







1、用户输入一个数字,并计算这个数字的平方根:


关键:使用指数运算符 ** 来计算该数的平方根。
该程序只适用于正数。负数和复数可以使用以下的方式:

说明:在使用print函数输出时,也可以对字符串内容进行格式化处理,上面print函数中的字符串%1.f是一个占位符,稍后会由一个float类型的变量值替换掉它。同理,如果字符串中有%d,后面可以用一个int类型的变量值替换掉它,而%s会被字符串的值替换掉。除了这种格式化字符串的方式外,还可以用下面的方式来格式化字符串,其中{f:.1f}和{c:.1f}可以先看成是{f}和{c},表示输出时会用变量f和变量c的值替换掉这两个占位符,后面的:.1f表示这是一个浮点数,小数点后保留1位有效数字。
另外一种输出方法: print('公鸡: %d只, 母鸡: %d只, 小鸡: %d只' % (x, y, z))
直接%(),括号内放着要输出的变量名即可。上面的引号是单引号或者双引号都可以。
2、求解二次方程,二次方程式 ax**2 + bx + c = 0 ,a、b、c 用户提供,为实数,a ≠ 0

3、如何生成一个随机数:
import random
print(random.randint(0,9))
#也就是可以使用random模块中的randint()函数来生成随机数,函数返回数字N,0<=N<=9,包含0和9
也可以这样,利用随机数来计算: first = randint(1, 6) + randint(1, 6)
4、交换变量x,y
除了像别的语言一样使用临时变量,在python语言中还可以不使用临时变量,而直接写语句 x,y=y,x
其它两种方法:
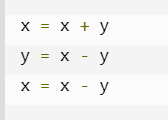
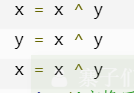
5、判断字符串是否为数字
通过创建自定义函数 is_number() 方法来判断字符串是否为数字:


关键在于,可以利用字符串能否转换为float类型从而可以判断是不是数字型的。然后就是判断其它的特殊情况。
python中的 一些其它方法:

6、Python 获取最大值函数


关键在于max函数对列表和元组也可以使用!
7、Python 中虽然可能出现 ++i 这种前缀形式的写法,但是它并没有“++”自增操作符,此处只是两个“+”(正数符号)的叠加而已,至于后缀形式的“++”,则完全不支持(SyntaxError: invalid syntax)。那么Python 为什么不支持 i++ 自增语法?(PS:此处自增指代“自增和自减”,下同)
首先,Python 当然可以实现自增效果,即写成i+=1或者i=i+1,这在其它语言中也是通用的。
虽然 Python 在底层用了不同的魔术方法(__add__()和__iadd__())来完成计算,但表面上的效果完全相同。
为什么上面的两种写法会胜过 i++,成为 Python 的最终选择呢?
因为Python 的整数是不可变类型





稍微小结下:Python 不支持自增操作符,一方面是因为它的整数是不可变类型的一等公民,自增操作(++)若要支持,则会带来歧义;另一方面主要因为它有更合适的实现,即可迭代对象,对遍历操作有很好的支持。
8、打印九九乘法表:

关键在于输出格式的控制,通过指定end参数的值,可以取消在末尾输出回车符,实现不换行。
for i in range(1, 10):
for j in range(1, i+1):
print('{ }x{ }={ }\t'.format(j, i, i*j), end=' ')
print()
类似的还有:print(n1, "," ,n2, end=" , ") 输出也就是n1,n2, 也就是最终结尾是,为结尾,而不是print函数默认的换行
9、在python中求一个数的位数,可以有更简便的方法:
n=len(str(num)) num本来是int类型的,然后将其强制转化为字符串类型,然后再利用字符串类型的函数,直接可以求出字符串类型的长度。
10、使用python将十进制转化成二进制、八进制、十六进制:python中直接有相对应的函数的
dec = int(input("输入数字:"))
bin(dec): 可直接将十进制转化为二进制
oct(dec): 可直接将十进制转化为八进制
hex(dec): 可直接将十进制转化为十六进制
还有一些其它函数: ord(字符变量名):可以得到对应字符的ASCII码值
chr(数值变量名):可以得到数值(ASCII码值)对应的字符
也就是上面这两个函数可以快速实现ASCII码与字符相互转换
11、求两个正数的最大公约数: 可以利用辗转相除的方法实现


12、最小公倍数的求法:
a和b的乘积,然后除以最大公约数,结果就是最小公倍数
13、生成指定年月的日历:
利用日历模块里的显示日历函数
import calendar #引入日历模块
yy = int(input("输入年份: "))
mm = int(input("输入月份: "))
print(calendar.month(yy,mm)) #利用这个就可以打印出对应年月的日历,但是千万注意,输入到month函数中的元素的类型是数值类型,不能直接把输入进来的字符串类型直接传入。

但是这个代码的缺点就是,我们日常用的日历都是星期天在前的。所以改进代码,应该加一行用以将星期天放在首位。
改进代码如下:

python中还有可以快速得到某一年某个月的天数以及该月的第一天是星期几:
也是calendar模块中的函数monthrange(year,month):

python中获取昨天的日期:
可以通过导入 datetime 模块来获取昨天的日期

也可以有更简洁的写法:

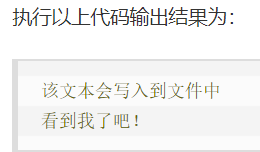
14、Python 文件 IO:演示Python基本的文件操作,包括 open,read,write
#写文件
with open("test.txt","wt") as out_file: #文件对象
out_file.write("该文本会写入到文件中\n看到我了吧!")
#读文件
with open("test.txt","rt") as in_file:
text=in_file.read()
print(text)
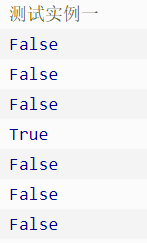
15、关于Python字符串的判断的函数:


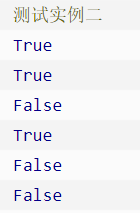
16、字符串大小写转换
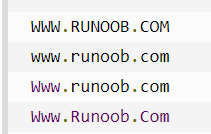
capitalize():只把整个字符串中的第一个字母转化成大写字母,其余仍保持原样
而title()则是把在字符串中的每个单词的第一个字母都转化成大写,其余字母保持原样
17、list(也就是列表)中的常用操作实例:




列表通过符号来进行链接和根据符号来进行分割非常有用也非常重要!


也就是当列表中的每个元素是字典时:

也就是可以人为的设置条件来去除掉列表中的一些元素:

18、给定一个字符串,然后判断指定的字符串是否存在于该字符串中:
def check(string,str_sub):
if(string.find(sub_str)==-1):
print("不存在!")
else:
print("存在!")
string = "www.runoob.com"
sub_str ="runoob"
check(string, sub_str)关键在于知道说:字符串中直接就有find()函数可以用来查找子串存不存在
19、移除字符串中的指定字符:
test_str = "Runoob"
# 输出原始字符串
print ("原始字符串为 : " + test_str)
# 移除第三个字符 n
new_str = ""
for i in range(0, len(test_str)):
if i != 2:
new_str = new_str + test_str[i]
print ("字符串移除后为 : " + new_str)第一种方法是,利用for循环,来移除掉字符,一个一个加上字符。
还有一种方法,可以直接使用replace()函数,用字符串把对应位置的字符串替换掉

20、查找列表中最大的元素:
list1=[10,20,3,45,99]
list1.sort()
print("最大元素为:",list1[-1])关键在于列表中有一个sort()函数可以自动去按照从小到大的顺序排序,然后取最后一个元素就好了
也可以用max()方法,max()方法也可以对列表使用,然后可以直接返回列表中最大的元素。
list1=[10,20,1,45,99]
print("最大元素为:",max(list1))查找列表中最小值时也是使用的同样的方法。
21、对于想要使用列表中的元素,也可以写下面的话:
list1=[11,5,17,18,23]
for elle in range(0,len(list1)):
total=total + list1[ele]
22、python中计算列表中元素的和:
可以直接用sum函数求解,sum(list)可以直接得到列表元素的和。
23、计算元素在列表中出现的次数:可以直接使用count()函数,
list.count(x):会直接返回元素为x在列表list中出现的次数。
24、复制列表:有好几种方法
方法一:list2=list1[:] 直接把list1中所有元素的值给list2
方法二:使用extend()方法
list2=[ ]
list2.extend(list1) 然后list2中就有了list1的所有元素
方法三:使用list()方法:
list2=list(list1) 也就得到了list1中的全部元素
25、对于列表中的元素,可以直接:
for i in list:
26、翻转列表:
list.reverse() 列表调用reverse()方法就可以得到翻转后的列表了
27、将列表中的指定位置的两个元素对调:
可以直接将列表中的两个元素对调,这样列表里的元素就相当于是调换了:
list[pos1],list[pos2]=list[pos2],list[pos1]
也可以先把对应位置上的元素弄出来,然后再重新插入交换后的元素。

28、想要创建一个1到30的列表,可以通过range()来写:
lists=list(range(1,31)) 这样就不用一个一个赋值了
也可以这样写:lists=[x for x in range(1,31)]
29、 约瑟夫生者死者小游戏




30、五人分鱼
A、B、C、D、E 五人在某天夜里合伙去捕鱼,到第二天凌晨时都疲惫不堪,于是各自找地方睡觉。
日上三杆,A 第一个醒来,他将鱼分为五份,把多余的一条鱼扔掉,拿走自己的一份。
B 第二个醒来,也将鱼分为五份,把多余的一条鱼扔掉拿走自己的一份。 。
C、D、E依次醒来,也按同样的方法拿鱼。
问他们台伙至少捕了多少条鱼?
关键在于,每次都是x-1是5的倍数,当什么时候不是5的倍数时,就不行。因此,从1开始枚举,然后每个数要进行无论检验,每轮检验后这个数就取原来的五分之四,整个过程都没问题那么就是满足条件的值,打印出结果即可:
fish=1
while True:
total,enough=fish,True
for i in range(5):
if(total-1)%5==0:
total=(total-1)//5*4
else:
enough=False
break
if enough:
printf("总共有{}条鱼".format(fish)
break
fish+=1
31、对字符串切片以及翻转:
方法一:可以直接利用切片来翻转,对头部切片进行翻转,尾部切片翻转时也是一样的。
input='Runoob'
Lfirst=input[0:2]
Lsecond=input[2:]
print("头部切片翻转:",(Lsecond+Lfirst))方法二:也可以利用索引进行切片操作,可包含三个参数:

可以输入:input=input[ : :-1] 就可以实现对列表的整体翻转

32、字典中按照键(key)或值(value)对字典进行排序:
(1)按键排序:
key_value={} #声明字典
key_value[2]=56
key_value[1]=2
key_value[5]=12
key_value[4]=24
key_value[6]=18
key_value[3]=323
for i in sorted(key_value):
print((i,key_value[i]),end=" ")直接使用sorted()函数就可以对key_value进行排序,sorted()返回一个迭代器,注意一下打印时的格式,如果要定义end的格式的话,前面的部分是要整体加括号的。

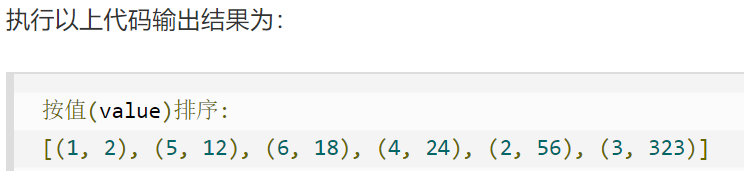
(2)按值排序:
还是上面的字典,但是如果按值排序的话,要写成下面的形式:
print( sorted(key_value.items() , key=lambda kv:(kv[1],kv[0]) ) )
(3)对字典列表进行排序
lis=[{"name":"Taobao","age":100},
{"name":"Runoob","age":7},
{"name":"Google","age":100},
{"name":"Wiki","age":200}]
print( sorted(lis,key=lambda i:i['age']) )
#也可以先按age排序,再按name排序
print(sorted(lis,key=lamba i:(i['age'],i['name']) ) )
#也可以按age降序排序:
print(sorted(lis,key=lambda i:i['age],reverse=True) )
33、计算字典中值的和:
myDict={'a':100,'b':200,'c':300}
for i in myDict:
sum=sum+myDict[i]
i in myDict: 即可取得字典中所有的键
34、移除字典中的键值对:
例如:
test_dict={"Runoob":1, "Google":2, "Tabao":3, "Zhihu":4 }
方法一:
del test_dict['Zhihu']
直接移除字典的那一个条目即可
方法二:也可以使用pop()移除:test_dict.pop('Zhihu')
同时,如果使用pop()移除没有的key不会发生异常,并且我们还可以自定义提示信息:
removed_value = test_dict.pop( 'Baidu' , '没有该键(key)')
方法三:使用items()移除:
new_dict={ key:val for key , val in test_dict.items( ) if key!='Zhihu' }
也就是新创建一个字典,只是这个字典中的条目会去除掉需要去除掉的元素,也就相当于是移除掉对应元素了
35、合并字典:
方法一:使用update()方法,第二个参数可以合并第一个参数:
例如:
dict1={'a':10, 'b':8}
dict2={'d':6, 'c':4}
dict2.uodate(dict1) #实现了将dict1加到了dict2后面
print(dict2)
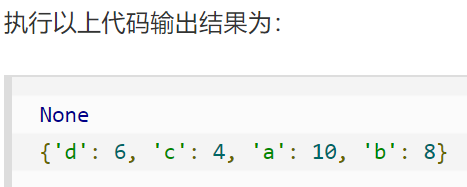
方法二:使用**,从而函数将参数以字典的形式导入
res={**dict1, **dict2}
print(res)
然后也得到了上面的运行结果
36、

37、循环结构就是程序中控制某条或某些指令重复执行的结构。在Python中构造循环结构有两种做法,一种是for-in循环,一种是while循环。
range的用法非常灵活,下面给出了一个例子:
range(101):可以用来产生0到100范围的整数,需要注意的是取不到101。
range(1, 101):可以用来产生1到100范围的整数,相当于前面是闭区间后面是开区间。
range(1, 101, 2):可以用来产生1到100的奇数,其中2是步长,即每次数值递增的值。
range(100, 0, -2):可以用来产生100到1的偶数,其中-2是步长,即每次数字递减的值。
知道了这一点,我们可以用下面的代码来实现1~100之间的偶数求和。

当然,也可以通过在循环中使用分支结构的方式来实现相同的功能,代码如下所示。

但是很明显整个程序的运行过程就变得太复杂了。
38、依次打印出如下的三角形图案:






主要是中间那一个有点难想,但其实整个就是一个5*5的下三角,利用条件判断语句可以实现;然后有了这个的基础,可以很快解决下面这个,也就是在上面的基础上继续在后面加上*号,那么也就是每行的总个数不再规则,但也和i有着规律。
39、说明: Python的math模块中其实已经有一个名为factorial函数实现了阶乘运算,事实上求阶乘并不用自己定义函数。
40、函数的参数:
Python中的函数与其他语言中的函数还是有很多不太相同的地方,其中一个显著的区别就是Python对函数参数的处理。在Python中,函数的参数可以有默认值,也支持使用可变参数,所以Python并不需要像其他语言一样支持函数的重载,因为我们在定义一个函数的时候可以让它有多种不同的使用方式,下面是两个小例子。
from random import randint
def roll_dice(n=2):
"""摇色子"""
total = 0
for _ in range(n):
total += randint(1, 6)
return total
def add(a=0, b=0, c=0):
"""三个数相加"""
return a + b + c
# 如果没有指定参数那么使用默认值摇两颗色子
print(roll_dice())
# 摇三颗色子
print(roll_dice(3))
print(add())
print(add(1))
print(add(1, 2))
print(add(1, 2, 3))
# 传递参数时可以不按照设定的顺序进行传递
print(add(c=50, a=100, b=200)) 我们给上面两个函数的参数都设定了默认值,这也就意味着如果在调用函数的时候如果没有传入对应参数的值时将使用该参数的默认值,所以在上面的代码中我们可以用各种不同的方式去调用add函数,这跟其他很多语言中函数重载的效果是一致的。但是如果是在其他函数中,则需要重复写好多个函数,这样才能对应上相关的函数。
其实上面的add函数还有更好的实现方案,因为我们可能会对0个或多个参数进行加法运算,而具体有多少个参数是由调用者来决定,我们作为函数的设计者对这一点是一无所知的,因此在不确定参数个数的时候,我们可以使用可变参数,代码如下所示。
# 在参数名前面的*表示args是一个可变参数
def add(*args):
total = 0
for val in args:
total += val
return total
# 在调用add函数时可以传入0个或多个参数
print(add())
print(add(1))
print(add(1, 2))
print(add(1, 2, 3))
print(add(1, 3, 5, 7, 9))但是要注意:也正是由于由于Python没有函数重载的概念,那么后面的定义会覆盖之前的定义,也就意味着两个函数同名函数实际上只有一个是存在的。
但是对于不同模块中的同名函数是允许的,因为我们可以通过模块来管理函数,在使用函数的时候我们通过import关键字导入指定的模块就可以区分到底要使用的是哪个模块中的foo函数。例如:
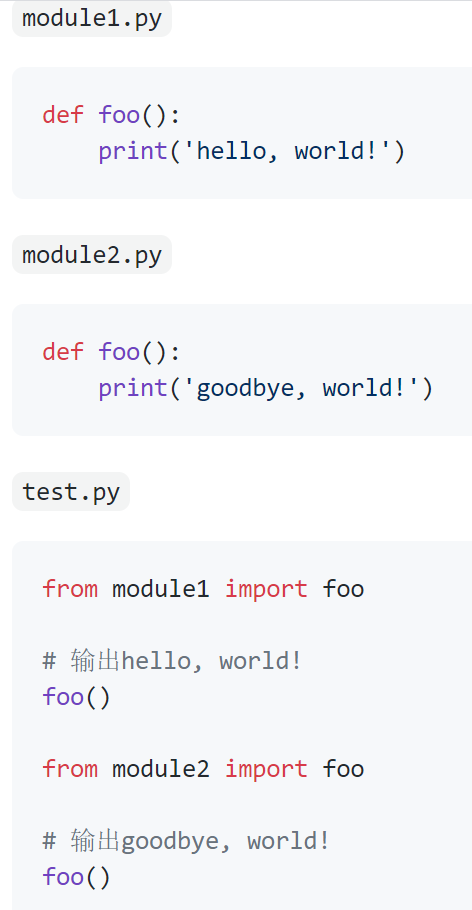
当然,也可以按照如下所示的方式来区分到底要使用哪一个foo函数:
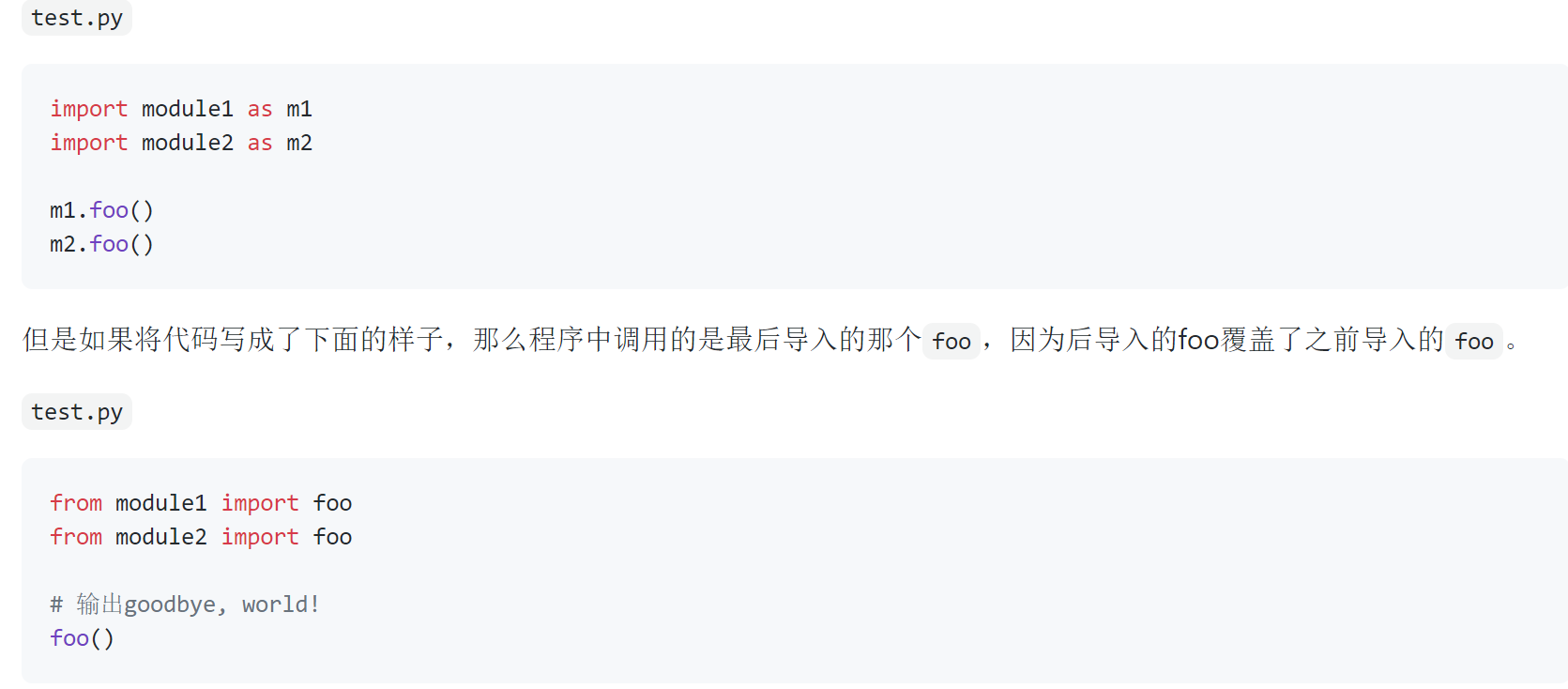
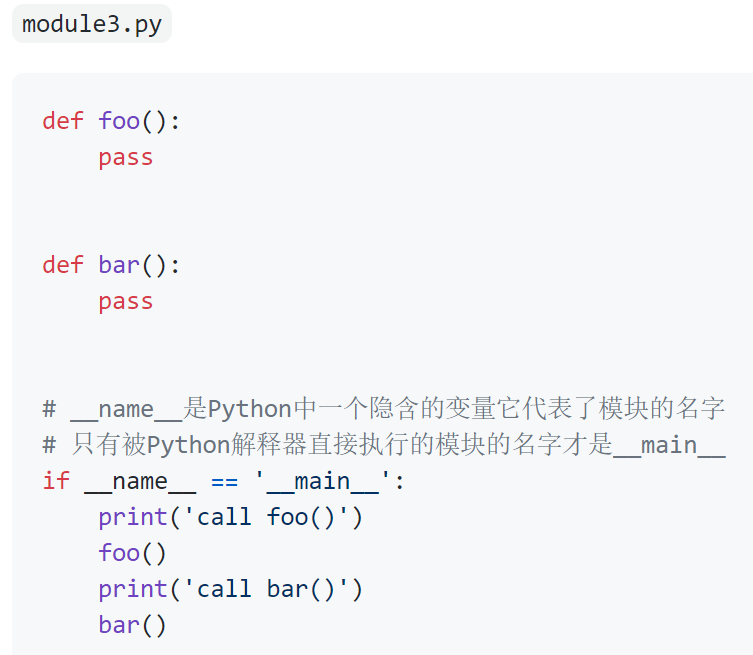
需要说明的是,如果我们导入的模块除了定义函数之外还中有可以执行代码,那么Python解释器在导入这个模块时就会执行这些代码,事实上我们可能并不希望如此,因此如果我们在模块中编写了执行代码,最好是将这些执行代码放入如下所示的条件中,这样的话除非直接运行该模块,if条件下的这些代码是不会执行的,因为只有直接执行的模块的名字才是"__main__"。

41、变量的作用域:
事实上,Python查找一个变量时会按照“局部作用域”、“嵌套作用域”、“全局作用域”和“内置作用域”的顺序进行搜索,前三者我们在上面的代码中已经看到了,所谓的“内置作用域”就是Python内置的那些标识符,我们之前用过的input、print、int等都属于内置作用域。
看看下面这段代码,我们希望通过函数调用修改全局变量a的值,但实际上下面的代码是做不到的:
def foo():
a = 200
print(a) # 200
if __name__ == '__main__':
a = 100
foo()
print(a) # 100 在调用foo函数后,我们发现a的值仍然是100,这是因为当我们在函数foo中写a = 200的时候,是重新定义了一个名字为a的局部变量,它跟全局作用域的a并不是同一个变量,因为局部作用域中有了自己的变量a,因此foo函数不再搜索全局作用域中的a。如果我们希望在foo函数中修改全局作用域中的a,代码如下所示:
def foo():
global a
a = 200
print(a) # 200
if __name__ == '__main__':
a = 100
foo()
print(a) # 200 我们可以使用global关键字来指示foo函数中的变量a来自于全局作用域,如果全局作用域中没有a,那么下面一行的代码就会定义变量a并将其置于全局作用域。同理,如果我们希望函数内部的函数能够修改嵌套作用域中的变量,可以使用nonlocal关键字来指示变量来自于嵌套作用域。
在实际开发中,我们应该尽量减少对全局变量的使用,因为全局变量的作用域和影响过于广泛,可能会发生意料之外的修改和使用,除此之外全局变量比局部变量拥有更长的生命周期,可能导致对象占用的内存长时间无法被垃圾回收。事实上,减少对全局变量的使用,也是降低代码之间耦合度的一个重要举措,同时也是对迪米特法则的践行。减少全局变量的使用就意味着我们应该尽量让变量的作用域在函数的内部,但是如果我们希望将一个局部变量的生命周期延长,使其在定义它的函数调用结束后依然可以使用它的值,这时候就需要使用闭包,这个我们在后续的内容中进行讲解。
说了那么多,其实结论很简单,从现在开始我们可以将Python代码按照下面的格式进行书写,这一点点的改进其实就是在我们理解了函数和作用域的基础上跨出的巨大的一步。
def main():
# Todo: Add your code here
pass
if __name__ == '__main__':
main()
42、字符串中的转义字符
可以在字符串中使用\(反斜杠)来表示转义,也就是说\后面的字符不再是它原来的意义,例如:\n不是代表反斜杠和字符n,而是表示换行;而\t也不是代表反斜杠和字符t,而是表示制表符。所以如果想在字符串中表示'要写成\',同理想表示\要写成\\。
在\后面还可以跟一个八进制或者十六进制数来表示字符,例如\141和\x61都代表小写字母a,前者是八进制的表示法,后者是十六进制的表示法。也可以在\后面跟Unicode字符编码来表示字符,例如\u9a86\u660a代表的是中文“骆昊”。
如果不希望字符串中的\表示转义,我们可以通过在字符串的最前面加上字母r来加以说明,也就是完全照实输出:

43、python中字符串的运算符:
Python为字符串类型提供了非常丰富的运算符,我们可以使用+运算符来实现字符串的拼接,可以使用*运算符来重复一个字符串的内容,可以使用in和not in来判断一个字符串是否包含另外一个字符串(成员运算),我们也可以用[]和[:]运算符从字符串取出某个字符或某些字符(切片运算)
在Python中,我们还可以通过一系列的方法来完成对字符串的处理:
str1 = 'hello, world!'
# 通过内置函数len计算字符串的长度
print(len(str1)) # 13
# 获得字符串首字母大写的拷贝
print(str1.capitalize()) # Hello, world!
# 获得字符串每个单词首字母大写的拷贝
print(str1.title()) # Hello, World!
# 获得字符串变大写后的拷贝
print(str1.upper()) # HELLO, WORLD!
# 从字符串中查找子串所在位置
print(str1.find('or')) # 8
print(str1.find('shit')) # -1
# 与find类似但找不到子串时会引发异常
# print(str1.index('or'))
# print(str1.index('shit'))
# 检查字符串是否以指定的字符串开头
print(str1.startswith('He')) # False
print(str1.startswith('hel')) # True
# 检查字符串是否以指定的字符串结尾
print(str1.endswith('!')) # True
# 将字符串以指定的宽度居中并在两侧填充指定的字符
print(str1.center(50, '*'))
# 将字符串以指定的宽度靠右放置左侧填充指定的字符
print(str1.rjust(50, ' '))
str2 = 'abc123456'
# 检查字符串是否由数字构成
print(str2.isdigit()) # False
# 检查字符串是否以字母构成
print(str2.isalpha()) # False
# 检查字符串是否以数字和字母构成
print(str2.isalnum()) # True
str3 = ' jackfrued@126.com '
print(str3)
# 获得字符串修剪左右两侧空格之后的拷贝
print(str3.strip())
44、我们还可以使用列表的生成式语法来创建列表:
f = [x for x in range(1, 10)]
print(f)
f = [x + y for x in 'ABCDE' for y in '1234567']
print(f)
# 用列表的生成表达式语法创建列表容器
# 用这种语法创建列表之后元素已经准备就绪所以需要耗费较多的内存空间
f = [x ** 2 for x in range(1, 1000)]
print(sys.getsizeof(f)) # 查看对象占用内存的字节数
print(f)
# 请注意下面的代码创建的不是一个列表而是一个生成器对象
# 通过生成器可以获取到数据但它不占用额外的空间存储数据
# 每次需要数据的时候就通过内部的运算得到数据(需要花费额外的时间)
f = (x ** 2 for x in range(1, 1000))
print(sys.getsizeof(f)) # 相比生成式生成器不占用存储数据的空间
print(f)
for val in f:
print(val)
45、有一个非常值得探讨的问题,我们已经有了列表这种数据结构,为什么还需要元组这样的类型呢?
- 元组中的元素是无法修改的,事实上我们在项目中尤其是多线程环境(后面会讲到)中可能更喜欢使用的是那些不变对象(一方面因为对象状态不能修改,所以可以避免由此引起的不必要的程序错误,简单的说就是一个不变的对象要比可变的对象更加容易维护;另一方面因为没有任何一个线程能够修改不变对象的内部状态,一个不变对象自动就是线程安全的,这样就可以省掉处理同步化的开销。一个不变对象可以方便的被共享访问)。所以结论就是:如果不需要对元素进行添加、删除、修改的时候,可以考虑使用元组,当然如果一个方法要返回多个值,使用元组也是不错的选择。
- 元组在创建时间和占用的空间上面都优于列表。我们可以使用sys模块的getsizeof函数来检查存储同样的元素的元组和列表各自占用了多少内存空间,这个很容易做到。我们也可以在ipython中使用魔法指令%timeit来分析创建同样内容的元组和列表所花费的时间。
46、Python中的集合跟数学上的集合是一致的,不允许有重复元素,而且可以进行交集、并集、差集等运算。



说明: Python中允许通过一些特殊的方法来为某种类型或数据结构自定义运算符(后面的章节中会讲到),上面的代码中我们对集合进行运算的时候可以调用集合对象的方法,也可以直接使用对应的运算符,例如&运算符跟intersection方法的作用就是一样的,但是使用运算符让代码更加直观。
47、
# 创建字典的字面量语法
scores = {'骆昊': 95, '白元芳': 78, '狄仁杰': 82}
print(scores)
# 创建字典的构造器语法
items1 = dict(one=1, two=2, three=3, four=4)
# 通过zip函数将两个序列压成字典
items2 = dict(zip(['a', 'b', 'c'], '123'))
# 创建字典的推导式语法
items3 = {num: num ** 2 for num in range(1, 10)}
print(items1, items2, items3)
# 通过键可以获取字典中对应的值
print(scores['骆昊'])
print(scores['狄仁杰'])
# 对字典中所有键值对进行遍历
for key in scores:
print(f'{key}: {scores[key]}')
# 更新字典中的元素
scores['白元芳'] = 65
scores['诸葛王朗'] = 71
scores.update(冷面=67, 方启鹤=85)
print(scores)
if '武则天' in scores:
print(scores['武则天'])
print(scores.get('武则天'))
# get方法也是通过键获取对应的值但是可以设置默认值
print(scores.get('武则天', 60))
# 删除字典中的元素
print(scores.popitem())
print(scores.popitem())
print(scores.pop('骆昊', 100))
# 清空字典
scores.clear()
print(scores)48、设计一个函数返回传入的列表中最大和第二大的元素的值。

49、创建出需要的对象并向对象发出各种各样的消息,多个对象的协同工作最终可以让我们构造出复杂的系统来解决现实中的问题。
类是抽象的概念,而对象是具体的东西。在面向对象编程的世界中,一切皆为对象,对象都有属性和行为,每个对象都是独一无二的,而且对象一定属于某个类(型)。当我们把一大堆拥有共同特征的对象的静态特征(属性)和动态特征(行为)都抽取出来后,就可以定义出一个叫做“类”的东西。
在Python中可以使用class关键字定义类,然后在类中通过之前学习过的函数来定义方法,这样就可以将对象的动态特征描述出来,代码如下所示。

写在类中的函数,我们通常称之为(对象的)方法,这些方法就是对象可以接收的消息。
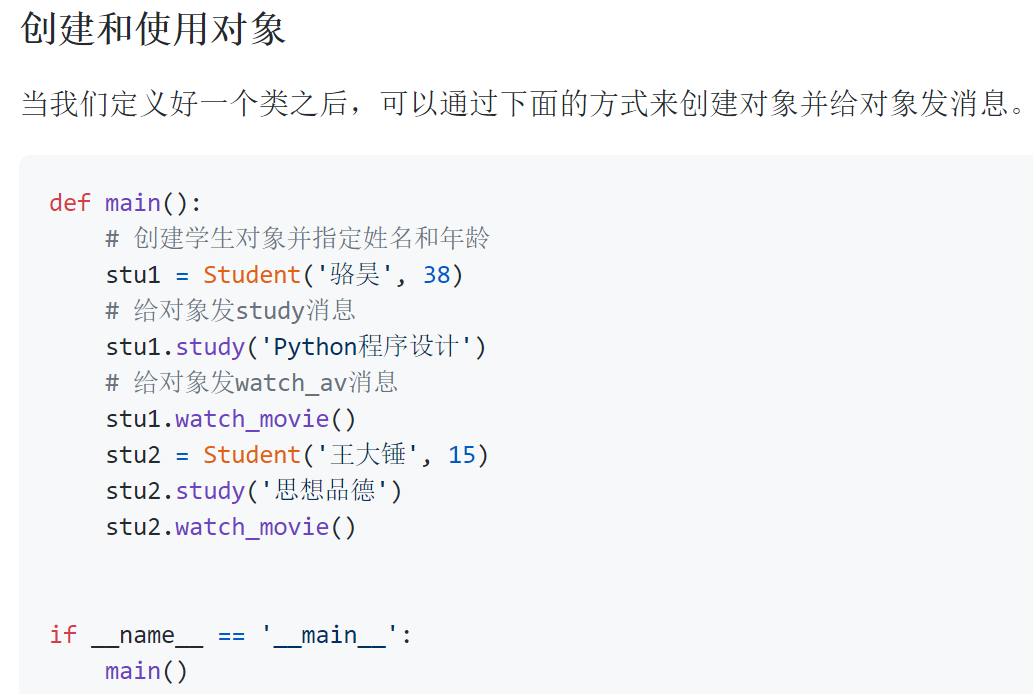
在Python中,属性和方法的访问权限只有两种,也就是公开的和私有的,如果希望属性是私有的,在给属性命名时可以用两个下划线作为开头:
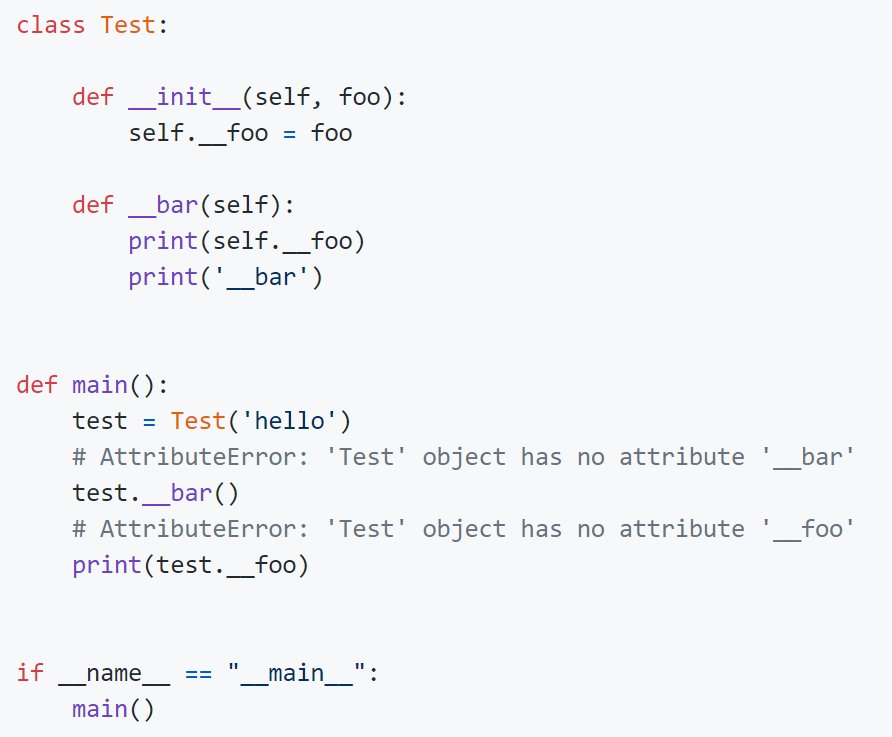
但是,Python并没有从语法上严格保证私有属性或方法的私密性,它只是给私有的属性和方法换了一个名字来妨碍对它们的访问,事实上如果你知道更换名字的规则仍然可以访问到它们,下面的代码就可以验证这一点。之所以这样设定,可以用这样一句名言加以解释,就是"We are all consenting adults here"。因为绝大多数程序员都认为开放比封闭要好,而且程序员要自己为自己的行为负责。

在实际开发中,我们并不建议将属性设置为私有的,因为这会导致子类无法访问(后面会讲到)。所以大多数Python程序员会遵循一种命名惯例就是让属性名以单下划线开头来表示属性是受保护的,本类之外的代码在访问这样的属性时应该要保持慎重。这种做法并不是语法上的规则,单下划线开头的属性和方法外界仍然是可以访问的,所以更多的时候它是一种暗示或隐喻。
例如下面定义一个类描述数字时钟:
from time import sleep
class Clock(object):
def __init__(self,hour=0,minute=0,second=0):
self._hour = hour
self._minute = minute
self._second = second
def run(self):
self.second+=1
if self._second == 60:
self._second=0
self._minute+=1
if self._minute==60:
self._minute=0
self.hour+=1
if self._hour==24:
self._hour==0
def show(self):
return '%02d:%02d:%02d'%(self._hour,self._minute,self._second)
def main():
clock=Clock(23,59,58)
while True:
print(clock.show())
sleep(1)
clock.run()
if __name__=='__main__':
main()
定义一个类描述平面上的点并提供移动点和计算到另一个点距离的方法。

50、@property装饰器:
之前我们讨论过Python中属性和方法访问权限的问题,虽然我们不建议将属性设置为私有的,但是如果直接将属性暴露给外界也是有问题的,比如我们没有办法检查赋给属性的值是否有效。我们之前的建议是将属性命名以单下划线开头,通过这种方式来暗示属性是受保护的,不建议外界直接访问,那么如果想访问属性可以通过属性的getter(访问器)和setter(修改器)方法进行对应的操作。如果要做到这点,就可以考虑使用@property包装器来包装getter和setter方法,使得对属性的访问既安全又方便,代码如下所示。
from math import sqrt
class Point(object):
def __init__(self,x=0,y=0):
self.x=x
self.y=y
def distance(self,other):
dx=self.x-other.x
dy=self.y-other.y
return sqrt(dx**2+dy**2)
class Person(object):
def __init__(self):
self._name = name
self._age = age
#访问器:getter方法
@property
def name(self):
return self._name
def age(self):
return self._age
#修改器 setter方法
@age.setter
def age(self,age):
self.age=age
def play(self):
if self._age<=16:
print('%s正在玩飞行棋.'%self._name)
else:
print("%s正在玩斗地主"%self._name)
def main():
person=Person('王大锤',12)
person.play()
person.age=22
person.play()
if __name__=='__main__':
main()51、__slots__魔法:
我们讲到这里,不知道大家是否已经意识到,Python是一门动态语言。通常,动态语言允许我们在程序运行时给对象绑定新的属性或方法,当然也可以对已经绑定的属性和方法进行解绑定。但是如果我们需要限定自定义类型的对象只能绑定某些属性,可以通过在类中定义__slots__变量来进行限定。需要注意的是__slots__的限定只对当前类的对象生效,对子类并不起任何作用。
class Person(object):
# 限定Person对象只能绑定_name, _age和_gender属性
__slots__ = ('_name', '_age', '_gender')
def __init__(self, name, age):
self._name = name
self._age = age52、Python还可以在类中定义类方法,类方法的第一个参数约定名为cls,它代表的是当前类相关的信息的对象(类本身也是一个对象,有的地方也称之为类的元数据对象),通过这个参数我们可以获取和类相关的信息并且可以创建出类的对象,代码如下所示。
from time import time,localtime,sleep
class Clock(object):
def __init__(self,hour=0,minute=0,second=0):
self._hour=hour
self._minute=minute
self._second=second
@classmethod
def now(cls):
ctime=locatetime(time())
return cls(cstime.tm_hour,ctime.tm_min,ctime.tm_sec)
#类自身的静态方法:
def show(self):
return '%02d:%02d:%02d'%(self._hour,self._minute,self._second)
53、子类在继承了父类的方法后,可以对父类已有的方法给出新的实现版本,这个动作称之为方法重写(override)。通过方法重写我们可以让父类的同一个行为在子类中拥有不同的实现版本,当我们调用这个经过子类重写的方法时,不同的子类对象会表现出不同的行为,这个就是多态(poly-morphism)。下面是继承的相关写法:
class Person(object):
def __init__(self,name,age):
self._name=name
self._age=age
class Student(Person): #继承的话,参数要写成父类的名字
def __init__(self,name,age,grade):
super().__init__(name,age)
self._grade=grade
下面是关于多态的相关示例:
from abc import ABCMeta,abstractmethod
class Pet(object,metaclass=ABCMeta):
def __init__(self,nickname):
self._nickname=nickname
def make_voice(self):
pass #空在这里有利于实现抽象和继承
#子类Dog继承父类Pet
class Dog(Pet):
def make_voice(self):
print('%s:汪汪汪...'%self._nickname)
#子类Cat继承父类Pet
class Cat(Pet):
def make_voice(self):
print('%s喵喵喵'%self._nickname)
def main():
pets=[Dog('旺财'),Cat('凯蒂'),Dog('大黄')]
for pet in pets:
pet.make_voice()
if __name__=='__mian__':
main()
在上面的代码中,我们将Pet类处理成了一个抽象类,所谓抽象类就是不能够创建对象的类,这种类的存在就是专门为了让其他类去继承它。Python从语法层面并没有像Java或C#那样提供对抽象类的支持,但是我们可以通过abc模块的ABCMeta元类和abstractmethod包装器来达到抽象类的效果,如果一个类中存在抽象方法那么这个类就不能够实例化(创建对象)。上面的代码中,Dog和Cat两个子类分别对Pet类中的make_voice抽象方法进行了重写并给出了不同的实现版本,当我们在main函数中调用该方法时,这个方法就表现出了多态行为(同样的方法做了不同的事情)。















 3515
3515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









