






目录
- 1. Exploiting Transitivity for Learning Person Re-identification Models on a Budget
- 2.Easy Identification from Better Constraints: Multi-Shot Person Re-Identification from Reference Constraints
- 3. Query-guided End-to-End Person Search
- 4. Dissecting Person Re-identification from the Viewpoint of Viewpoint
- 5.CityFlow: A City-Scale Benchmark for Multi-TargetMulti-Camera Vehicle Tracking and Re-Identification
- 6. Person Re-identification with Cascaded Pairwise Convolutions
- 7. Text Guided Person Image Synthesis
- 8. Unsupervised Person Image Generation with Semantic Parsing Transformation
- 9. Eliminating Background-bias for Robust Person Re-identification
- 10. VRSTC: Occlusion-Free Video Person Re-Identification
- 11. Attribute-Driven Feature Disentangling and Temporal Aggregation for Video Person Re-Identification
- 12.Re-Identification Supervised Texture Generation
- 13.Unsupervised Cross-dataset Person Re-identification by Transfer Learning of Spatial-Temporal Patterns
- 14. Perceive Where to Focus: Learning Visibility-aware Part-level Features for Partial Person Re-identification
- 15. Generalizable Person Re-identification by Domain-Invariant Mapping Network
1. Exploiting Transitivity for Learning Person Re-identification Models on a Budget
Sourya Roy, Sujoy Paul等人 2018 CVPR
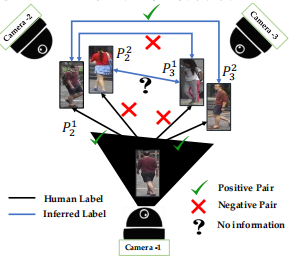
本文思路奇特,其考虑的是reid的标注很难,因此最小化标注量其实是很重要的。论文的思路可以用下图解释:
其
P
k
i
P_k^i
Pki是第 k 个相机下的第 i 张图像。作者指出,如果
P
1
1
P_1^1
P11和
P
2
1
P_2^1
P21图像对被标注为相同ID,同时
P
1
1
P_1^1
P11和
P
3
2
P_3^2
P32图像对也被标注为相同ID,则很明显就不用标注
P
2
1
P_2^1
P21和
P
3
2
P_3^2
P32图像对的标签了,它们肯定是相同ID;而如果
P
1
1
P_1^1
P11和
P
2
1
P_2^1
P21图像对被标注为相同ID,而
P
1
1
P_1^1
P11和
P
3
1
P_3^1
P31图像对被标注为不同ID,则不用标注
P
2
1
P_2^1
P21和
P
3
1
P_3^1
P31图像对也不需要标注了,肯定是不同ID。作者指出在构造三角形约束进行标签推测时,至少要有一个positive边,且至少要选择2条边,同时选至少有1个positive边的概率最大的三角形。用到了两个方法,一个是1/2 max-cut,另一个是时间复杂度近似为四次方的贪婪算法。文中有大量公式推导,没看懂,但结论很简单:大概只需要标注8%~15%的数据,就可以得到整个数据集的标注结果。
2.Easy Identification from Better Constraints: Multi-Shot Person Re-Identification from Reference Constraints
Jiahuan Zhou, Bing Su, Ying Wu等人 2018 CVPR
针对multi-shot person reid问题(MsP-ReID),考虑到运动信息对于MsP-ReID的鉴别性不够强,因此本文重点讨论通过学习视觉外观来获取鉴别性更强的行人表示。现有的基于度量学习的方法通常利用pair-wise或triplet-wise相似性约束,但这些要求在度量学习中进行密集的优化,或者导致性能下降。得到次优解。此外,由于正对和负对数据量严重不平衡。本文提出一种新的相似性约束,它将样本点分配给一组参考点,以产生线性数量的参考约束。此外,文中还提出了一些基于传输的方法来优化参考约束。在这些约束条件的基础上,利用典型的回归度量学习模型,可以很容易的得到的闭式解。

3. Query-guided End-to-End Person Search
Bharti Munjal,Sikandar Amin等人 2019 CVPR
Motivation:
- 行人检测和ReID要在一个框架中联合优化—行人搜索认为
- 行人搜索应该充分利用查询图像(例如强调独特的查询模式)
方法:
但目前少有paper做到了第一点,而所有方法都是简单使用查询图像做probe。本文提出了一个query-guided的end-to-end的行人搜索框架(QEEPS)来解决上面两个问题,方法基于OIM(行人搜素经典baseline),并扩展了:
- query-guided Siamese squeeze-and-excitation network (QSSE-Net) ,使用了来自query和gallery图像的全局上下文信息
- query-guided region proposal network (QRPN) ,用于产生 query-relevant的proposals
- query-guided similarity subnetwork (QSimNet),用于学习query-guided ReID score
本文和传统方法对比:

网络框架为:

其中,各模块分别为:



优化目标为:
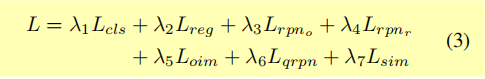
在CUHK-SYSU和PRW上比OIM高约10个点mAP。
4. Dissecting Person Re-identification from the Viewpoint of Viewpoint
Xiaoxiao Sun Liang Zheng 等人 2019 CVPR
视点对ReID性能提升很重要,于是作者提出一个大规模合成数据集PersonX;分析了视点(面对相机的旋转角度,0~360
o
^o
o)对ReID的具体影响。一个例子为:

PersonX数据集介绍:
包含1266个手动设计的ID,其中包含547女性和719男性,不同肤色,年龄,身体形态,发色,穿着包括外观jeans, pants, shorts,slacks, skirts, T-shirts, dress shirts, maxiskirt等,一些ID有背包,肩包,墨镜或帽子,衣服颜色和纹理与真实世界一致。行人状态包括走,跑,闲逛,对话等。如图2所示:


数据集包括不同光照,相机配置,背景和视点。并且数据集很真实,结果显示性能和真实数据集性能具有一致性。
作者用IDE+【Camstyle】、triplet feature【In defense of the triplet loss for person re-identification】和PCB三个模型分别在PersonX和真实数据集上进行实验,验证PersonX数据集(人造数据)的可用性,结果显示和真实数据集的性能表现具有一致性,如下所示:

在PersonX上性能更好不是因为这个数据集容易,而是实验设置排除了环境因素的影响。
数据集对比:

实验还验证三个问题:
- 训练集中视点信息如何影响性能?
** 缺少视点信息会损害训练
** 缺少连续的观点信息比缺少随机的观点信息更有害
** 左右视点信息比前后视点信息更能提点 - 查询视点信息如何影响检索效果?
** 考虑左右视点会比考虑前后视点带来更高检索精度 - Gallery视点信息如何影响检索效果?
** Gallery中那些视点与与查询视点不同的TP图像比那些与查询具有类似视点的TP图像更难检索。
** 当环境具有挑战性时,例如背景复杂、光照极端和分辨率低时,上述问题就变得更加严重。
5.CityFlow: A City-Scale Benchmark for Multi-TargetMulti-Camera Vehicle Tracking and Re-Identification
Zheng Tang, Milind Naphade等人 2019 CVPR
其实是一篇车辆ReID的文章,其提供了一个新的车辆ReID数据集CityFlow,这是一个城市规模的10个交叉路口的交通摄像机数据集,它包含了来自40个摄像机的3小时以上的同步高清视频。两个同步摄像机之间的最长距离为2.5公里。CityFlow在空间覆盖范围和城市环境中摄像机/视频的数量上都是最大的。该数据集包含200多个带注释的bounding box,涵盖范围广泛的场景、视角、车辆模型和城市交通流状况。提供相机几何形状和校准信息以帮助时空分析。另外,该数据集的一个子集可用于基于图像的车辆再识别任务。



数据集对比:

当前SOTA车辆ReID方法在该数据集上的表现:

6. Person Re-identification with Cascaded Pairwise Convolutions
Yicheng Wang, Zhenzhong Chen, Feng Wu, Gang Wang 2018 CVPR
一位武大校友的文章,文章大量公式,没看懂。但其思想很简单,其设计了BraidNet结构来缓解相机色差和不对齐的影响,其是基于一系列WConv结构级联而成的;此外,作者指出反向传播过程中的零梯度现象是由负权重造成的,于是提出Channel Scale以缓解这种问题,还提出了Sample Rate Learning策略缓解正负样本不平衡问题。其中WConv结构如下:

BraidNet结构为:


性能不算太高
7. Text Guided Person Image Synthesis
Xingran Zhou,Siyu Huang,Bin Li等人 CVPR 2019
包含两个阶段:text指导的pose生成;视觉外貌的迁移图像生成。第一阶段基于text来精细推断出目标pose而第二阶段通过推断的pose和text来生成视觉外貌图像。该方法建立了language空间到图像空间的映射关系。生成结果如下图所示:




图像生成过程如下:

本文基于CGAN,因此要求paired输入。
第一阶段为:

这个阶段是先提取训练图像的pose,然后分为K组(头分别朝向不同方向),即basic pose,根据text首先找到一个合适的basic pose,然后用text和pose生成器生成更精细的pose图像,该过程包含以下几个损失:
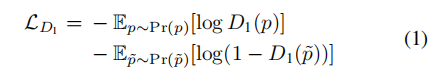
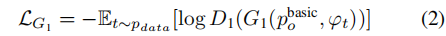
加入MSE损失保证生成的pose图像结构:
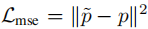
加入生成图像的方向和真实方向之间的分类交叉熵损失
L
c
l
s
L_{cls}
Lcls,得到:
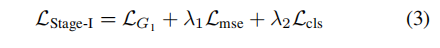
第二阶段为:

就是根据text生成指定颜色外貌等的图像,而cGAN的c可以是text,图像等任意多模态的条件,这一过程没什么问题。损失为:
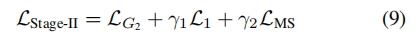

其中
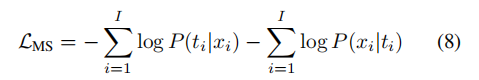
是多模态相似性损失,
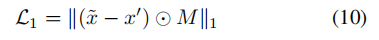
用于正则网络并保证生成图像质量,
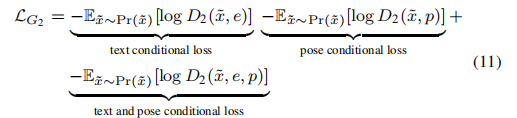
最后作者还提出了VQA(Q&A问答)系统判断生成图像质量,如下:

结果表示生成图像质量很高。
8. Unsupervised Person Image Generation with Semantic Parsing Transformation
Sijie Song, Wei Zhang, Jiaying Liu, Tao Mei 2019 CVPR
解决了无监督的pose指导的行人图像生成,其挑战主要来自人体的非刚性形变。作者将这个任务分解为语义解析和外貌生成两个子任务。
生成图像对比:

质量很高。整体过程为:


算法流程为:

9. Eliminating Background-bias for Robust Person Re-identification
Maoqing Tian, Shuai Y等人 2018 CVPR
作者观察到背景偏差对reid性能影响很大,于是基于行人解析设计了行人区域指导的池化策略来更好的学习行人局部特征并通过添加随机背景来作为数据扩增手段。
示例:

有相似背景的图像之间的相似度往往很大,可能盖过相同ID的不同背景图像,从而造成检索错误,如上图rank6和rank26所示。
 提出的方法的框架为:
提出的方法的框架为:

其中行人解析网络事先在LIP数据集上训练好,最终得到的效果其实一般,不算太好,还是得益于主分支的全局特征的保留。
10. VRSTC: Occlusion-Free Video Person Re-Identification
Ruibing Hou, Bingpeng Ma等人 2019 CVPR
解决视频reid中的部分遮挡问题。而为了显式地处理部分遮挡问题,作者提出Spatio-Temporal Completion network (STCnet)。与以往大多数方法中直接丢弃遮挡部分不同,STCnet可以恢复被遮挡部分的外观。一方面,利用有遮挡的帧中的遮挡部分,可以从其他相邻的未遮挡的帧中预测出来。另一方面,行人序列的时间模式为遮挡部分的生成提供了重要线索。利用时空信息,STCnet 可以恢复遮挡部分的外观,从而利用这些得到的未遮挡图像进行更准确的视频行人再识别 。整体框架为:



其中红圈部分的相似性得分计算为:
其他工作通常使用注意机制来定位被遮挡的帧,这些方法通常构建一个子网络来预测视频中每帧的权重。然而,由于没有对权值的直接监督,子网络很难为被遮挡的帧自动分配低权重。本文提出了一种相似度评分机制,用于生成帧中各区域的注意评分。而遮挡通常发生在几个连续的帧中,遮挡与原始的身体部分具有不同的语义特征,本文使用帧中各区域特征和视频中所有帧中区域特征之间的余弦相似度作为得分。设输入视频为
I
=
{
I
t
}
t
=
1
T
I=\{I_t\}_{t=1}^T
I={It}t=1T,其中T表示视频帧长度。每一帧图像都被等量且分为三块,即
I
t
=
{
I
t
u
,
I
t
m
,
I
t
l
}
I_t=\{I_t^u,I_t^m,I_t^l\}
It={Itu,Itm,Itl},该帧的特征表示为:
{
v
t
k
∣
k
∈
{
u
,
m
,
l
}
}
\{v_t^k|k \in \{u,m,l\}\}
{vtk∣k∈{u,m,l}},通过对视频中所有帧取avg pool得到视频序列的平均特征为:
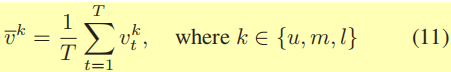
然后第 k 帧和视频序列的cos相似性得分计算为:
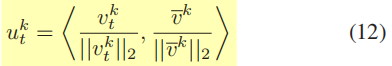
设置一个阈值(图3中为0.89),相似性得分小于阈值的就是遮挡区域,图3中即为:

11. Attribute-Driven Feature Disentangling and Temporal Aggregation for Video Person Re-Identification
Yiru Zhao, Xu Shen等人 2019 CVPR
基于视频的reid很重要,当前大多数reid方法是对视频中不同帧的特征使用avg池化(即时间平均池化)而没有考虑到给不同帧赋不同权重(不同帧的遮挡,视点和pose不同,而对于遮挡帧赋小一点权重就是10中说的除10外其他方法对于遮挡的做法)。而本文提出了一个由属性驱动的特征解耦和帧间重新加权的新方法。子特征由属性识别置信图重新加权,然后不同帧根据加权值重新聚合成最终的行人表示。通过这种方法,每帧中最具信息的区域被增强并形成一个鉴别性的表示。简单过程图解为:


整体学习框架为:


而权重图是从属性预测置信图得到的,那属性预测概率图怎么得到的?
本工作用到了属性标签,并将属性标签分为了N组(文中N=6),每一帧分别像APR那样进行属性预测,得到属性识别的置信图为:
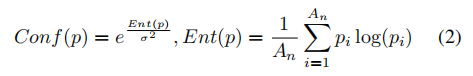
从而每一帧的权重为:
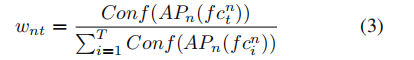
而
A
P
n
AP_n
APn则是第n组的属性预测器(第n个局部特征,
n
∈
[
1
,
N
]
n \in [1,N]
n∈[1,N]),
A
n
A_n
An是第n组属性中的属性数。N组属性分类示例如下(注意不同数据集标注的属性不同,下面这个只是一个例子):

最后局部特征之间通过学到的权重加权为:
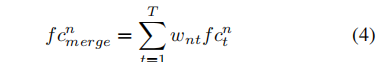
而对于全局特征,每一帧都赋予相同的权重,假设共T帧,则每一帧的权重都是1/T。而且注意,计算权重时进行的前向传播不用于反向传播。最终concat N个局部特征和 1 个全局特征,得到最终行人表示为:
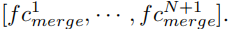
而由于属性标注是很难的一件事,于是作者提出先给一个小的源域上的属性标签,然后进行模型迁移学习,将模型学到的知识迁移到目标域(要进行视频reid的那个域)并进行域适应(可以做域适应,但本文好像没用到,而是直接将源域学习到的模型用于目标域属性预测,这一过程其实和跨域reid是一个意思),过程为:

其中,MMD损失用于消除域间差异,

而每个属性用一个BCE损失监督,所有BCE损失组成:
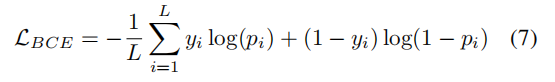
但这种设置是每个属性预测错了的惩罚力度都是一样的,但如RAP数据集的属性分别如下:

属性分布严重不平衡,因为提出加权的BCE损失代替BCE损失如下:
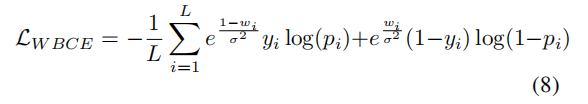
这确保网络必须在很大把握时才能将某个属性的存在性预测为1,否则惩罚力度很大。
最终在目标域进行预测时,一个视频序列中的所有帧(都是同一人的)对于某一属性预测结果进行等权重加权,得到这个视频下此人的属性存在性的概率和为:
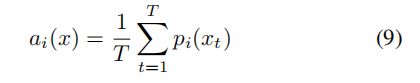
进而做一个阈值判断:
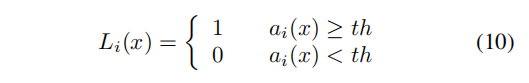
结果大于阈值判定为存在该属性,否则不存在。一个例子如下:

结果为:



某一区域越红表示这一帧的这一区域越重要
12.Re-Identification Supervised Texture Generation
Jian Wang, Yunshan Zhong, Yachun Li, Chi Zhang等人 2019 CVPR
纹理生成问题在reid中讨论的不多,于是作者提出在reid监督下进行end-to-end的生成行人body的纹理,用从输入图像提取的纹理信息对生成对象进行渲染并在reid的指导下最大化输入图像和生成图像的相似性。


模型整体框架为:

其中Face loss是对人脸生成进行监督,对于该损失的消融实验如下:

生成结果展示:



文中的reid模型是基于pose和pcb的。在其他领域的应用:

13.Unsupervised Cross-dataset Person Re-identification by Transfer Learning of Spatial-Temporal Patterns
Jianming Lv, Weihang Chen等人 2018 CVPR
提出一个无监督的增量(循环促进模型性能提升)学习算法,叫TFusing,是通过对行人在目标域中的时空模式进行迁移学习来实现的。该算法首先将从小的标注过的源域数据集上训练的视觉分类器C(reid模型)迁移到未标注的目标域数据集以学习行人的时空样式。然后,用一个贝叶斯融合模型将C从目标域学习到的时空样式和视觉特征结合起来,以显著提升分类器F的性能。最后,在目标域上用F进行rank,再从rank中学习(Learning-to-rank)进一步优化C(相互促进,最终使得F和C都得到提高)。模型如下图所示:

C的学习过程为:

Learning-to-rank的结构为:

其中,triplet网络更新CNN等结构,而由于这些结构和C中的结构共享权重,因此其实是在更新C的参数,即第四部的实现。
此外,还有一个定理如下:
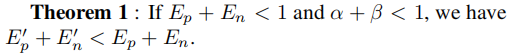
其中结论是需要的,而前面的条件就是paper中需要满足的要求。
14. Perceive Where to Focus: Learning Visibility-aware Part-level Features for Partial Person Re-identification
Yifan Sun, Qin Xu, Yali Li, Chi Zhang等人 2019 CVPR
主要用于处理partial re-ID问题,如果直接将partial行人图像和完整的行人图像比较,就会导致很严重的空间不对齐,从而导致reid性能下降。作者提出Visibility-aware Part Model (VPM),其通过自监督学习可见(行人partial是缺了一部分,缺了的就是不可见的,不缺的就是可见的)的感知区域。可见部分让VPM提取region-level的特征,比较两张图像中共享(两张图像中都存在的)区域,从而避免了之前提到的问题。VPM有两个好处:与学习全局特征相比,VPM从细粒度信息受益并学习区域级(局部)特征;VPM能够估计两幅图像之间的共享区域(两张图像均可见的部分),从而抑制空间不对齐现象。示例如下:

- partial ReID会恶化空间不对齐现象
- partial图像和整张图像之间相比时会导致行人下降
模型框架:


anchor选择完整图像。选择共享的可见部分进行比较。最终模型性能只比PCB略差。

定性结果为:

选择将完整行人图像分割为3*2区域,而部分行人的分割也是合理的。
15. Generalizable Person Re-identification by Domain-Invariant Mapping Network
Jifei Song,Yongxin Yang,Yi-Zhe Song等人 2019 CVPR
提出 Domain-Invariant Mapping Network (DIMN)模型,为让模型具有域不变性,使用meta-learning的pipeline,并每个训练周期从源域训练图像的一个子集中采样,和传统meta-learning不同:在目标域不需要模型更新;不同的训练任务共享一个memory bank,保证模型的扩展能力和鉴别能力;目标域ID数量任意
注:meta-learning主要用于处理few-shot学习问题

包括三个部分:
- 两个权重共享的Encoding Subnet,进行特征提取
- Hyper-Network用gallery图像嵌入作为输入训练分类器模型
- memory bank存储训练域的所有的分类器

总损失为:
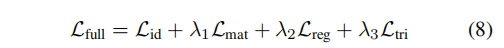



最终mAP比rank@1还高,与一般情况不太一样,很奇怪















 2788
2788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









