







问题:
因为bert是在长文本(512token长度)预训练的,因此,如果没有特定于任务的微调,BERT在短语和句子上的表现通常比简单基线(如GLoVe的平均池化)更差。且字节2020在EMNLP上的On the Sentence Embeddings from Pre-trained Language Models一文证明了BERT 更加依赖词汇重叠来确定短语和句子的相似性。
先前提出的解决方法:
- 在预训练阶段预测跨度而不是单词(Joshi 等人,2019 年),
- 在较短文本上微调 BERT(Reimers 和 Gurevych,2019 年),
- 添加一个明确的后处理步骤以诱导连续和 各向同性语义空间(Li et al., 2020)。
本文提出方法:

Phrase-BERT 通过将语义相似的短语和上下文更靠近地放置在一起(例如,短语“Jack of all trade”和正面释义“a worker with versatile skills”)并通过远离具有对比学习目标的词汇线索(例如,短语“agreement on trade”)来纠正 BERT 的短语嵌入空间。
由于预训练的BERT模型严重依赖词汇重叠来确定短语相似性,作者在BERT的基础上设计了两个单独的微调任务,以提高其生成有意义短语嵌入的能力。Phrase-BERT依赖于使用释义生成模型自动生成的各种短语释义数据集,以及从Books3语料库中挖掘的大规模上下文短语数据集,按照上述远离字符匹配,靠近语义匹配的方法来纠正 BERT 的短语嵌入空间。
1.第一个微调目标依赖于自动生成的词汇多样性短语释义数据集来鼓励该模型不再使用字符匹配。(鼓励 BERT 在不过度依赖这些短语之间的词汇相似性的情况下捕捉短语之间的语义相关性)
2. 第二个目标鼓励该模型通过依赖上下文中的短语数据集将上下文信息编码到短语表示中。
使用bert表示短语:
对于长度为 N 个token的短语 X,通过对 BERT 产生的最后一层token向量求平均值来计算表示 x
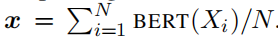
创建词汇多样的短语级释义:
使用 CoreNLP 中的 shift-reduce 解析器从 WikiText-103中提取 10 万个短语创建了一个数据集,然后,给出一个短语,通过基于 GPT2 的多样化释义模型(模型是在过滤版本的 PARANMT-50M 句子级复述数据集上微调的 GPT2-large)构造正样本。对于负样本,首先随机抽取一个非停用词,然后用词汇表中的随机标记替换它,然后,将构造的短语输入到释义模型中并进行解码,就像为生成正例所做的那样,这消除了词汇重叠但保留了扭曲的含义。
收集上下文中的短语:
创建了第二个数据集,将上下文信息注入BERT的短语嵌入。具体而言,作者从Books3语料库中提取短语及其周围上下文,通过在数据集的随机子集上运行选区分析来提取短语;并删除所有长度超过10个token的短语,然后选择前100K个最常出现的短语。
使用构建的数据集微调 BERT
鼓励模型为 p 和 p+ 生成类似的嵌入,同时将 p 和 p− 的嵌入推得更远。通过使用bert表示短语将每个短语嵌入到三元组 (p, p+, p−) 中, 然后,计算三元组损失:
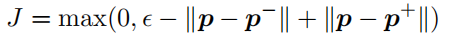
对于第二个数据集,同样的,使用三元组损失
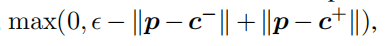
实验结果:

在所有五个评估数据集中,Phrase-BERT始终优于BERT和其他基线模型。在基线中,Sentence-BERT也比BERT有显著改进,这表明了短语和句子级语义之间的关系。相比之下,Phrase-BERT优于Sentence-BERT,特别是在输入非常短的任务中。此外,尽管SpanBERT的隐藏跨度预测目标直观上可能会增加其表示短语的能力,但该模型在所有任务中的表现始终不佳。
另一方面,Phrase-BERT强大的全面性能表明它能够**超越字符串匹配。**不论长短语还是短短语,BERT和其他基线严重依赖词汇重叠而不是组合性来编码短语相关性。尽管在完整的PPDB数据集上具有较高的准确性,但基线在(PPDB过滤,PAWS短)两个数据集上的表现明显低于Phrase-BERT。
此外,短语BERT的两个目标是互补的:仅使用释义数据训练和使用上下文数据训练的Phrase-BERT都比Phrase-BERT效果差。

Phrase-BERT-phrase在诱导词汇多样性嵌入空间方面也较差,高LCS精度。同时,仅使用上下文目标(Phrase-BERT-context)进行微调会产生最高的词汇多样性,但代价是语义空间更差,这可能是因为提取的上下文中的内容不同。
主题模型实验:
已开源至https://github.com/sf-wa-326/phrase-bert-topic-model
















 1111
1111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









