






Resource Aware Person Re-identification across Multiple Resolutions
作者:Yan Wang, Lequn Wang等人 2018CVPR
1. Motivation
不同图像的识别难度不同,如:

左图简单右图难,左图用一些简单的颜色特征就能识别但右图需要更高级的特征如携带信息,都按简单的来识别不了难的模型,都按难的来计算太浪费了。因此不应一样对待。于是作者提出下图的模型:

作者做了两件事:
- 融合多层的特征
- 每层都用损失监督
这些在目标检测,分割等领域都被广泛使用,作者移到reid了而已。
2. 方法
特征融合规则为:
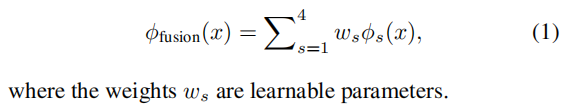
但后面好像是直接给出这些权重的固定值的。
损失计算为:
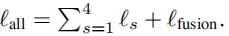
右边的五个损失都是基于三元组损失,如下形式:

其中,D(,)是两者之间的L2距离。
x
p
k
x_p^k
xpk是 k图中p人的特征。
3. 实验
3.1. 实验细节
60000次迭代,输入为256*128,backbone是ResNet50或DenseNet121,分别记为R和D(De),Adam,bs=72,每次18人,每人4张图。学习率如下设置:
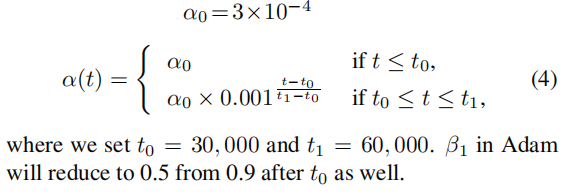
随机裁减 + 随机水平翻转作数据扩增,这些图像提取的特征和原图提取的特征取avg作为原图最后的特征
除此,还有随机擦除作数据扩增(RE),ReRank(RR)
3.2. 性能

加了RR和RE性能都没上90,模型性能不高,只接近2017年的水平
3.3. 消融


权重貌似没学,而是直接赋值的
各层的监督损失的影响:

4. 计算量


同等精度下,需要的计算量相对少点
总体感觉这篇文章创新点不算高,虽然引入了多层的特征和多层的监督,但没有加入其它东西,性能提升也不大,节省的计算量也不算大。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









