








题目: Knowledge-Enhanced Hierarchical Graph Transformer Network for Multi-Behavior Recommendation
论文链接:
代码链接:https://github.com/akaxlh/KHGT
论文
-
时间戳放入到关系中,可以参考这篇《Heterogeneous graph transformer》 WWW 2020
和《Attention is all you need》 -
多行为的论文
《Graph-enhanced multi-task learning of multi-level transition dynamics for session-based recommendation》 2021 AAAI
《 Graph neural networks for social recommendation》
《Walkranker: A unified pairwise ranking model with multiple relations for item recommendation》《Knowledge-aware graph neural networks with label smoothness regularization for recommender systems》 KDD 2019
《Kgat: Knowledge graph attention network for recommendation》KDD 2019
《Multiplex behavioral relation learning for recommendation via memory augmented transformer
network》 SIGIR 2020 -
GNN RS:
《Knowledge-aware coupled graph neural network for social recommendation》AAAI 2021
《Neural graph collaborative filtering》2017 WWW
《Inductive representation learning on large graphs》2017 NIPS -
其它
《 Heterogeneous graph transformer》
想法
- 看题目就可以明白这里的主体是多行为(包括浏览,添加购物车等),所以这种框架就叫做多行为框架; 可是我的想法是,这里我们给它把这些行为也记录下来放到KG中来学习不就可以了吗
- 还有动态依赖关系? 添加时间模型? 如何处理多种行为的相互依赖关系!
- 本文是基于多行为图而建立的方法
创新
创新之处就是难点解决的方法!!
(1)time-aware 上下文考虑到了用户交互的动态特征。 方法就是用了正弦函数来计算上下文特征,信息在图上传播时,实体的embedding = 原实体 + 添加了time-aware的实体(4.1)
(2)multi-behavior graph transformer network和多行为相互注意编码器既能获得独特的行为编码又能考虑行为之间的依赖性(4.2);
摘要
难点:
现在都是基于单一类型的user-item交互来计算用户的的偏好(比如交互矩阵中把所有的行为都归纳为1), 然鹅,multi-type 用户交互行为(如浏览、添加购物车等)没有被区别对待! 要解决这个问题,需要考虑三个问题: (1)多种类型的用户交互行为的相互依赖关系 使得提取用户特有的交互方式很困难(2)将KG-aware的item关系纳入多行为推荐框架中(3)multi-typed 用户交互的动态特征。
方法:
KHGT框架,用来探索users和items在推荐系统中多种类型的交互模式。该框架建立在基于图的神经网络架构上,具体的该框架有两个任务: (1)捕获每种行为的语义(2)明确区分哪些类型的user-item交互在辅助目标行为的预测任务中更为重要。 除此之外,我们用时空编码策略来整合多模态注意力层,使学习能够反映user-item和item-item的多重合作关系的嵌入,以及潜在的交互动力学。
数据集:三个真实世界的数据集
2. introduction
详解——难点: (1) 多种类型的行为依赖的意思是: 特定类型的行为模式以一种复杂的方式相互交织,并因用户而异,就像购买和添加购物车是相同的或者是用户的负面评价和正面反馈是排斥的; 我们需要编码这种user-item的异构关系! 以分层的方式捕获复杂的内在跨类型行为依赖。 (2)KG有用(3)需要时间模型来更好地处理user-item交互的动态结构依赖关系。
过去的方法: 这些方法都是以相对独立和局部的方式考虑多类型的交互不能捕捉高阶的多重的users和items的关系。 而且怎么充分利用KG和动态的user-item没有被考虑!
详解——具体的方法: 提出了multi-behavior graph transformer networks进行递归的嵌入传播(GCN,都知道的,递归传播),以一种attentive aggregation 策略来捕获users和items的高阶行为的异构性; 为了解决行为动态性,我们则引入了time-aware 上下文; 为了编码特定类型行为表示之间的相互依赖关系,提出了一种多行为相互注意编码器,以成对的方式学习不同类型行为的依赖结构。最后,引入门控聚合层来区分特定类型关系嵌入对最终推荐的贡献。
- 我们提出了一个框架KHGT,该框架在KG-aware多行为协作图中实现高阶关系的学习。
- 在KHGT的multi-behavior modeling 范式下联合集成user和item之间的协作相似性:第一阶段,求type-specific user-item interactive patterns in a time-aware 环境中,第二阶段,利用注意力融合网络编码cross-type behavior hierarchical dependencies
3. Preliminaries
U ,I个用户和 V,J个items
User-Item Multi-Behavior Interaction Graph. G u = ( U , V , E u ) G_u=(U,V,E_u) Gu=(U,V,Eu): 和原来的知识图相比,边变成了multi-typed的K种异构关系。 在 E u E_u Eu,每条边 e i , j k e_{i,j}^k ei,jk表明了在类型k下,用户 u i u_i ui对item v j v_j vj
Knowledge-aware Item-Item Relation Graph G v = ( V , E v ) G_v = (V,E_v) Gv=(V,Ev):包含了items的边信息,考虑items的外部知识,描述跨items的多重依赖关系。 在 G v G_v Gv中,边 e j , j ′ r e_{j,j'}^r ej,j′r,表明两个实体相连以及meta-relation,这里, R \mathrm{R} R表示可以从不同方面产生的一组关系,比如 v j v_j vj和 v j ′ v_j' vj′属于同类别,相同的位置,或在相同的行为类型 k k k和与相同的用户交互。
Task Formulation:
输入:上面的两个图
输出: 基于
k
k
k的目标行为类型,推断用户
u
i
u_i
ui和item
v
j
v_j
vj的看不见的交互的概率
y
i
,
j
y_{i,j}
yi,j
4. Methodology
自己的强制理解!

端对端的KHGT

下面是每一块的详解:
4.1 Attentive Heterogeneous Message Aggregation
在这个组件中,我们的目标是在一个统一的图结构神经网络中共同捕获 multi-behavior user-item interactive patterns 和 item-item dependencies。
User-Item Multi-behavior Interaction Graph图中,深蓝线表示页面浏览(page viewPV)、深橙色购物车(Cart)、浅橙色最喜欢(Fav)、浅蓝色购买(Buy)。每条边
e
i
,
j
k
e_{i,j}^k
ei,jk表明了在类型k下,用户
u
i
u_i
ui对item
v
j
v_j
vj的交互。 在图中,统一称用户为
u
i
u_i
ui,物品item为
v
j
v_j
vj!中间的一圈表示是和用户i有关的多个items的交互!
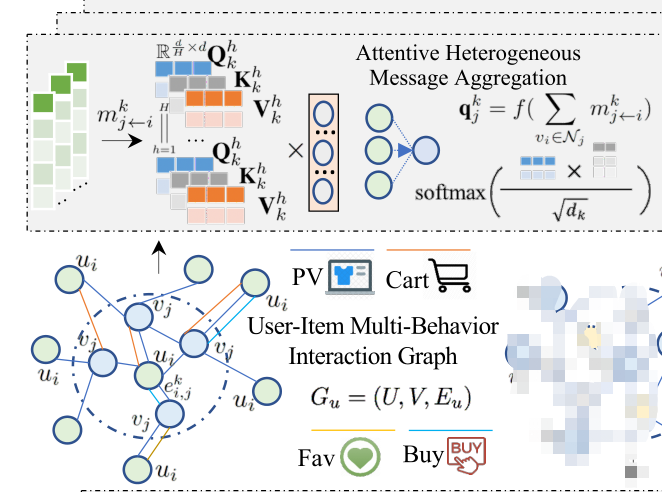
4.1.1 Multi-Behavior Interactive Pattern Encoding.
该模块旨在从users和他们交互的items之间的multi-behavior patterns中聚合异构信号。 为此,我们开发了一种增强全局行为上下文的消息传递范式下的自适应多行为自注意网络,该网络有三个模块: 由时间上下文编码、信息传播和聚合。
Temporal Information Encoding(给联系嵌入时间戳)
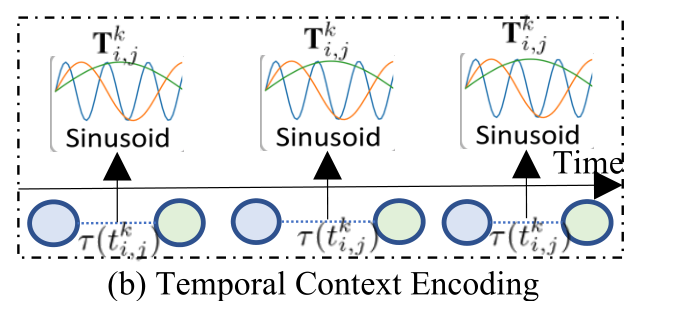
为了在时间感知场景中捕捉不同类型的user-item交互之间的影响,我们开发了一个temporal context encoding方案。具体而言,给定user
u
i
u_i
ui和item
v
j
v_j
vj在
k
k
k行为下的联系
T
i
,
j
k
T_{i,j}^k
Ti,jk,我们将它们相应的交互时间戳
t
i
,
j
k
t_{i,j}^k
ti,jk映射到时间缝隙为
τ
(
t
i
,
j
k
)
\tau (t_{i,j}^k)
τ(ti,jk),然后利用正弦函数进行嵌入
T
i
,
j
k
∈
R
2
d
\mathrm {T}_{i,j}^k \in \mathbb{R}^{2d}
Ti,jk∈R2d生成(这是上面联系的表示),这是由Transformer中的位置嵌入框架驱动的(可以参考这篇Heterogeneous graph transformer):
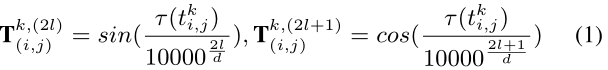
其中时间信息嵌入中的元素索引(偶数和奇数位置索引)分别表示为(2l)和(2l+1),
d
d
d是维数。
之后呢,为了增强时间上下文的encoding的可调能力,我们在关系表示
T
i
,
j
k
\mathrm {T}_{i,j}^k
Ti,jk上添加一个映射层,也就是
T
ˉ
i
,
j
k
=
T
⋅
W
k
\bar{\mathrm{T}}_{i,j}^k = \mathrm{T} \cdot \mathrm{W}_k
Tˉi,jk=T⋅Wk
W
k
∈
R
2
d
×
d
\mathrm{W}_k \in \mathbb{R}^{2d \times d}
Wk∈R2d×d,下面的k表示
k
k
k-type的交互。
Information Propagation Phase(也就是用各个source更新每个实体的过程)
在multi-behavior user-item 交互图
G
u
G_u
Gu上,我们在source nodes(多个)和target node(单个)之间执行time-aware的信息传播,multi-hop跳,共H跳! 用下面的图注意力机制:
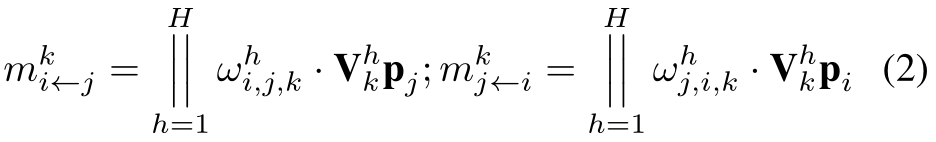
m
i
⟵
j
k
和
m
j
⟵
i
k
m_{i\longleftarrow j}^k和m_{j\longleftarrow i}^k
mi⟵jk和mj⟵ik表明从item
v
j
v_j
vj到user
u
i
u_i
ui和从user
u
i
u_i
ui 到item
v
j
v_j
vj传播消息。
p
j
\mathrm{p}_j
pj表明了item embedding
e
j
\mathrm{e}_j
ej和相应的时间上下文表示
T
ˉ
i
,
j
k
\bar{\mathrm{T}}_{i,j}^k
Tˉi,jk的元素相加,也就是
p
j
=
e
j
⊕
T
ˉ
i
,
j
k
\mathrm{p}_j = \mathrm{e}_j \oplus \bar{\mathrm{T}}_{i,j}^k
pj=ej⊕Tˉi,jk。 相同的操作被应用在从user side上得到信息:
p
i
=
e
i
⊕
T
ˉ
i
,
j
k
\mathrm{p}_i = \mathrm{e}_i \oplus \bar{\mathrm{T}}_{i,j}^k
pi=ei⊕Tˉi,jk。
V
k
h
∈
R
h
H
×
d
\mathrm{V}_k^h\in\mathbb{R}^{\frac{h}{H} \times d}
Vkh∈RHh×d是关于第
k
k
k种行为类型的
h
h
h-head投影矩阵。
w
i
,
j
,
k
h
w_{i,j,k}^h
wi,j,kh,
w
i
,
i
,
k
h
w_{i,i,k}^h
wi,i,kh分别表示了在构造信息
p
j
\mathrm{p}_j
pj和
p
i
\mathrm{p}_i
pi上的学习到的注意力传播权重。
-
w
i
,
j
,
k
h
w_{i,j,k}^h
wi,j,kh,
w
i
,
i
,
k
h
w_{i,i,k}^h
wi,i,kh:
也就是k中类型下的,i对j的第h跳的权重:
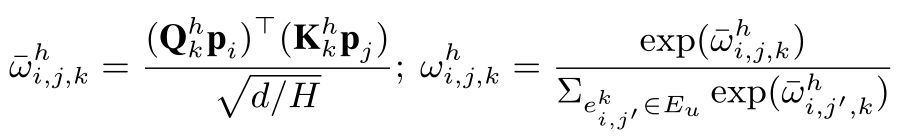
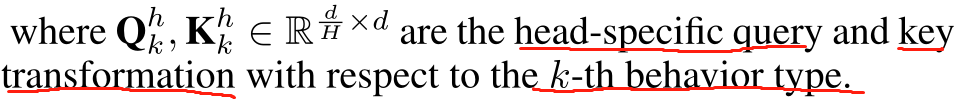
其中维度要根据H跳的不同而变化! 防止内存需求过大! 其中
Q
k
h
,
K
k
h
,
V
k
h
\mathrm {Q}_k^h, \mathrm {K}_k^h,\mathrm {V}_k^h
Qkh,Kkh,Vkh一般是由h跳中所有的实体组成的!这样我们通过Qp和Kp的点击来计算从i到j的相似度,从而确定权重的大小
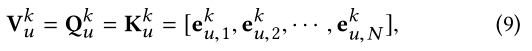
其中N是邻居实体的数量,而且是一个超参数。 如果
∣
L
u
k
∣
≥
N
\left | L_u^k \right | \ge N
∣∣Luk∣∣≥N,那么就该随机从中选N个;相反,则需要全部设置为Null(也就是zero vectors)。
在本文中,N就是M
-
Q
k
h
,
K
k
h
,
V
k
h
\mathrm {Q}_k^h, \mathrm {K}_k^h,\mathrm {V}_k^h
Qkh,Kkh,Vkh:
方式上同样是添加映射函数! 这里的M是H跳中实体的限制数量。
要在消息传递过程中跨不同行为类型合并全局上下文,我们就要在多通道参数学习框架中学习基于注意力的变换矩阵 Q k h , K k h , V k h \mathrm {Q}_k^h, \mathrm {K}_k^h,\mathrm {V}_k^h Qkh,Kkh,Vkh,具体来说,我们设计了一个由M个参数通道组成的基本转换范式。 也就是 Q ˉ k h , K ˉ k h , V ˉ k h ( m = 1 , . . . M ) \bar{\mathrm {Q}}_k^h, \bar{\mathrm {K}}_k^h,\bar{\mathrm {V}}_k^h(m=1,...M) Qˉkh,Kˉkh,Vˉkh(m=1,...M)。他们对应于 M M M个潜在的映射子空间(添加权重),这也反应了跨不同类型的通用行为上下文的不同方面。 形式上,type-specific的转换过程是通过gating mechanism执行的:
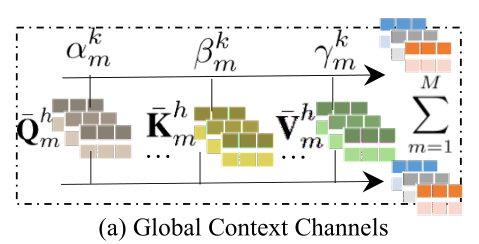
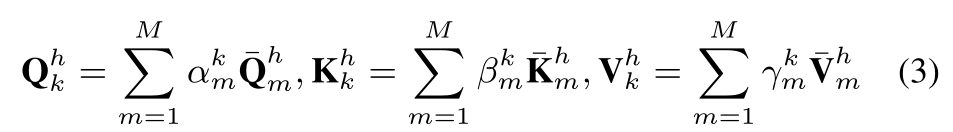

Information Aggregation Phase(散出去了后再聚过来)
基于构造的传播消息
m
i
⟵
j
k
和
m
j
⟵
i
k
m_{i\longleftarrow j}^k和m_{j\longleftarrow i}^k
mi⟵jk和mj⟵ik,我们通过求和操作对相邻信息进行聚合:
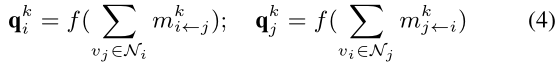

4.1.2 Information Aggregation for Item-side Relations

item-item图中也是上面相似的做法!所以 我们通过注意聚合来融合来自item-item相互依赖的异质信号:
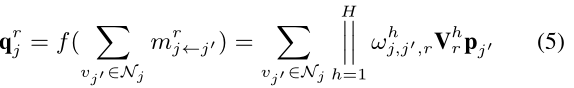

4.2 Behavior Hierarchical Dependency Modeling(可以理解上面的只是单纯的用GCN初始化,这里才是添加行为类型)
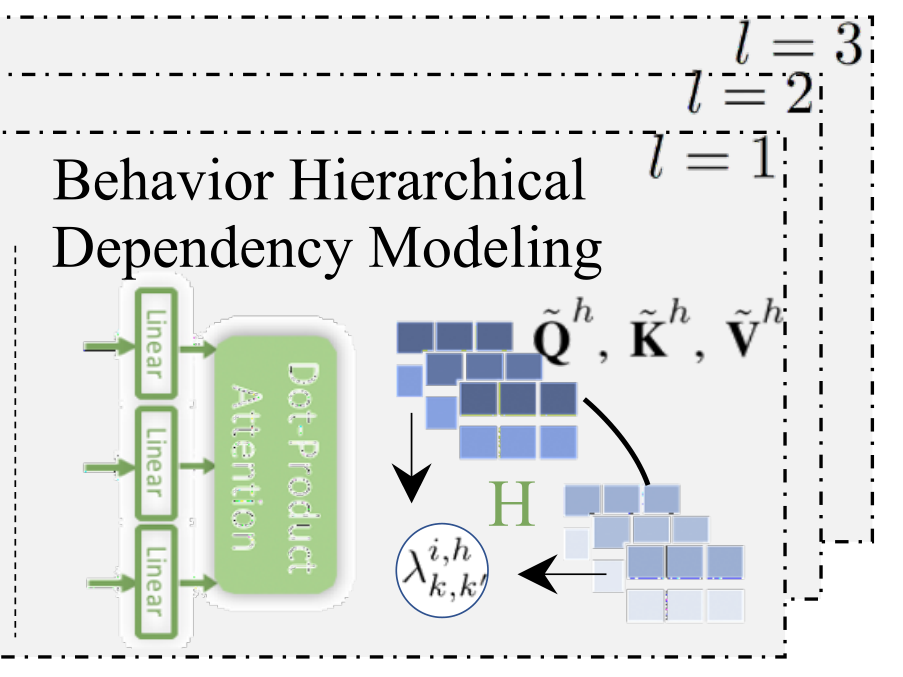
在我们的多行为推荐场景中,不同类型的用户行为以一种复杂和分层的方式相互交互。为了应对这一挑战,出现了两个问题:(一)我们如何有效地保持不同类型行为之间的相互关系;(二)如何促进不同类型特定行为表现之间的协作来增强最终的表示。
4.2.1 Type-wise Behavior Mutual Relation Encoder
我们的相互的关系encoder是基于按比例缩小的dot-product注意力更新的,通过学习成对的type-wise的相关性分数
λ
k
,
k
′
i
,
h
\lambda _{k,k'}^{i,h}
λk,k′i,h,这个可以被表示为:
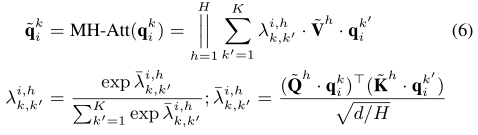

4.2.2 Cross-Type Behavioral Pattern Fusion
接下来,我们建议通过研究个体在预测用户交互的目标类型中的重要性,从而融合学习到的type-specific behavior representations,我们使用gated fusion mechanism来进行结论性的表示
Φ
j
\Phi_j
Φj:
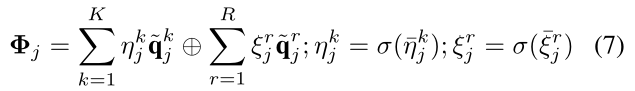
上面的
η
j
k
和
ξ
j
r
\eta _j^k和\xi _j^r
ηjk和ξjr是
k
k
k-th类型的user-item交互表示
q
~
i
k
\tilde{q}_i^k
q~ik和r类型的item-item 关系表示
q
~
j
r
\tilde{q}_j^r
q~jr的重要性分数。 它们可以通过下面来得到:
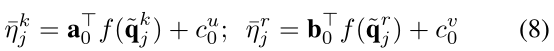

4.3 High-order Multi-Behavior Pattern Propagation.
基于已定义的信息传播和聚合函数,我们在图神经网络中捕获了多行为上下文(用户-物品交互图
G
u
G_u
Gu)下的高阶协作关系。从第(l)层到第(l+ 1)层的更新过程为(
Φ
j
(
l
)
∈
R
d
\mathbf{\Phi} _j^{(l)} \in \mathbb{R}^d
Φj(l)∈Rd):
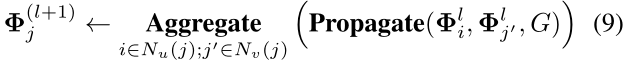
Propagate(·)是信息传播函数,它从user-item交互(在 E u E_u Eu)和item-item依赖(在 E v E_v Ev)中提取有用的特性。Aggregate(·)表示信息融合函数。最后的嵌入经过不同顺序的表示总结为: Φ j = Φ j ( 1 ) ⊕ . . . ⊕ Φ j ( L ) \Phi _j = \Phi _j^{(1)} \oplus ... \oplus \Phi _j^{(L )} Φj=Φj(1)⊕...⊕Φj(L)
4.4 The Learning Phase of KHGT
在为user和item生成结论性表示
Φ
i
\Phi _i
Φi和
Φ
j
\Phi _j
Φj之后,用户i和item j的在目标行为下交互概率可以被推断为
P
r
i
,
j
=
z
⊤
×
(
Φ
i
⊙
Φ
j
)
P_{r_{i,j}} = \mathrm{z}^{\top } \times \left(\mathbf{\Phi}_{i} \odot \mathbf{\Phi}_{j}\right)
Pri,j=z⊤×(Φi⊙Φj)。 为了进行模型优化,我们的目标是最小化以下边际成对损失函数:
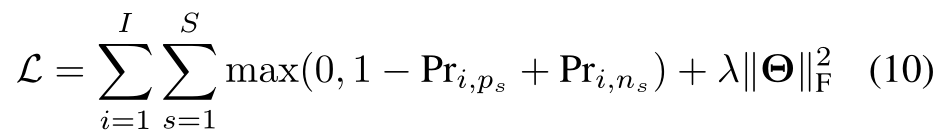

实际上,我们会为每个用户随机S积极的items v p 1 , v p 2 , … , v p s v_{p_{1}}, v_{p_{2}}, \ldots, v_{p_{s}} vp1,vp2,…,vps和S个消极的items v n 1 , v n 2 , … , v n s v_{n_{1}}, v_{n_{2}}, \ldots, v_{n_{s}} vn1,vn2,…,vns,除此之外, Θ \Theta Θ表示了可训练的参数的集合, λ \lambda λ是为正则项的权重。
4.5 Sub-graph Sampling for Large-Scale Data
图神经结构的一个关键挑战是在full-batch模式下对整个图进行信息聚合,这将消耗巨大的内存和计算成本。为了使KHGT具有处理大规模数据的能力,我们在graph G u G_u Gu和 G v G_v Gv上开发了一种基于随机游走的子图采样算法,并在采样过程中根据 G G G的邻接矩阵中提取的节点相关性来维护一个权值向量。
4.6 Model Complexity Analysis.
我们的 K H G T KHGT KHGT花费了 O ( K × ( I + J ) × d 2 ) O(K× (I+J)×d^2) O(K×(I+J)×d2)来计算 Q , K , L \mathbf{Q,K,L} Q,K,L变换,和 O ( ∣ E ∣ × d ) O(|E| ×d) O(∣E∣×d)用于信息聚合。对于type-wise modeling,最重要的计算来自 O ( K × ( I + J ) × d 2 ) O(K×(I+J)×d^2) O(K×(I+J)×d2)转换。总的来说,我们的KHGT可以达到与GNN-based的多行为推荐方法相当的时间复杂度。此外,与最有效的GCN模型相比,KHGT的中间结果需要适度的额外内存。
5. Evaluation
本节回答了以下研究问题:
- RQ1:与各种最先进的推荐系统相比,KHGT的表现?
- RQ2:不同设计的模块和捕获的关系结构对模型性能的贡献是什么?
- RQ3:在我们的异构聚合器中,KHGT如何与不同类型的行为集成工作?
- RQ4:与具有代表性的竞争对手相比,KHGT在不同的交互稀疏水平上的表现性?
- RQ5: KHGT如何执行不同的参数设置(例如,潜在维度和GNN深度)?
- RQ6:我们的KHGT的解释能力在捕获跨类型行为的相互依赖关系?
Experimental Settings
数据集:

评测指标: Normalized Discounted Cumulative Gain (NDCG@k)and Hit Ratio(HR@k)
Methods for Comparison.
传统的矩阵分解方法:
- BiasMF
Autoencoder-based协同过滤:
AutoRec
CDAE
神经网络增强协同过滤:
DMF
NCF
神经自回归推荐方法:
NADE
CF-UIcA
图神经网络协同过滤:
ST-GCN
NGCF
多行为模式推荐。
NMTR
DIPN
N
G
C
F
M
NGCF_M
NGCFM
MATN
MBGCN
Knowledge-aware推荐方法。
KGAT
Parameter Settings

Performance Validation (RQ1)

这种表现差异可以归因于对多类型行为相互依赖关系的联合探索和潜在的知识感知项目协作信号。
这说明聚合多重行为模式在设计的交互编码功能中具有积极的作用。此外,基于gnn的神经网络方法优于自编码器和自回归CF模型,表明在用户-物品关系中探索高阶协同信号的合理性。
Model Ablation Study (RQ2)

我们从五个角度考虑KHGT的不同模型变体,并分析其影响(如图3所示):
Type-specific Behavioral Pattern Modeling.KHGT-GA.
Behavior Mutual Dependency Modeling.KHGT-MR
Cross-Type Behavioral Pattern Fusion.
Temporal Context Encoding.KHGT-Ti.
Incorporation of Item-Item Relations.KHGT-KG.
我们可以观察到,我们开发的完整版本的khgt在所有情况下都取得了最好的性能。我们进一步总结了以下结论:(1)以显式关注的方式建模特定类型的user-item交互模式比执行图结构卷积更好。(2)基于相互关系学习的多行为推荐增强效果。(3)显性判别对于类型特异性行为模式贡献的必要性。(4)时间情境信息对行为动态捕捉的积极作用。(5)在我们的图神经网络中加入项目外部知识有助于更准确地编码用户的多维偏好。
Performance v.s. Multi-Behavior Integration (RQ3)

Influences of Interaction Sparsity Degrees (RQ4)

Hyperparameter Effect Investigation (RQ5)

Case Studies ofKHGT’s Explainability (RQ6)

















 639
639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









