








题目: Attentive Knowledge Graph Embedding for Personalized Recommendation
论文链接:
代码链接:
知识图谱特征学习在推荐系统中的应用步骤大致有以下三种方式:

BPThrough Time
【5】Backpropagation: theory, architectures, and applications.(BPTT)
处理数据集
【4】Personalized recommendations using knowledge graphs: A probabilistic logic programming approach
【57】 Personalized entity recommendation: A heterogeneous information network approach
Path-based
【52】 Explainable Reasoning over Knowledge Graphs for Recommendation.
AAAI (2018).
Personalized entity recommendation【57】A heterogeneous information network approach
propagation-based
【45】Ripplenet: Propagating user preferences on the knowledge
graph for recommender systems,CIKM
【50】Knowledge Graph Attention Network for Recommendation. KDD (2019).
想法
(1)怎么构建有效的子图是解决该问题的关键! 同时再从根本上说是怎么提取有效、高质量的交互信息更是关键!
(2)在写论文的时候,各个概念都是从大到小的,你必须盯住这些大概念,看它怎么映射到这些小概念的!
(3)其实一篇论文关键的就是那几个公式,把公式弄懂,模型也就懂了! 而公式要懂就得看公式里的每个项
摘要
过去:
大多数KGs要么单独的寻求user-item的路径,要么将user的偏好在KGs上传播,这两种都没有充分利用KGs,其中后者添加了噪音。
我的:
提出了AKGE(Attentive Knowledge Graph Embedding)框架,该框架用交互的方式充分利用了Attentive Graph的语义和拓扑信息!
具体说: AKGE首先自动提取具有丰富语义的用户-项目对之间的高阶子图,然后利用所提出的注意图神经网络对子图进行编码。
数据集: 三个
1. 引入
1.1path-based和propagation-based
到目前为止,有两种类型的kg-aware推荐算法得到了广泛的研究, KG-aware recommendation分为两类:path-based和propagation-based,其中前者由于只是单独的寻求user-item的线性路径不能提取KGs的语义和拓扑信息; 而后者由于迭代传播到整个KGs图,使得有很多噪音。
举个栗子来解释上面的问题:

1.2 两种方法的缺点:
目的: 推断Mike对KFC的偏爱
对于path-based方法,会提取多个高质量的paths(不超过3!)来来链接Mike和KFC,比如: (1) Mike → McDonald’s → May → KFC; (2) Mike → McDonald’s→ Amy → KFC; (3) Mike → McDonald’s → SunCity → KFC; and (4) Mike → McDonald’s → Food → KFC ,之后会对单独的路径独立编码,在最后阶段会进行aggregated来评估Mike对KFC的喜爱程度! 但是呢,如果仅仅是从图表中提取路径再聚合,不能表示Mike对KFC的强烈的关系,因为关系会随着路径长度递减! 这种弱耦合阻碍了Mike和KFC之间完整的拓扑结构! 除此之外,由于长度限制,Mike→McDonald’s→May→Amy→KFC被忽略了,这里面更是包含了Amy和May的朋友关系!
而propagation-based方法则是通过整个KG迭代地传播信息来模拟Mike和KFC之间的交互,Mike的偏好则包含了沃尔玛、麦当劳、吉姆等,这些偏好信息对我们的目标其实是“噪音”!
1.3 我们采用了什么措施解决问题:
上面的教训就是我们应该采样特定的交互的方式,因此提出了建立user-item的子图(subgraph)的方式来消减上面缺点。 子图是独立路径的非线性组合,包含了丰富的语义和拓扑信息; 同时它是图的一部分,可以避免噪音!
所以怎么构建这个子图和充分编码这个子图是解决问题的关键!
挑战一: 如何挖掘语义子图
使用BFS和DFS是不适用的,因为KGs体积较大。 所以提出了distance-aware sampling strategy,它使用省力的路径采样后组装的方式来构造子图!
挑战二:如何编码异构子图
采用GNNs(图神经网络)。同时由于KGs的异构性(各种关系,各种邻居),我们必须区分不同邻居的影响,因此设计了具有关系感知传播和注意聚合的注意图神经网络,聚合更可靠的信息
1.4 综上,我们的贡献:
(1)distance-aware sampling strategy来高效挖掘子图
(2)Attentive GNNs则充分提取异构图中的信息,消除噪音
2. Related Work
现有的基于KG的推荐方法(不是算法),可以分为三类
Direct-relation based Methods
一项研究利用KGs中直接相连的实体之间的关系来进行嵌入学习。
常见的模型可以自己去看论文,这里不再展示!
但是这些方法不能捕获user-item链接的复杂语义!
Semantic-path based Methods.
许多方法通过基于相似性的元路径来度量user-item之间的连接性。但是这种元路径是需要手工标注的。 因此后面提出了RKGE和KPRN会自动提取连接user-item的路径,然后通过RNN建模!
但是这种将user-item连接分解成单独的线性路径不可避免地导致信息丢失!
Propagation based Methods.
最近的方法很流行在KGs上迭代传播! 常见的工具是GCNs、GAT! RippleNet,但是由于异构图的特殊性,所以导致引入了很多的噪音!
3 基于注意力的知识图嵌入(根据上面的分析,肯定是三个模块)

我们的模型有三模块组成:1)子图构建——基于距离感知路径采样策略,自动挖掘语义子图以表示高阶用户项目连通性; 2)注意图神经网络(AGNN)——通过新的注意图神经网络对子图进行编码,学习实体的语义嵌入;3)多层感知器(MLP)预测——通过输入来自AGNN的学习良好的用户和项目嵌入,它使用非线性层来预测用户对项目的偏好。
Notations:
和往论文是一样的: 用户和物品:
U
=
{
u
1
,
u
2
,
⋯
,
u
n
}
U = \{ u _ { 1 } , u _ { 2 } , \cdots , u _ { n } \}
U={u1,u2,⋯,un}
I
=
{
i
1
,
i
2
,
⋯
,
i
m
}
I = \{ i _ { 1 } , i _ { 2 } , \cdots , i _ { m } \}
I={i1,i2,⋯,im}; 用户和物品交互矩阵
R
∈
R
n
×
m
R\in R ^ { n \times m }
R∈Rn×m ,矩阵里面的条目为1,那么就是user对item有interaction,否则就是没有! 而用户和物品都可以归为“entity”,都会被放入KG中
Definition 1. Knowledge Graph:
E
,
L
\mathcal{E} ,\mathcal{L}
E,L分别表示实体和链接的集合,一个KG被定义为包含了实体类型和链接类型映射函数的无向图
G
=
(
E
,
L
)
\mathcal{G}=(\mathcal{E}, \mathcal{L})
G=(E,L)!
ϕ
:
E
→
A
\phi : \mathcal{E} \rightarrow \mathcal{A}
ϕ:E→A和
φ
:
L
→
R
\varphi : \mathcal{L} \rightarrow \mathcal{R}
φ:L→R
每一个实体
e
∈
E
e \in \mathcal{E}
e∈E属于一个实体类型
ϕ
(
e
)
∈
A
\phi(e) \in \mathcal{A}
ϕ(e)∈A,统一每一个链接也会属于后者
R
\mathcal{R}
R! 同时
∣
A
∣
>
1
|\mathcal{A}| > 1
∣A∣>1,
∣
R
∣
>
1
|\mathcal{R}|>1
∣R∣>1
Definition 2. KG-based Top-N Recommendation:
对于每一个用户和KG,我们的任务就是生成一个用户感兴趣的ranked list
3.1 Subgraph Construction
采用BFS和DFS等会很耗费时间,所以我们会采用显著路径采样,之后通过组装user-item pairs之间的所有抽样路径来重新构建子图
Distance-aware Path Sampling:
meta-path是很有效的,但是需要experts来手动标注,而是路径长度也会受限。
-
核心思想是: 当前实体和候选实体如果有更短的距离,那么就会被认为有更加可靠的链接。
-
距离的定义: 平移距离模型(Translational distance models),将所有的实体映射到欧式空间,采用欧式距离来计算两个实体之间的距离!
-
训练的小技巧:同时我们会通过TransR来预训练KG中的实体。 这是一个训练的小技巧!
-
构成语义子图: 我们沿着各条路径走,并计算两两实体的距离,最终取每个路径距离之和作为该路径的距离,保留前K个路径构成语义子图
Path Assembling:
将各个路径
P
(
u
,
i
)
\mathcal{P}(u, i)
P(u,i)组合成子图,同时我们将该图表示为邻接矩阵
A
A
A! 其中里面的entries就是relation,如果为 1,那么就是这两个entities是有直接关系,否则没有直接的关系。

可以使用Mike → McDonald’s→ May → KFC作为例子!其中该矩阵是一个对称矩阵,而子图是无向图
之后我们会将邻接矩阵A输入到AGNN模块中,引导实体之间信息的传播
3.2 Attentive Graph Neural Network
gated graph neural network (GGNN) 最近由于其杰出的性能而受到关注,但是它是基于同构图的。 所以我们提出了AGNN,它由namely entity projection(实体投影), relation-aware propagation(关系感知传播), attentive aggregation(注意力聚合) and gated update(门控更新)四个部分组成。
Entity Projection:
输入: 子图
G
=
{
E
s
,
L
s
}
\mathcal{G}=\left \{ \mathcal{E}_s, \mathcal{L}_s \right \}
G={Es,Ls}和邻接矩阵
A
A
A
由于我们的图是异构图,所以为每个entity Embedding添加了entity type Embedding! 用来增强实体Embedding
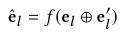
其中 e l ∈ R d e _ { l } \in R ^ { d } el∈Rd、 e l ′ ∈ R d ′ e _ { l } ^ { \prime }\in R ^ { d ^ { \prime } } el′∈Rd′分别表示了entity和entity type的嵌入! f ( x ) = σ ( W x + b ) f ( x ) = \sigma ( W x + b ) f(x)=σ(Wx+b),W和b是transformation 矩阵和偏移,加号是concat。
增加后的
e
l
e_{l}
el被用来初始化hidden state在初次传播t=0时:

除此之外,我们通过TransR对预训练的嵌入进行了初始化!
Relation-aware Propagation.
增强hidden state: 我们知道GGNN是不考虑关系语义的,因此有必要添加实体之间的关系:
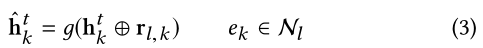
其中
r
l
,
k
∈
R
d
′
′
r_{l,k} \in \mathbb{R}^{d^{''}}
rl,k∈Rd′′是实体
e
l
e_l
el和其邻居
e
k
e_k
ek的关系,而
h
k
t
h_k^t
hkt则是
e
k
e_k
ek的在传播步骤
t
t
t 时的隐藏状态!
g
(
x
)
=
σ
(
W
x
+
b
)
g ( x ) = \sigma ( W x + b )
g(x)=σ(Wx+b)。而我们的输出
h
^
k
\hat{h}_k
h^k则是
e
k
e_k
ek的relation-aware hidden state 在传播步骤
t
t
t 时,这里聚合了
e
k
e_k
ek的各个邻居,使得AGNN能够更好的采取异构KGs。
Attentive Aggregation:
我们由上面可以得到的
h
^
k
t
\hat{h}_k^t
h^kt则是
e
k
e_k
ek的在传播步骤
t
t
t的 relation-aware hidden state 。(k是任何一个实体)
AGNN则是通过一个注意力机制聚合
e
l
e_l
el的信息。下面的公式在传播步骤
t
t
t时,
e
l
e_l
el聚合它的邻居的 relation-aware hidden state 来得到自己的在步骤
t
t
t时的信息。
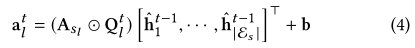
在该公式中,
a
l
t
a_l^t
alt是其邻居隐藏状态的注意力聚合,
h
^
k
t
−
1
\hat{h}_k^{t-1}
h^kt−1是其邻居的在前一次t-1传播中的关系隐藏状态; 其中
A
s
t
∈
R
∣
E
s
∣
A_{st} \in \mathbb{R}^{|\mathcal{E}_s|}
Ast∈R∣Es∣是关于
e
l
e_l
el的的
A
s
A_s
As的行向量 ,表明了在图
G
s
\mathcal{G}_s
Gs中所有和
e
l
e_l
el联系的实体(就是从整个图中抠出来的),
Q
l
t
Q_l^t
Qlt是权重向量 。对于
e
l
e_l
el而言,如果没有关系,那么
A
s
t
A_{st}
Ast和
Q
l
t
Q_l^t
Qlt会被设置为0.
计算注意力权重向量
Q
l
t
Q_l^t
Qlt,对于
e
l
e_l
el和其邻居
e
k
e_k
ek之间的权重参数,我们通过两层神经网络计算得到
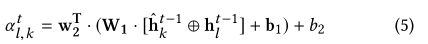
之后我们对其所有邻居归一化处理:
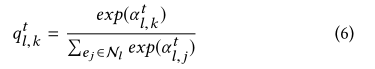
这样,就会使得更加关于显著的语义关系
Gated Update.
给定关于target entity
e
l
e_l
el的
a
l
t
a_l^t
alt,AGNN通过一种类似于门控循环单元的门控机制更新目标实体的嵌入,以更好地控制信息。具体而言, 两个门会通过调节信息的流动来得到:
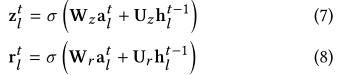
其中
z
l
t
z^t_l
zlt和
r
l
t
r_l^t
rlt分别是更新和复位门。 其它的符号都懂!
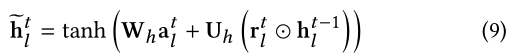
其中
e
l
(
h
~
l
t
)
e _ { l } (\tilde{h}_l^t )
el(h~lt)候选状态被输入状态
a
l
t
a_l^t
alt、原来的状态
h
l
t
−
1
h_l^{t-1}
hlt−1和reset状态创建! 其中,
r
l
t
r_l^t
rlt控制原来状态
h
l
t
−
1
h_l^{t-1}
hlt−1要被丢弃多少。
而当前状态
e
l
(
h
l
t
)
e _ { l } (h_l^t )
el(hlt)会被先前隐藏状态和候选隐藏状态的组合更新,由更新门控制:
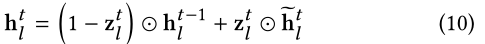
通过递归聚合邻居的信息,AGNN不仅仅是单个传播步骤(t=1)的一阶实体的链接,但是也是多个传播步骤(t > 1)的高阶链接。 迭代T步后,最终的隐藏状态就是聚合了实体、邻居并预测用户的偏好!
3.3 MLP Prediction
通过AGNN,我们能够更好的学习user u和item i,并进一步利用它们预测用户的偏好
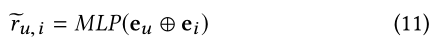
e
u
e_u
eu和
e
i
e_i
ei是user和item的嵌入!
我们采用ReLU作为hidden layers的激活函数,采用sigmoid函数作为output layer的激活函数,将估计得分控制在[0,1]范围内。
3.4 Model Optimization
Objective Function:我们将Top-N推荐任务当作一个二分类任务,target=1是有u和i有交互,反之则无。 采用负对数似然估计作为目标函数:
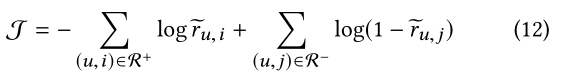
其中
R
+
\mathcal{R}^+
R+和
R
−
\mathcal{R}^-
R−表明了观察到的和没有观察到的user-item的交互。
我们将正样本和负样本(user对item不感兴趣的)的比例控制为4:1,在AGNN中通过BPTT(back propagation through time)学习参数,其它模块则是反向传播。

Complexity Analysis
构建子图: 离线获得训练数据的距离,并离线过滤远的(有阈值)!O(PM+Mlog
M)offline time。 P是path length,M是 maximum number of considered paths
对于通过AGNN的子图encoding: 主要是矩阵的乘法 ∑ t = 1 T O ( ∣ E s ∣ d 2 ) \sum_{t=1}^{T} O\left(\left|\mathcal{E}_{s}\right| d^{2}\right) ∑t=1TO(∣Es∣d2),其中其中d是隐藏状态和输入状态的嵌入大小
4 EXPERIMENTS AND ANALYSIS
四个问题:
- RQ1: Does our proposed AKGE outperform the state of-the-art recommendation methods?
- RQ2: Can AKGE provide potential explanations about user preferences towards items?
- RQ3: How do our proposed path sampling strategy, relation-aware propagation and attentive aggregation affect the performance of AKGE, respectively?
- RQ4: How do different choices of hyper-parameters affect the preformance of AKGE?
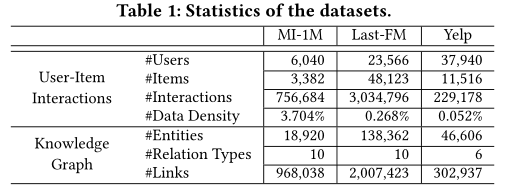
(1) MovieLens-1M 描述了用户对电影的评分在1-5之间
(2) Last-FM 音乐收听数据集
(3)Yelp 记录用户对本地企业的评级从1-5。 此外,社会关系和商业属性(例如,类别,城市)也包括在内
和【4】和【57】一样的处理数据集的方式: 如果user对item有评分,那么interaction就设置为1。 除此之外,我们会merge更多的信息放到每个数据集的KGs中。 比如电影导演、主演等
MovieLens-1M 是我们的数据集合!
评估协议: 采用了 leave-one-out的 方法,也就是最新的interaction会被作为test集,我们随机抽取100个用户没有交互过的项目,然后将测试项目在101个项目中进行排名,从而降低测试的复杂性。 采用额Hit@N和NDCC@N作为评估指标,为每个测试用户计算两个指标并计算平均分数N=10,一般来说,度量值越高,排名精度越好。
Comparison Method:

(1)普通的CF based method (2)基于KGs - CKE的直接关系方法 (3)基于语义路径的方法与KGs (4)基于KGs - KGAT的方法
参数设置:
对于AKGE,Adam是优化器
应用网格搜索{0.001,0.002,0.01,0.02} 找到一个最优的学习率;
对l2正则化系数λ的最优设置进行了搜索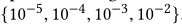
下面是经过测试后的参数:
batchsize = 256; 实体的、实体类型和关系的嵌入大小分别设置为d =128,
d
′
d'
d′ =
d
′
′
d''
d′′ = 32。 隐藏状态大小为128; MLP成分预测因子的大小设置为32; 取样的路径数目K对于每个user-item pair被设置为30,传播步骤T=2为了避免过拟合;
4.2 Performance Comparison (RQ1)

效果都有所提升!
4.3 Case Study (RQ2)

这个子图是构建
u
1
98
u_198
u198对
i
3
793
i_3793
i3793的,通过子图构建模块自动提取。其中红色的数字就是权重
4.4 AKGE (RQ3)详细研究
训练前技术的效果、 路径采样策略的影响、实体类型、关系感知传播和注意聚合的影响

4.5 Parameter Sensitivity (RQ4)
Number of Sampled Paths.
AKGE的传播步骤
AKGE的嵌入尺寸
















 1840
1840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









