
Storm可进行连续查询并把结果即时反馈给客户端。比如把Twitter上的热门话题发送到浏览器中。
3. 分布式远程程序调用{Distributed RPC}
Storm可用来并行处理密集查询。Storm的拓扑结构是一个等待调用信息的分布函数,当它收到一条调用信息后,会对查询进行计算,并返回查询结果。举个例子Distributed RPC可以做并行搜索或者处理大集合的数据。
通过配置drpc服务器,将storm的topology发布为drpc服务。客户端程序可以调用drpc服务将数据发送到storm集群中,并接收处理结果的反馈。这种方式需要drpc服务器进行转发,其中drpc服务器底层通过thrift实现。适合的业务场景主要是实时计算。并且扩展性良好,可以增加每个节点的工作worker数量来动态扩展。
4. 项目实施,构建Topology
当下情况我们需要给Spout和Bolt设计一种能够处理大量数据(日志文件)的topology,当一个特定数据值超过预设的临界值时促发警报。使用Storm的topology,逐行读入日志文件并且监视输入数据。在Storm组件方面,Spout负责读入输入数据。它不仅从现有的文件中读入数据,同时还监视着新文件。文件一旦被修改Spout会读入新的版本并且覆盖之前的tuple(可以被Bolt读入的格式),将tuple发射给Bolt进行临界分析,这样就可以发现所有可能超临界的记录。
下一节将对用例进行详细介绍。
临界分析
这一节,将主要聚焦于临界值的两种分析类型:瞬间临界(instant thershold)和时间序列临界(time series threshold)。
- 瞬间临界值监测:一个字段的值在那个瞬间超过了预设的临界值,如果条件符合的话则触发一个trigger。举个例子当车辆超越80公里每小时,则触发trigger。
- 时间序列临界监测:字段的值在一个给定的时间段内超过了预设的临界值,如果条件符合则触发一个触发器。比如:在5分钟类,时速超过80KM两次及以上的车辆。
Listing One显示了我们将使用的一个类型日志,其中包含的车辆数据信息有:车牌号、车辆行驶的速度以及数据获取的位置。
| AB 123 | 60 | North city |
| BC 123 | 70 | South city |
| CD 234 | 40 | South city |
| DE 123 | 40 | East city |
| EF 123 | 90 | South city |
| GH 123 | 50 | West city |
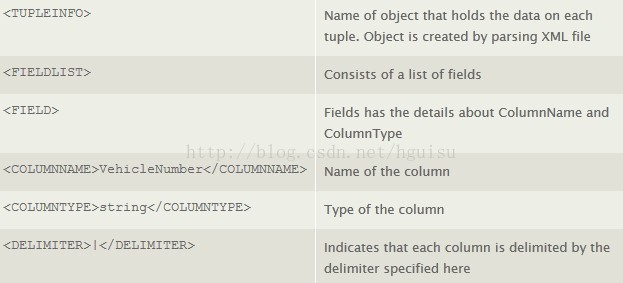
这里将创建一个对应的XML文件,这将包含引入数据的模式。这个XML将用于日志文件的解析。XML的设计模式和对应的说明请见下表。
XML文件和日志文件都存放在Spout可以随时监测的目录下,用以关注文件的实时更新。而这个用例中的topology请见下图。
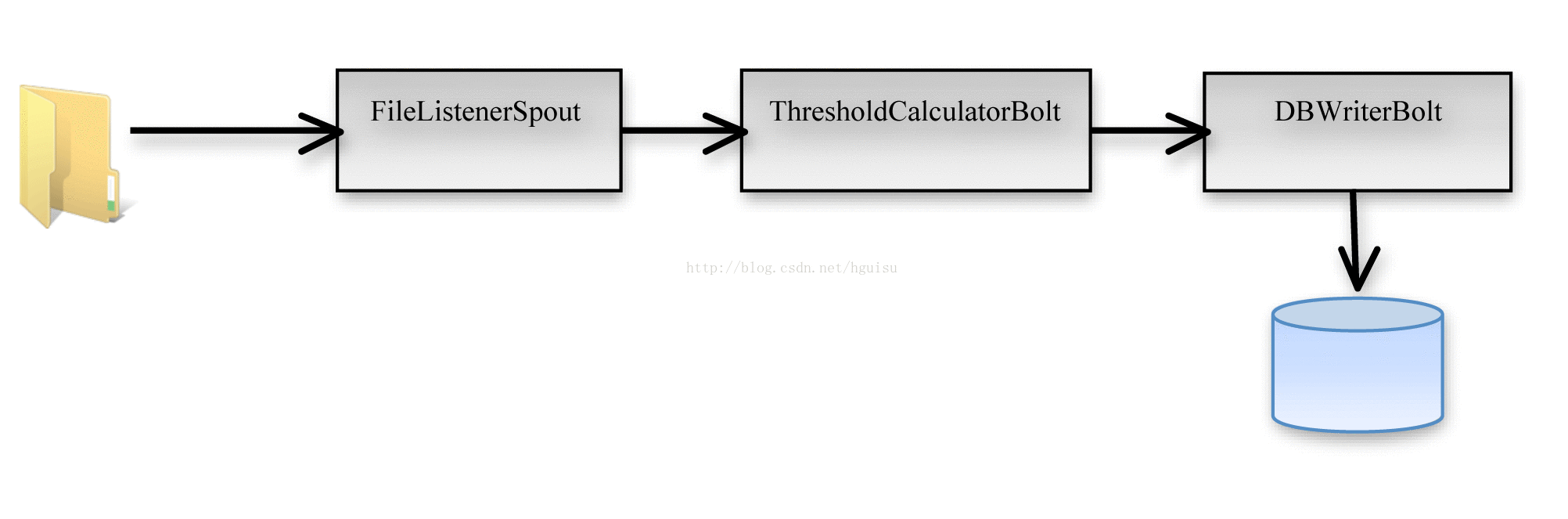
Figure 1:Storm中建立的topology,用以实现数据实时处理
如图所示:FilelistenerSpout接收输入日志并进行逐行的读入,接着将数据发射给ThresoldCalculatorBolt进行更深一步的临界值处理。一旦处理完成,被计算行的数据将发送给DBWriterBolt,然后由DBWriterBolt存入给数据库。下面将对这个过程的实现进行详细的解析。
Spout的实现
Spout以日志文件和XML描述文件作为接收对象。XML文件包含了与日志一致的设计模式。不妨设想一下一个示例日志文件,包含了车辆的车牌号、行驶速度、以及数据的捕获位置。(看下图)
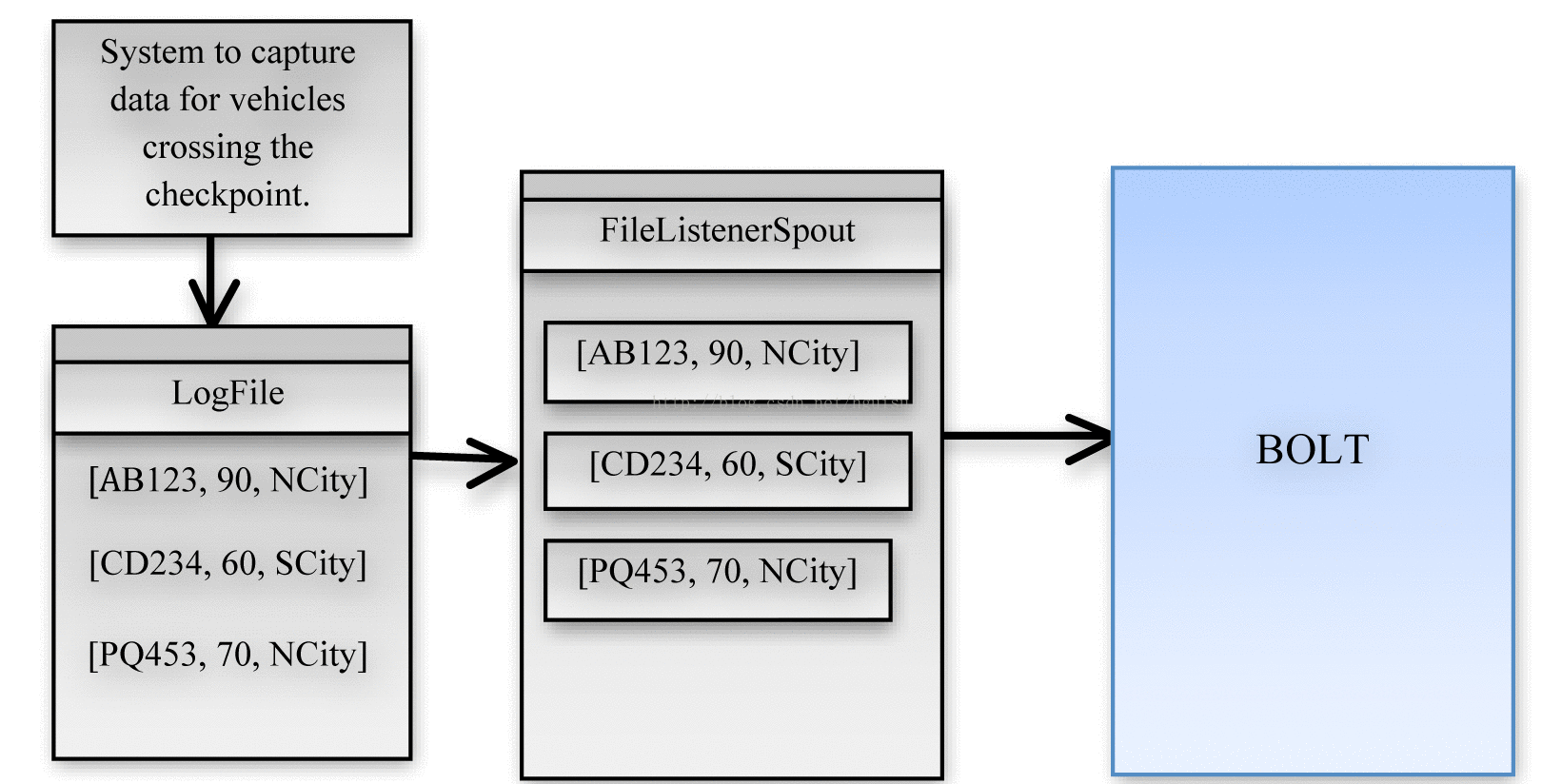
Figure2:数据从日志文件到Spout的流程图
Listing Two显示了tuple对应的XML,其中指定了字段、将日志文件切割成字段的定界符以及字段的类型。XML文件以及数据都被保存到Spout指定的路径。
Listing Two:用以描述日志文件的XML文件。
- <TUPLEINFO>
- <FIELDLIST>
- <FIELD>
- <COLUMNNAME>vehicle_number</COLUMNNAME>
- <COLUMNTYPE>string</COLUMNTYPE>
- </FIELD>
- <FIELD>
- <COLUMNNAME>speed</COLUMNNAME>
- <COLUMNTYPE>int</COLUMNTYPE>
- </FIELD>
- <FIELD>
- <COLUMNNAME>location</COLUMNNAME>
- <COLUMNTYPE>string</COLUMNTYPE>
- </FIELD>
- </FIELDLIST>
- <DELIMITER>,</DELIMITER>
- </TUPLEINFO>
通过构造函数及它的参数Directory、PathSpout和TupleInfo对象创建Spout对象。TupleInfo储存了日志文件的字段、定界符、字段的类型这些很必要的信息。这个对象通过XSTream序列化XML时建立。
Spout的实现步骤:
- 对文件的改变进行分开的监听,并监视目录下有无新日志文件添加。
- 在数据得到了字段的说明后,将其转换成tuple。
- 声明Spout和Bolt之间的分组,并决定tuple发送给Bolt的途径。
Spout的具体编码在Listing Three中显示。
Listing Three:Spout中open、nextTuple和delcareOutputFields方法的逻辑。
- public void open( Map conf, TopologyContext context,SpoutOutputCollector collector )
- {
- _collector = collector;
- try
- {
- fileReader = new BufferedReader(new FileReader(new File(file)));
- }
- catch (FileNotFoundException e)
- {
- System.exit(1);
- }
- }
- public void nextTuple()
- {
- protected void ListenFile(File file)
- {
- Utils.sleep(2000);
- RandomAccessFile access = null;
- String line = null;
- try
- {
- while ((line = access.readLine()) != null)
- {
- if (line !=null)
- {
- String[] fields=null;
- if (tupleInfo.getDelimiter().equals("|")) fields = line.split("\\"+tupleInfo.getDelimiter());
- else
- fields = line.split (tupleInfo.getDelimiter());
- if (tupleInfo.getFieldList().size() == fields.length) _collector.emit(new Values(fields));
- }
- }
- }
- catch (IOException ex){ }
- }
- }
- public void declareOutputFields(OutputFieldsDeclarer declarer)
- {
- String[] fieldsArr = new String [tupleInfo.getFieldList().size()];
- for(int i=0; i<tupleInfo.getFieldList().size(); i++)
- {
- fieldsArr[i] = tupleInfo.getFieldList().get(i).getColumnName();
- }
- declarer.declare(new Fields(fieldsArr));
- }
declareOutputFileds()决定了tuple发射的格式,这样的话Bolt就可以用类似的方法将tuple译码。Spout持续对日志文件的数据的变更进行监听,一旦有添加Spout就会进行读入并且发送给Bolt进行处理。
Bolt的实现
Spout的输出结果将给予Bolt进行更深一步的处理。经过对用例的思考,我们的topology中需要如Figure 3中的两个Bolt。
Figure 3:Spout到Bolt的数据流程。
ThresholdCalculatorBolt
Spout将tuple发出,由ThresholdCalculatorBolt接收并进行临界值处理。在这里,它将接收好几项输入进行检查;分别是:
临界值检查
- 临界值栏数检查(拆分成字段的数目)
- 临界值数据类型(拆分后字段的类型)
- 临界值出现的频数
- 临界值时间段检查
Listing Four中的类,定义用来保存这些值。
Listing Four:ThresholdInfo类
- public class ThresholdInfo implementsSerializable
- {
- private String action;
- private String rule;
- private Object thresholdValue;
- private int thresholdColNumber;
- private Integer timeWindow;
- private int frequencyOfOccurence;
- }
Listing Five:临界值检测代码段
- public void execute(Tuple tuple, BasicOutputCollector collector)
- {
- if(tuple!=null)
- {
- List<Object> inputTupleList = (List<Object>) tuple.getValues();
- int thresholdColNum = thresholdInfo.getThresholdColNumber();
- Object thresholdValue = thresholdInfo.getThresholdValue();
- String thresholdDataType = tupleInfo.getFieldList().get(thresholdColNum-1).getColumnType();
- Integer timeWindow = thresholdInfo.getTimeWindow();
- int frequency = thresholdInfo.getFrequencyOfOccurence();
- if(thresholdDataType.equalsIgnoreCase("string"))
- {
- String valueToCheck = inputTupleList.get(thresholdColNum-1).toString();
- String frequencyChkOp = thresholdInfo.getAction();
- if(timeWindow!=null)
- {
- long curTime = System.currentTimeMillis();
- long diffInMinutes = (curTime-startTime)/(1000);
- if(diffInMinutes>=timeWindow)
- {
- if(frequencyChkOp.equals("=="))
- {
- if(valueToCheck.equalsIgnoreCase(thresholdValue.toString()))
- {
- count.incrementAndGet();
- if(count.get() > frequency)
- splitAndEmit(inputTupleList,collector);
- }
- }
- else if(frequencyChkOp.equals("!="))
- {
- if(!valueToCheck.equalsIgnoreCase(thresholdValue.toString()))
- {
- count.incrementAndGet();
- if(count.get() > frequency)
- splitAndEmit(inputTupleList,collector);
- }
- }
- else System.out.println("Operator not supported");
- }
- }
- else
- {
- if(frequencyChkOp.equals("=="))
- {
- if(valueToCheck.equalsIgnoreCase(thresholdValue.toString()))
- {
- count.incrementAndGet();
- if(count.get() > frequency)
- splitAndEmit(inputTupleList,collector);
- }
- }
- else if(frequencyChkOp.equals("!="))
- {
- if(!valueToCheck.equalsIgnoreCase(thresholdValue.toString()))
- {
- count.incrementAndGet();
- if(count.get() > frequency)
- splitAndEmit(inputTupleList,collector);
- }
- }
- }
- }
- else if(thresholdDataType.equalsIgnoreCase("int") || thresholdDataType.equalsIgnoreCase("double") || thresholdDataType.equalsIgnoreCase("float") || thresholdDataType.equalsIgnoreCase("long") || thresholdDataType.equalsIgnoreCase("short"))
- {
- String frequencyChkOp = thresholdInfo.getAction();
- if(timeWindow!=null)
- {
- long valueToCheck = Long.parseLong(inputTupleList.get(thresholdColNum-1).toString());
- long curTime = System.currentTimeMillis();
- long diffInMinutes = (curTime-startTime)/(1000);
- System.out.println("Difference in minutes="+diffInMinutes);
- if(diffInMinutes>=timeWindow)
- {
- if(frequencyChkOp.equals("<"))
- {
- if(valueToCheck < Double.parseDouble(thresholdValue.toString()))
- {
- count.incrementAndGet();
- if(count.get() > frequency)
- splitAndEmit(inputTupleList,collector);
- }
- }
- else if(frequencyChkOp.equals(">"))
- {
- if(valueToCheck > Double.parseDouble(thresholdValue.toString()))
- {
- count.incrementAndGet();
- if(count.get() > frequency)
- splitAndEmit(inputTupleList,collector);
- }
- }
- else if(frequencyChkOp.equals("=="))
- {
- if(valueToCheck == Double.parseDouble(thresholdValue.toString()))
- {
- count.incrementAndGet();
- if(count.get() > frequency)
- splitAndEmit(inputTupleList,collector);
- }
- }
- else if(frequencyChkOp.equals("!="))
- {
- . . .
- }
- }
- }
- else
- splitAndEmit(null,collector);
- }
- else
- {
- System.err.println("Emitting null in bolt");
- splitAndEmit(null,collector);
- }
- }
经由Bolt发送的的tuple将会传递到下一个对应的Bolt,在我们的用例中是DBWriterBolt。
DBWriterBolt
经过处理的tuple必须被持久化以便于触发tigger或者更深层次的使用。DBWiterBolt做了这个持久化的工作并把tuple存入了数据库。表的建立由prepare()函数完成,这也将是topology调用的第一个方法。方法的编码如Listing Six所示。
Listing Six:建表编码。
- public void prepare( Map StormConf, TopologyContext context )
- {
- try
- {
- Class.forName(dbClass);
- }
- catch (ClassNotFoundException e)
- {
- System.out.println("Driver not found");
- e.printStackTrace();
- }
- try
- {
- connection driverManager.getConnection(
- "jdbc:mysql://"+databaseIP+":"+databasePort+"/"+databaseName, userName, pwd);
- connection.prepareStatement("DROP TABLE IF EXISTS "+tableName).execute();
- StringBuilder createQuery = new StringBuilder(
- "CREATE TABLE IF NOT EXISTS "+tableName+"(");
- for(Field fields : tupleInfo.getFieldList())
- {
- if(fields.getColumnType().equalsIgnoreCase("String"))
- createQuery.append(fields.getColumnName()+" VARCHAR(500),");
- else
- createQuery.append(fields.getColumnName()+" "+fields.getColumnType()+",");
- }
- createQuery.append("thresholdTimeStamp timestamp)");
- connection.prepareStatement(createQuery.toString()).execute();
- // Insert Query
- StringBuilder insertQuery = new StringBuilder("INSERT INTO "+tableName+"(");
- String tempCreateQuery = new String();
- for(Field fields : tupleInfo.getFieldList())
- {
- insertQuery.append(fields.getColumnName()+",");
- }
- insertQuery.append("thresholdTimeStamp").append(") values (");
- for(Field fields : tupleInfo.getFieldList())
- {
- insertQuery.append("?,");
- }
- insertQuery.append("?)");
- prepStatement = connection.prepareStatement(insertQuery.toString());
- }
- catch (SQLException e)
- {
- e.printStackTrace();
- }
- }
数据分批次的插入数据库。插入的逻辑由Listting Seven中的execute()方法提供。大部分的编码都是用来实现可能存在不同类型输入的解析。
Listing Seven:数据插入的代码部分。
- public void execute(Tuple tuple, BasicOutputCollector collector)
- {
- batchExecuted=false;
- if(tuple!=null)
- {
- List<Object> inputTupleList = (List<Object>) tuple.getValues();
- int dbIndex=0;
- for(int i=0;i<tupleInfo.getFieldList().size();i++)
- {
- Field field = tupleInfo.getFieldList().get(i);
- try {
- dbIndex = i+1;
- if(field.getColumnType().equalsIgnoreCase("String"))
- prepStatement.setString(dbIndex, inputTupleList.get(i).toString());
- else if(field.getColumnType().equalsIgnoreCase("int"))
- prepStatement.setInt(dbIndex,
- Integer.parseInt(inputTupleList.get(i).toString()));
- else if(field.getColumnType().equalsIgnoreCase("long"))
- prepStatement.setLong(dbIndex,
- Long.parseLong(inputTupleList.get(i).toString()));
- else if(field.getColumnType().equalsIgnoreCase("float"))
- prepStatement.setFloat(dbIndex,
- Float.parseFloat(inputTupleList.get(i).toString()));
- else if(field.getColumnType().equalsIgnoreCase("double"))
- prepStatement.setDouble(dbIndex,
- Double.parseDouble(inputTupleList.get(i).toString()));
- else if(field.getColumnType().equalsIgnoreCase("short"))
- prepStatement.setShort(dbIndex,
- Short.parseShort(inputTupleList.get(i).toString()));
- else if(field.getColumnType().equalsIgnoreCase("boolean"))
- prepStatement.setBoolean(dbIndex,
- Boolean.parseBoolean(inputTupleList.get(i).toString()));
- else if(field.getColumnType().equalsIgnoreCase("byte"))
- prepStatement.setByte(dbIndex,
- Byte.parseByte(inputTupleList.get(i).toString()));
- else if(field.getColumnType().equalsIgnoreCase("Date"))
- {
- Date dateToAdd=null;
- if (!(inputTupleList.get(i) instanceof Date))
- {
- DateFormat df = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
- try
- {
- dateToAdd = df.parse(inputTupleList.get(i).toString());
- }
- catch (ParseException e)
- {
- System.err.println("Data type not valid");
- }
- }
- else
- {
- dateToAdd = (Date)inputTupleList.get(i);
- java.sql.Date sqlDate = new java.sql.Date(dateToAdd.getTime());
- prepStatement.setDate(dbIndex, sqlDate);
- }
- }
- catch (SQLException e)
- {
- e.printStackTrace();
- }
- }
- Date now = new Date();
- try
- {
- prepStatement.setTimestamp(dbIndex+1, new java.sql.Timestamp(now.getTime()));
- prepStatement.addBatch();
- counter.incrementAndGet();
- if (counter.get()== batchSize)
- executeBatch();
- }
- catch (SQLException e1)
- {
- e1.printStackTrace();
- }
- }
- else
- {
- long curTime = System.currentTimeMillis();
- long diffInSeconds = (curTime-startTime)/(60*1000);
- if(counter.get()<batchSize && diffInSeconds>batchTimeWindowInSeconds)
- {
- try {
- executeBatch();
- startTime = System.currentTimeMillis();
- }
- catch (SQLException e) {
- e.printStackTrace();
- }
- }
- }
- }
- public void executeBatch() throws SQLException
- {
- batchExecuted=true;
- prepStatement.executeBatch();
- counter = new AtomicInteger(0);
- }
一旦Spout和Bolt准备就绪(等待被执行),topology生成器将会建立topology并准备执行。下面就来看一下执行步骤。
在本地集群上运行和测试topology
- 通过TopologyBuilder建立topology。
- 使用Storm Submitter,将topology递交给集群。以topology的名字、配置和topology的对象作为参数。
- 提交topology。
Listing Eight:建立和执行topology。
- public class StormMain
- {
- public static void main(String[] args) throws AlreadyAliveException,
- InvalidTopologyException,
- InterruptedException
- {
- ParallelFileSpout parallelFileSpout = new ParallelFileSpout();
- ThresholdBolt thresholdBolt = new ThresholdBolt();
- DBWriterBolt dbWriterBolt = new DBWriterBolt();
- TopologyBuilder builder = new TopologyBuilder();
- builder.setSpout("spout", parallelFileSpout, 1);
- builder.setBolt("thresholdBolt", thresholdBolt,1).shuffleGrouping("spout");
- builder.setBolt("dbWriterBolt",dbWriterBolt,1).shuffleGrouping("thresholdBolt");
- if(this.argsMain!=null && this.argsMain.length > 0)
- {
- conf.setNumWorkers(1);
- StormSubmitter.submitTopology(
- this.argsMain[0], conf, builder.createTopology());
- }
- else
- {
- Config conf = new Config();
- conf.setDebug(true);
- conf.setMaxTaskParallelism(3);
- LocalCluster cluster = new LocalCluster();
- cluster.submitTopology(
- "Threshold_Test", conf, builder.createTopology());
- }
- }
- }
topology被建立后将被提交到本地集群。一旦topology被提交,除非被取缔或者集群关闭,它将一直保持运行不需要做任何的修改。这也是Storm的另一大特色之一。
这个简单的例子体现了当你掌握了topology、spout和bolt的概念,将可以轻松的使用Storm进行实时处理。如果你既想处理大数据又不想遍历Hadoop的话,不难发现使用Storm将是个很好的选择。
5. storm常见问题解答
一、我有一个数据文件,或者我有一个系统里面有数据,怎么导入storm做计算?
你需要实现一个Spout,Spout负责将数据emit到storm系统里,交给bolts计算。怎么实现spout可以参考官方的kestrel spout实现:
https://github.com/nathanmarz/storm-kestrel
如果你的数据源不支持事务性消费,那么就无法得到storm提供的可靠处理的保证,也没必要实现ISpout接口中的ack和fail方法。
二、Storm为了保证tuple的可靠处理,需要保存tuple信息,这会不会导致内存OOM?
Storm为了保证tuple的可靠处理,acker会保存该节点创建的tuple id的xor值,这称为ack value,那么每ack一次,就将tuple id和ack value做异或(xor)。当所有产生的tuple都被ack的时候, ack value一定为0。这是个很简单的策略,对于每一个tuple也只要占用约20个字节的内存。对于100万tuple,也才20M左右。关于可靠处理看这个:
https://github.com/nathanmarz/storm/wiki/Guaranteeing-message-processing
三、Storm计算后的结果保存在哪里?可以保存在外部存储吗?
Storm不处理计算结果的保存,这是应用代码需要负责的事情,如果数据不大,你可以简单地保存在内存里,也可以每次都更新数据库,也可以采用NoSQL存储。storm并没有像s4那样提供一个Persist API,根据时间或者容量来做存储输出。这部分事情完全交给用户。
数据存储之后的展现,也是你需要自己处理的,storm UI只提供对topology的监控和统计。
四、Storm怎么处理重复的tuple?
因为Storm要保证tuple的可靠处理,当tuple处理失败或者超时的时候,spout会fail并重新发送该tuple,那么就会有tuple重复计算的问题。这个问题是很难解决的,storm也没有提供机制帮助你解决。一些可行的策略:
(1)不处理,这也算是种策略。因为实时计算通常并不要求很高的精确度,后续的批处理计算会更正实时计算的误差。
(2)使用第三方集中存储来过滤,比如利用mysql,memcached或者redis根据逻辑主键来去重。
(3)使用bloom filter做过滤,简单高效。
五、Storm的动态增删节点
我在storm和s4里比较里谈到的动态增删节点,是指storm可以动态地添加和减少supervisor节点。对于减少节点来说,被移除的supervisor上的worker会被nimbus重新负载均衡到其他supervisor节点上。在storm 0.6.1以前的版本,增加supervisor节点不会影响现有的topology,也就是现有的topology不会重新负载均衡到新的节点上,在扩展集群的时候很不方便,需要重新提交topology。因此我在storm的邮件列表里提了这个问题,storm的开发者nathanmarz创建了一个issue 54并在0.6.1提供了rebalance命令来让正在运行的topology重新负载均衡,具体见:
https://github.com/nathanmarz/storm/issues/54
和0.6.1的变更:
http://groups.google.com/group/storm-user/browse_thread/thread/24a8fce0b2e53246
storm并不提供机制来动态调整worker和task数目。
六、Storm UI里spout统计的complete latency的具体含义是什么?为什么emit的数目会是acked的两倍?
这个事实上是storm邮件列表里的一个问题。Storm作者marz的解答:
tuple being acked on the spout. So it tracks the time for the whole tuple
tree to be processed.
If you dive into the spout component in the UI, you'll see that a lot of
the emitted/transferred is on the __ack* stream. This is the spout
communicating with the ackers which take care of tracking the tuple trees.
简单地说,complete latency表示了tuple从emit到被acked经过的时间,可以认为是tuple以及该tuple的后续子孙(形成一棵树)整个处理时间。其次spout的emit和transfered还统计了spout和acker之间内部的通信信息,比如对于可靠处理的spout来说,会在emit的时候同时发送一个_ack_init给acker,记录tuple id到task id的映射,以便ack的时候能找到正确的acker task。















 5776
5776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









