









学习内容
基本大多数的问题都可以转为词性标注问题!
这里只做记录,都是别人的回答!
常用的概念
- 什么是token
tokenization就是通常所说的分词,分出的每一个词语我们把它称为token。
链接
词性标注参考一
传统解决序列标注问题的方法包括HMM/MaxEnt/CRF等,很明显RNN很快会取代CRF的主流地位,成为解决序列标注问题的标准解决方案,那么如果使用RNN来解决各种NLP基础及应用问题,我们又该如何处理呢,下面我们就归纳一下使用RNN解决序列标注问题的一般优化思路。
对于分词、词性标注(POS)、命名实体识别(NER)这种前后依赖不会太远的问题,可以用RNN或者BiRNN处理就可以了。而对于具有长依赖的问题,可以使用LSTM、RLSTM、GRU等来处理。关于GRU和LSTM两者的性能差不多,不过对于样本数量较少时,有限考虑使用GRU(模型结构较LSTM更简单)。此外神经网络在训练的过程中容易过拟合,可以在训练过程中加入Dropout或者L1/L2正则来避免过拟合。
词性标注参考二
CRF随机场
CRF
也是类似逻辑回归的分类!
事实上,条件随机场是逻辑回归的序列化版本。逻辑回归是用于分类的对数线性模型,条件随机场是用于序列化标注的对数线性模型。
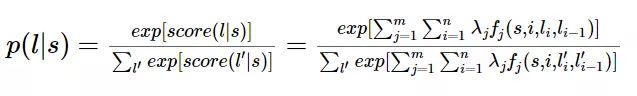















 1758
1758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









