







一、弹窗问题
参照 转载:
https://www.jianshu.com/p/4c3330c1cdb5
如图所示,div弹窗
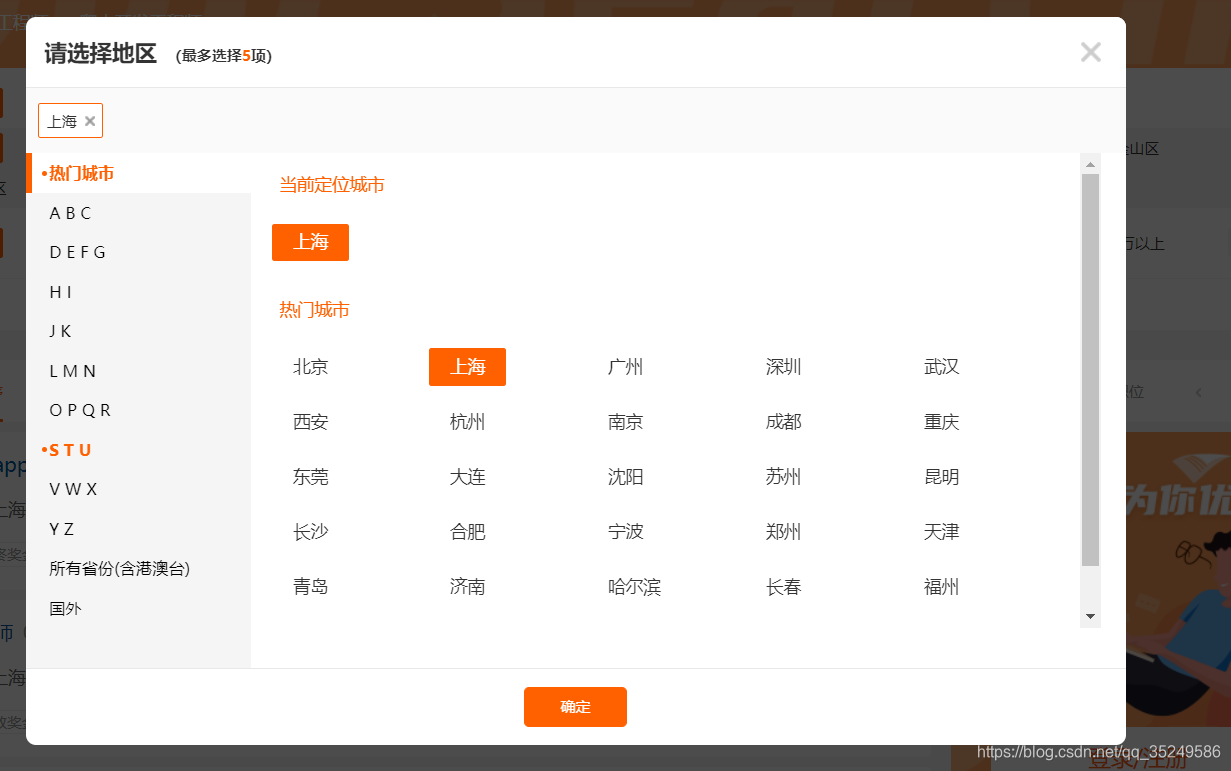
二、弹窗内容
首先要确定弹窗的类型:
(1)div弹窗
(2)新标签页弹窗
(3)alert弹窗
一,div弹窗
div弹窗是浏览器中比较好定位的弹窗,定位的方法与普通的元素一样。不过这里会有一个坑,明明可以找到这个按钮,但是就是定位不到。这个就是因为当前有div弹窗弹出的时候,需要设置一下等待时间,等页面元素加载完毕,再去做其他操作。
这里用百度登陆为例子:
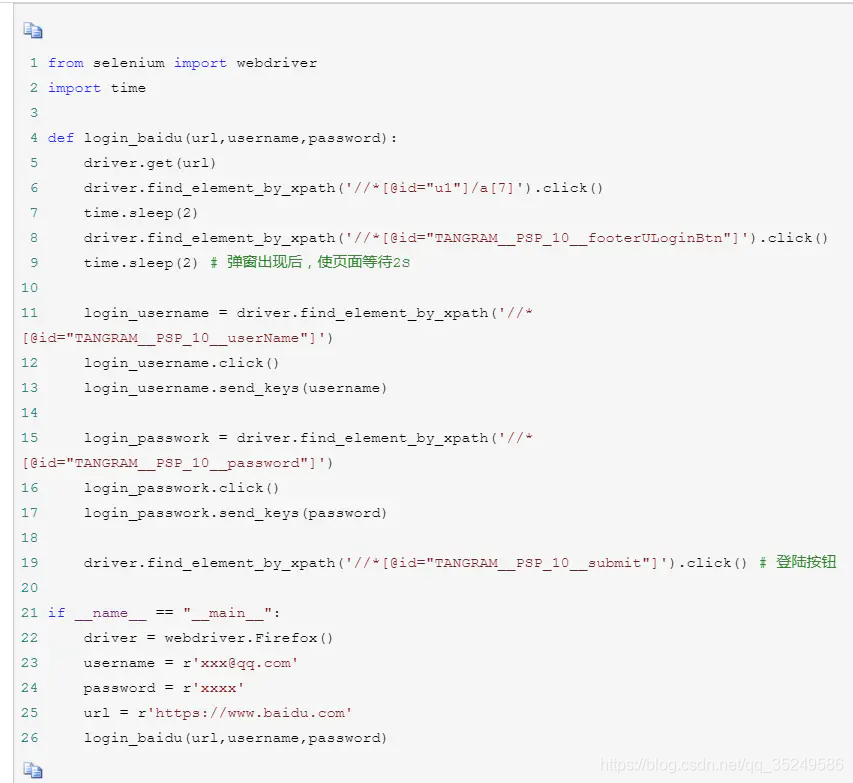
二,新标签页弹窗
新标签页弹窗,则需要进行窗口的切换。此处第一个窗口打开百度首页,在打开一个新窗口打开京东首页,在两个窗口之间进行切换。切换到不同的窗口之后,就可以用常规的方法进行元素的定位。

handles = driver.window_handles # 获取当前打开的所有窗口的句柄
driver.switch_to.window(handles[N]) # 切换到其中一个窗口
其中,获取的句柄下标从0开始,即第一个窗口为[0]、第二个窗口为[1],如此类推。使用switch_to.window方法切换到新标签页后就可以做其他操作了。
三、alert弹窗
在WebDriver中处理JS所生成的alert、confirm以及prompt十分简单,具体做法是使用switch_to.alert()方法定位到alert/confirm/prompt,然后使用text/accept/dismiss/send_keys等方法进行操作。
1.text:返回alert/confirm/prompt中的文字信息。
2.accept():接受现有警告框。
3.dismiss():解散现有警告框。
4.send_keys(keysToSend):发送文本至警告框。 keysToSend:将文本发送至警告框。
如图所示,百度搜索设置弹出的窗口是不能通过前端工具对其进行定位的,这个时候就可以通过switch_to.alert()方法接受这个弹窗。
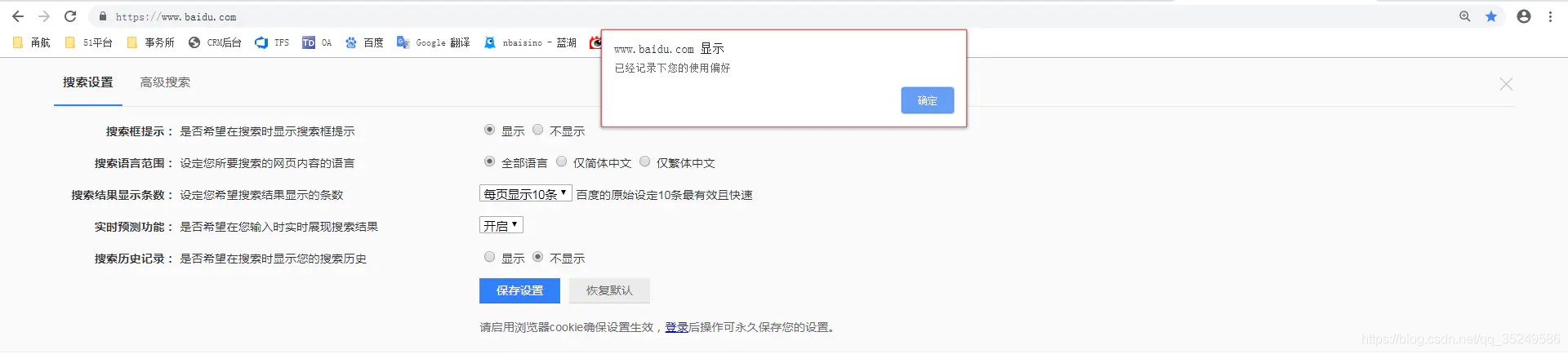
代码如下:

三、爬取51job 职位关键词搜索的完整代码
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import json
import csv
import random
# 声明一个谷歌驱动器,并设置不加载图片,间接加快访问速度
options = webdriver.ChromeOptions()
options.add_experimental_option('prefs', {'profile.managed_default_content_settings.images': 2})
browser = webdriver.Chrome(options=options)
#窗口最大化
browser.maximize_window()
#隐式等待 wait = browser.implicitly_wait(10)
#显示等待
wait =WebDriverWait(browser, 10)
# url
url = 'https://www.51job.com/'
keyword = input('请输入职位:').strip()#比如ipad
# 声明一个list,存储dict
data_list = []
def start_spider():
# 请求url
browser.get(url)
# 获取输入框的id,并输入关键字python爬虫
zhiwei_base = browser.find_elements_by_css_selector('.nlink a')
# print(type(zhiwei_base))
# print(len(zhiwei_base))
zhiwei_base[1].click()
browser.find_element_by_id('keywordInput').send_keys(keyword)
browser.find_element_by_id('search_btn').click()
#定位浏览器弹窗元素------div弹窗
#操作:明明可以找到这个按钮,但是就是定位不到。这个就是因为当前有div弹窗弹出的时候,需要设置一下等待时间,等页面元素加载完毕,再去做其他操作。
time.sleep(5)
browser.find_element_by_class_name('allcity').click()
browser.find_element_by_class_name('ttag').click()
time.sleep(5)
browser.find_element_by_class_name('but_box').find_element_by_class_name('p_but').click()
time.sleep(5)
print('_________________________________________________________________________')
# 显示等待下一页的元素加载完成
wait.until(
EC.presence_of_all_elements_located(
(By.CLASS_NAME, 'next')
)
)
# 将滚动条拉到最下面的位置,因为往下拉才能将这一页的商品信息全部加载出来
browser.execute_script('document.documentElement.scrollTop=10000')
# 随机延迟,等下元素全部刷新
time.sleep(random.randint(1, 3))
browser.execute_script('document.documentElement.scrollTop=0')
# 先获取一个有多少页
page = browser.find_elements_by_css_selector('.p_in span')
all_page = eval(page[0].text[2:4].strip())
print(all_page)
# 设置一个计数器
count = 0
# 无限循环
while True:
try:
count += 1
# 显示等待商品信息加载完成
'''wait.until(
EC.presence_of_all_elements_located(
(By.CLASS_NAME, '.j_joblist')
)
)
'''
# 将滚动条拉到最下面的位置,因为往下拉才能将这一页的商品信息全部加载出来
browser.execute_script('document.documentElement.scrollTop=10000')
# 随机延迟,等下元素全部刷新
time.sleep(random.randint(1, 3))
browser.execute_script('document.documentElement.scrollTop=0')
print('###########################################################33')
lis = browser.find_elements_by_css_selector('.j_joblist')
# print(type(lis))
# print(len(lis))
lis_list = lis[0].find_elements_by_class_name('e')
# print(type(lis_list))
# print(len(lis_list))
for li in lis_list:
post = li.find_element_by_class_name('jname').text
print(post)
post_link = li.find_element_by_class_name('el').get_attribute('href')
print(post_link)
data_issue = li.find_element_by_class_name('time').text
print(data_issue)
salary = li.find_element_by_class_name('sal').text
print(salary)
extra = li.find_element_by_class_name('d').text
print(extra)
try:
tags = li.find_element_by_class_name('tags').get_attribute('title')
print(tags)
except:
tags = None
print(tags)
cname = li.find_element_by_class_name('cname').text
print(cname)
clink = li.find_element_by_class_name('cname').get_attribute('href')
print(clink)
ctpye = li.find_element_by_class_name('dc').text
print(ctpye)
cint = li.find_element_by_class_name('int').text
print(cint)
# 声明一个字典存储数据
data_dict = {}
data_dict['post'] = post
data_dict['post_link'] = post_link
data_dict['data_issue'] = data_issue
data_dict['salary'] = salary
data_dict['extra'] = extra
data_dict['tags'] = tags
data_dict['cname'] = cname
data_dict['clink'] = clink
data_dict['ctpye'] = ctpye
data_dict['cint'] = cint
data_list.append(data_dict)
print(data_dict)
except Exception as e:
continue
# 如果count==all_page就退出循环
if count == 2:
break
# 找到下一页的元素pn-next
#fp_page = browser.find_elements_by_css_selector('.p_in li')
fp_next = browser.find_element_by_class_name('next')
# 点击下一页
fp_next.click()
def main():
start_spider()
# 将数据写入jsonwenj
with open('data_json.json', 'a+', encoding='utf-8') as f:
json.dump(data_list, f, ensure_ascii=False, indent=4)
print('json文件写入完成')
with open('data_csv.csv', 'w', encoding='utf-8', newline='') as f:
# 表头
title = data_list[0].keys()
# 声明writer
writer = csv.DictWriter(f, title)
# 写入表头
writer.writeheader()
# 批量写入数据
writer.writerows(data_list)
print('csv文件写入完成')
if __name__ == '__main__':
main()
# 退出浏览器
browser.quit()















 3153
3153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









