









性能监控
使用命令监控
cpu瓶颈分析
top命令
在进行性能测试时使用top命令,界面如下
上图可以看出
- CPU 概况区: %Cpu(s):
- us(用户进程占用CPU的百分比), 和 sy(系统进程占用CPU的百分比) 的数值很高说明cpu处于忙碌状态,
- 且id(空闲CPU百分比)的值也比较高说明cpu的资源还比较足。
- si(软件中断所消耗的CPU使用的百分比)只占用一点点
load average(负载平均值): 显示了1分钟、5分钟、15分钟的平均负载值。可以看出最近1分钟内发生了大量的负载
物理内存(Mem)和交换空间(Swap):
- total:物理内存的总大小。
- used:已使用的物理内存大小。
- free:剩余的物理内存大小。
- buff/cached:缓存的物理内存的大小占比
CPU使用率排序显示进程列表:
- PID:进程ID,表示每个进程的唯一标识符。
根据上面进行分析可以得出改系统进行性能测试时,可以看出us比sy高很多,且cpu使用率排在前面的应用程序主要为java程序和数据库mysql
**用户态比较高:**
%us (或 %user):
这个参数表示 CPU 在用户态下执行应用程序代码的时间比例。如果这个值较高,说明用户态时间比例较高。
%id (或 %idle):
这个参数表示 CPU 空闲的时间比例。如果用户态时间比例高,通常 %id 的值会比较低,因为 CPU 没有太多空闲时间。
CPU 使用率:
在 top 命令的顶部,会显示总的 CPU 使用率,包括用户态、系统态、空闲等。如果用户态时间比例高,总的 CPU 使用率也会相应较高。
进程列表:
在 top 命令的进程列表中,可以看到每个进程的 CPU 使用情况,包括用户态和系统态时间。如果某个进程的用户态时间比例较高,可能需要进一步分析该进程的行为。
java程序也就是应用程序,它的使用率高,说明它的代码消耗的cpu比较多,需要分析代码问题 详见 > 分析定位代码问题
数据库服务器cpu用户态高:说明是 sql语句的逻辑很复杂。 sql要分析优化。
**系统态比较高**
%sy (或 %system):
这个参数表示 CPU 在内核态下执行系统代码的时间比例。如果这个值较高,说明系统态时间比例较高。
%id (或 %idle):
这个参数表示 CPU 空闲的时间比例。如果系统态时间比例高,通常 %id 的值会比较低,因为 CPU 没有太多空闲时间。
%wa (或 %iowait):
这个参数表示 CPU 等待 I/O 操作完成的时间比例。如果系统态时间比例高,并且 %wa 的值也较高,可能意味着系统正在进行大量的 I/O 操作,导致内核态时间增加。
%st (或 %steal):
这个参数只在虚拟化环境中出现,表示被管理程序(如虚拟机监控器)“偷走”的时间,用于为其他虚拟机提供服务。在非虚拟化环境中,这个值通常为 0。
CPU 使用率:
在 top 命令的顶部,会显示总的 CPU 使用率,包括用户态、系统态、空闲等。如果系统态时间比例高,总的 CPU 使用率也会相应较高。
进程列表:
在 top 命令的进程列表中,可以看到每个进程的 CPU 使用情况,包括用户态和系统态时间。如果某个进程的系统态时间比例较高,可能需要进一步分析该进程的行为。
要分析具体的原因,而不是直接找代码问题。
原因有很多很多情况:比较常见的—— 磁盘获取资源
分析定位代码问题
获取线程栈定位代码 arthas
下载: 百度搜索 arthas软件下载,上传到项目所在的机器
wget https://arthas.aliyun.com/arthas-boot.jar;启动arthas: 首先,要确认机器上有 java进程 java -jar arthas-boot.jar
java -jar arthas-boot.jar
找到 导致项目机器cpu的使用率最高的 java进程的id, 输入这个进程在arthas中对应编号, 回车自动去连接到你选择的java进程
我的这里显示是1
使用arthas:
获取帮助: help
查看线程栈: thread
thread -n 5 显示出cpu使用率最高的5个线程栈信息
展示信息如下:
根据展示的信息和项目信息寻找相关的日志


根据日志我们可以定位到java程序中的67行和73行的代码需要优化。
内存问题定位
OOM
OOM,全称为Out Of Memory,指的是程序在运行过程中因为没有足够的内存资源而导致的错误或问题。在性能测试中,OOM问题通常表明被测试的系统或应用在内存管理方面存在问题,可能是因为内存泄露、内存分配不当或者内存需求超过了系统可用的最大内存。
主要导致OOM问题的因素
内存泄露:应用在运行过程中,未能及时释放不再使用的内存空间,导致这部分内存持续被占用,最终可用内存耗尽。
过度内存分配:应用分配了过多的内存而没有足够的空间来满足这些请求,尤其是在32位系统上,应用程序可用的地址空间有限。
资源竞争:多个进程或线程竞争有限的内存资源,导致某些进程无法获取足够的内存。
缓存使用不当:缓存设置不当(如缓存对象太大或缓存时间太长)也可能导致可用内存迅速耗尽。
不合理的数据结构选择:使用了过于复杂或大小不当的数据结构,导致内存使用效率低下。
**主要体现在哪些性能参数中:**
内存使用量:应用程序的内存使用量持续增加,尤其是在长时间运行时,是检测内存泄露的一个重要指标。
GC(垃圾回收)频率和耗时:在一些使用自动内存管理的语言中(如Java、C#),频繁的垃圾回收操作可能表明存在内存泄露问题,尤其是当GC操作占用的CPU时间显著增加时。
页面交换(Swapping):当系统的物理内存不足以满足需求时,操作系统会使用磁盘空间作为虚拟内存。频繁的页面交换活动(Swapping)可能表明内存资源紧张。
响应时间和吞吐量变化:因内存压力导致的频繁垃圾回收或页面交换,会影响应用的响应时间和吞吐量,这些性能下降也可能是OOM问题
的间接指标。
OOM问题定位
环境搭建:
JvmPertest
要求: jdk1.8、tomcat任意版本、操作系统windows、linux、mac
- 项目部署: 把JvmPertest.war包,拷贝到 tomcat的webapps文件夹,启动tomat就可以
- 启动Tomcat:
- 切换到Tomcat的bin目录 ,使用startup.sh脚本来启动Tomcat: ./startup.sh
- 检查Tomcat是否运行:
- 你可以通过访问默认的Tomcat页面来检查它是否正在运行。在浏览器中输入 http://localhost:8080(或者你服务器的IP地址,如果你不是在本地机器上操作的话),你应该能看到Tomcat的默认页面。8080是Tomcat默认的HTTP端口,如果你更改了默认端口,需要相应地调整URL。
接口: http://机器ip:8080/JvmPertest/pertest1 -----机器ip,这个机器的防火墙
对上面得劲接口进行性能测试,测试了一段时间 ,就看响应信息种出现了:java.lang.OutOfMemoryError:Java heap space。 错误,这个错误,OOM中的 堆溢出
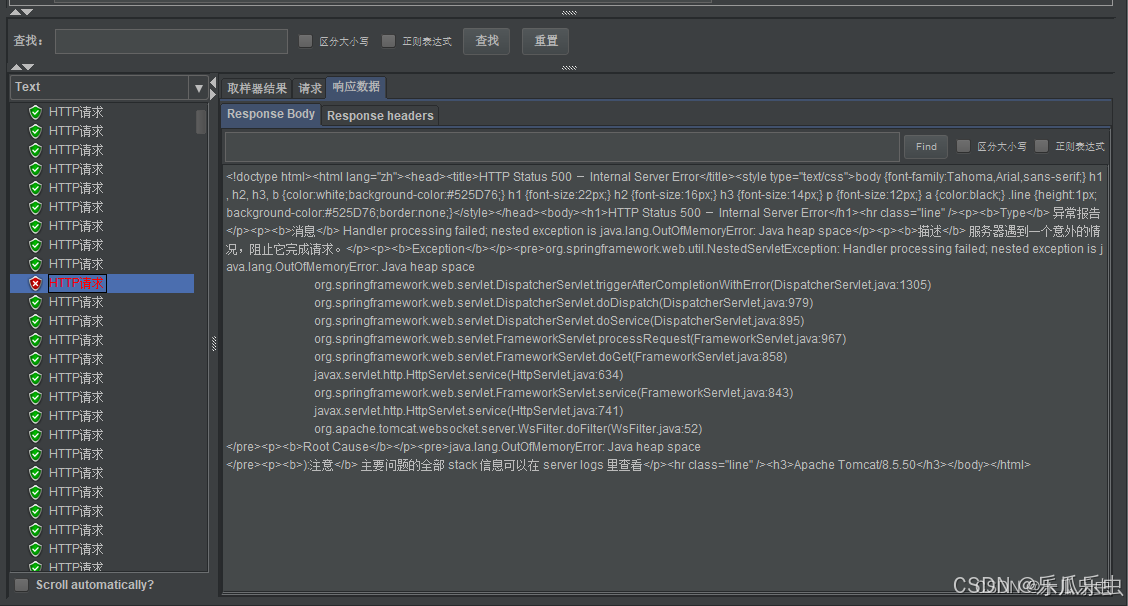
OOM信息获取:
oom问题是一个内存问题,不一定在日志中,能看到OOM的错误。接口返回信息中,也不一定有OOM错误信息。看机器内存条,内存条也是有剩余空间,不会把机器的所有内存都用完。
如果项目日志中,有oom的错误,或者响应体有oom错误信息,或者机器内存都用完了,导致机器异常,这肯定是明显的OOM问题。
如果没有,只能同通过监控手段来获取。
- 如果是容器化部署项目: 如 docker docker stats 容器名称或id 就能看到容器的内存使用情况。 如果看内存使用率 接近100% 肯定是 OOM
- 如果是直接用 tomcat部署的。搭建tomcat的jvm监控平台中看。
OOM问题定位实战
定位OOM问题
arthas
把tomat的bin文件夹下 catalina.sh文件 增加了 JAVA_OPTS="-Xms256m -Xmx256m -Xmn128m" 设置tomcat的堆栈信息。 这样OOM内存溢出会更快,获取的 OOM的大小会更小。

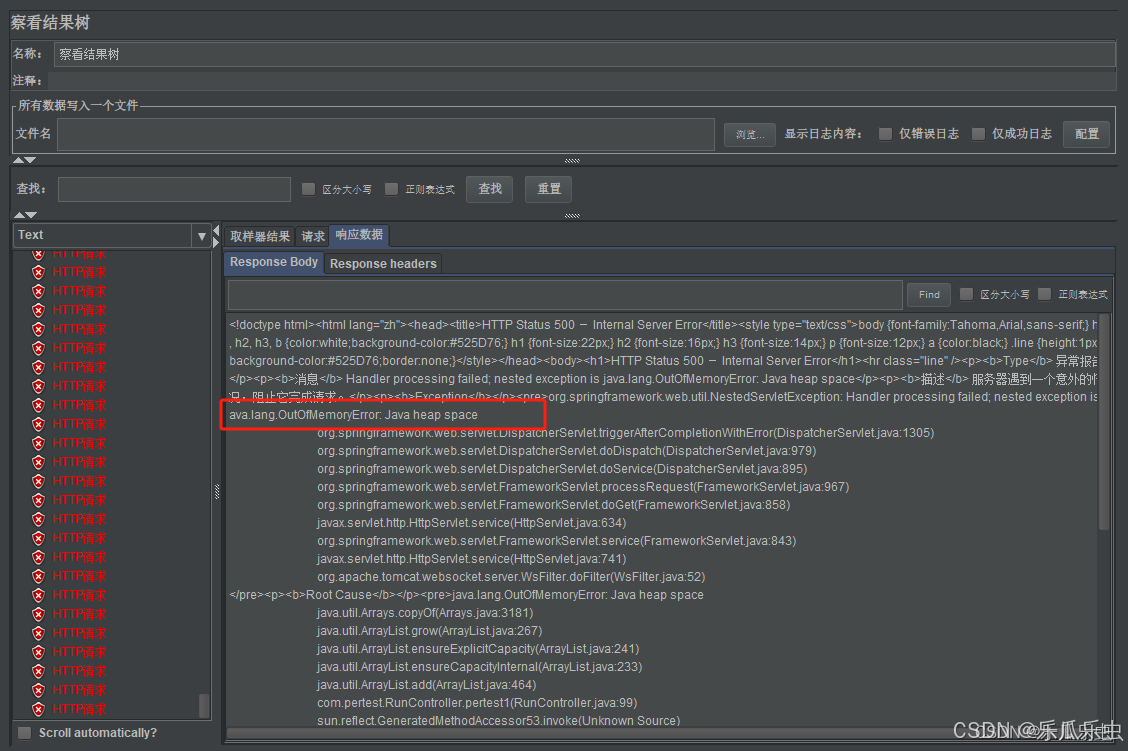
我们的进程是第4个
在arthas中 执行 heapdump 获取到了 堆栈信息。
堆栈信息是一个二进制文件,后缀 .hprof 也可以是 .bin
获取OOM堆信息定位代码
下载hprof的二进制文件,用 MAT工具打开,怎么去看
如果看不懂。 把hprof文件,给开发人员。
网络问题分析
相关环境配置详见这里
做性能测试时, 接口响应信息出错,错误信息为 连接被拒,或端口被占用
connect refuse
connect timeout
Address already in use
出现这样一些错误,与你的服务器,可能没有任何关系。而可能是,你发起方的问题。
http协议,发起一个请求,http包中,包含: 发起方ip、端口,+(传输的数据)+目的地的ip和端口
目的地的ip和端口: 目的地的ip是不会变的。 端口,基本也是不变,但是,这个端口,会有一个连接通道的大小限制。nignx(work数量 * workconnections数量)
发起方的ip,一般也是明确的,基本不变的。发起请求的端口,是在变的。而这个端口的数量是有限 的一台电脑,理论上,可用的端口数量: 65535个每发出一个请求,就要申请占用一个端口,
http1.1版本,是长连接,建立连接之后,会保持一个比较长的时间。在这个时间之后,断开连接,断开连接,占用发起方的端口,就会释放。所以,端口是可以复用的。如果把 保持连接的时间长度,变短, 端口的复用率,升高了。
如何让http请求的保持的时间长度变短? 短连接,只要传输完数据,连接就会断开。
只需要把 http的请求中 keepalive 为false。 ----传输完数据,断开,下次传数据,再建立连接。这样就能提高有限断开的复用率。
方法1: 所以,性能测试中,出现上面的说的错误的时候,我们可以把 http请求中的 keepalive的勾选去掉。
一台机器,端口的理论值是 65535个,但是,不是所有的都能用于 发送请求。
端口总共有65535个,其中
- 0~1023(共1024个),为公认端口,紧密的绑定在一些特定服务上,如21端口就是FTP服务,80端口就是HTTP服务;
- 1024~49151(共48127个),为注册端口,松散的绑定于一些服务,如8080端口常常就用于绑定tomcat服务;
- 49152~65535(共16384个),为动态或私有端口。
所以http协议,发起一个请求,默认使用的发起方机器端口范围在49152-65535之间。
电脑操作系统为普通大众服务的,一般用不了这么多的端口。所以操作系统,并没有开发所有的端口。windows系统,这个开放的量更低,所以,windows电脑,做性能测试发起请求的电脑,是很容易出现上面的错误。
接下来的问题,如何在一台电脑上,开放更多的端口,用于性能测试。
windows: netstat -ano | find "TCP" /i /c
/i 忽略大小写
/c 统计 相当于linux中的 wc -l
1、直接去掉http取样器的 【使用 KeepAlive】 复选勾
2、
打开系统的注册表,找到 [HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters], 看下右侧的配置信息,有没有MaxUserPort配置项
有,则修改值为 65534(十进制),确定
没有,则新增一个DWORD, name为MaxUserPort, value为 65534(十进制),确定
重启系统linux
net.ipv4.ip_local_port_range = 32768 60999
sysctl -w net.ipv4.ip_local_port_range="1024 65535"
sysctl -p
这个修改之后,不要重启linux系统,一旦重启 就失效
3、
打开系统的注册表,找到 [HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters], 看下右侧的配置信息,有没有TcpTimedWaitDelay配置项
有,则修改值为 30(十进制,30秒),确定
没有,则新增一个DWORD, name为TcpTimedWaitDelay, value为 30(十进制),确定
重启系统linux
sysctl -w net.ipv4.tcp_tw_reuse = 1 # 表示开启重用,允许将TIME-WAITsockets重新用于新的TCP连接,默认为0,表示关闭;
sysctl -w net.ipv4.tcp_tw_recycle = 1 # 表示开启TCP连接中TIME-WAITsockets的快速回收,默认为0,表示关闭;
sysctl -w net.ipv4.tcp_fin_timeout = 5 # 修改系统默认的TIMEOUT时间为5秒;调小
sysctl -w net.ipv4.tcp_max_syn_backlog = 8192 # 进入syn包的最大请求队列;调大
sysctl -w net.ipv4.tcp_max_tw_buckets = 5000 # 表示系统同时保持TIME_WAIT套接字的最大数量; 调小
sysctl -p # 配置生效第3种方法: 发起请求,采用分布式
网络带宽瓶颈
如果你要测试的接口,获取xxxx数据列表,而这个接口,默认返回了所有数据。
如果在写性能脚本,抓包接口的时候,发现 接口 返回的数据量非常大的时候,不要直接做性能测试,应该是,直接提出优化建议,减少 返回的数据量。因为,数据量太大,必然会消耗比较多的网络带宽,用户体验,一定差。
jmeter发请求的数据,要进入网络,要通过机器的网卡, 网络传输的数据,进入服务器,服务器也是要由网络数据,转为计算机的数据 ,也要有一个网卡。
网卡也是可能成为瓶颈,但是,线程网卡一般,都是 千兆网卡。
tomcat性能调优
tomcat配置文件:
catalina.bat \ catalina.sh
conf/server.xml
tomcat的对外http协议的端口是 8080
server.xml文件中,配置线程池
**tomcat性能调优** 参考这里
**1、调整JVM参数:**
- 设置合适的堆内存大小(Heap Size),例如通过-Xms和-Xmx参数设置初始堆大小和最大堆大小。
- 修改 bin文件夹中 catalina.sh文件, 调整里面 JAVA_OPTS="-Xms值 -Xmx值 -Xmn值"
- 设置一个值,然后性能测试,再调整,再性能测试,多次调整+测试,找到 性能最优解。
- 优化垃圾回收器(Garbage Collector),例如使用-XX:+UseG1GC启用G1垃圾回收器。
- 调整其他JVM参数,如-XX:MaxPermSize(对于Java 8之前的版本),-XX:MetaspaceSize(Java 8及以后版本)等。
**2、调整Tomcat配置:**
- 增加线程池大小,通过修改server.xml中的Executor和Connector配置。
- minSpareThreads: tomcat初始化默认时默认创建的线程数,也是以后线程增加时一次增加的 最小数量
- maxSpareThreads:这个参数标识,一旦创建的线程数量超过这个值,Tomcat 就会关闭不活 动的线程
- 线程池最大可以保持的连接数量: maxThreads 乘以 acceptCount
- 调整连接器(Connector)的参数,如maxThreads、acceptCount、connectionTimeout等。
- acceptCount 最大可接受的排队数量
- maxThreads 最大并发连接数
- 如果是微服务,maxThreads这个值,一般都很小,常见的 就是 几个或者小几十
- connectionTimeout 连接超时时间,单位毫秒
- 启用压缩(Compression),通过设置compression和compressableMimeType属性。
- 启用NIO或APR连接器,以提高I/O性能。
- 连接池connector
如果性能测试中,要求的并发用户数,达不到。可能原因: 应用支持的连接池不够。
解决办法:
1、修改tomcat的连接池的配置参数 maxThreads值, 适当的扩大。
2、或者扩大应用副本数量。
但是数量增大,必然会用更多的资源。
tomcat性能调优实战
在Tomcat性能调优中,调整JVM参数和Tomcat配置是两个关键步骤。以下是如何设置合适的堆内存大小和调整Tomcat配置的详细操作步骤:
设置合适的堆内存大小
步骤 1: 评估内存需求
- 使用监控工具(如JVisualVM、VisualVM、JMX等)来观察应用程序在运行时的内存使用情况。
- 分析应用程序的内存使用模式,确定高峰期的内存需求。
步骤 2: 设置JVM参数
- 打开Tomcat的启动脚本(`catalina.sh`或`catalina.bat`)。
- 在`JAVA_OPTS`或`CATALINA_OPTS`变量中添加以下参数:
JAVA_OPTS="-Xms512m -Xmx1024m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCApplicationStoppedTime -Xloggc:gc.log "
- `-Xms512m`:设置初始堆内存为512MB。
- `-Xmx1024m`:设置最大堆内存为1024MB。
- `-XX:+UseG1GC`:启用G1垃圾回收器。
- `-XX:MaxGCPauseMillis=200`:设置垃圾回收的最大暂停时间为200毫秒。
步骤 3: 重启Tomcat
- 保存更改并重启Tomcat服务器以应用新的JVM参数。
步骤 4: 监控和调整
- 继续监控应用程序的内存使用情况。
- 根据监控结果调整`-Xms`和`-Xmx`的值,并重新测试。
调整Tomcat配置
步骤 1: 编辑 `server.xml`
- 打开Tomcat的配置文件`server.xml`。
步骤 2: 调整连接器(Connector)配置
- 找到`<Connector>`元素,并根据需要调整以下属性:
- `maxThreads`:设置最大线程数,例如`maxThreads="200"`。
- `acceptCount`:设置当所有可能的请求处理线程都在使用时,传入连接请求的最大队列长度,例如`acceptCount="100"`。
- `connectionTimeout`:设置连接超时时间,例如`connectionTimeout="20000"`(20秒)。
步骤 3: 启用NIO或APR连接器
- 如果使用的是阻塞I/O(BIO)连接器,考虑切换到NIO或APR连接器以提高性能。
- 对于NIO连接器,设置`protocol="org.apache.coyote.http11.Http11NioProtocol"`。
- 对于APR连接器,设置`protocol="org.apache.coyote.http11.Http11AprProtocol"`。
步骤 4: 启用压缩
- 在`<Connector>`元素中添加以下属性以启用压缩:
compression="on"
compressionMinSize="2048"
noCompressionUserAgents="gozilla, traviata"
compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain"步骤 5: 调整线程池(Executor)配置
- 如果需要,配置线程池以共享线程资源:
<Executor name="tomcatThreadPool" namePrefix="catalina-exec-"
maxThreads="200" minSpareThreads="20"/>
- 在`<Connector>`元素中引用这个线程池:
executor="tomcatThreadPool"步骤 6: 重启Tomcat
- 保存`server.xml`的更改并重启Tomcat服务器以应用新的配置。
步骤 7: 监控和调整
- 使用监控工具监控Tomcat的性能。
- 根据监控结果调整配置参数,并重新测试。
GC
输出gc日志
jvm的启动参数中加入 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCApplicationStoppedTime -Xloggc:gc.log
启动后输出:GC概要信息、详细信息、gc时间、gc造成的应用暂停时间
-Xloggc:文件名称 ----- 输出gc的信息到一个文件中, 文件只写文件名,就是到 tomcat的bin文件夹下

下载gc日志
https://gceasy.io/
tomcat监控
grafana + prometheus + jvm_exporter
grafana + prometheus 安装搭建详看这里
prometheus 监控 nginx
nginx-module-vts:Nginx virtual host traffic status module,Nginx的监控模块,能够提供JSON格式的数据产出。
nginx-vts-exporter:Simple server that scrapes Nginx vts stats and exports them via HTTP for Prometheus consumption。主要用于收集Nginx的监控数据,并给Prometheus提供监控接口,默认端口号9913。
Prometheus:监控Nginx-vts-exporter提供的Nginx数据,并存储在时序数据库中,可以使用PromQL对时序数据进行查询和聚合。
查看nginx安装了哪些模块
/usr/local/nginx/sbin/nginx -V安装git
sudo yum install git下载nginx-module-vts
git clone https://gitee.com/mirrors/nginx-module-vts.git
进入nginx的解压文件夹,先停止nginx服务,进入nginx目录再执行
./configure --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_ssl_module --add-module=/opt/nginx-module-vts/ --add-module的路径要与上面下载文件路径一致
make 出现这个就安装成功了
替换Nginx启动文件
备份nginx启动文件
cp /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.bak
**停止nginx**
pkill -9 nginx
[root@centos7 objs]# cp /opt/pcre-8.44/nginx-1.19.5/objs /usr/local/nginx/sbin/
cp: 略过目录"/opt/pcre-8.44/nginx-1.19.5/objs"
[root@centos7 objs]# cp /opt/pcre-8.44/nginx-1.19.5/objs/nginx /usr/local/nginx/sbin/
cp:是否覆盖"/usr/local/nginx/sbin/nginx"? y
**启动nginx**
/usr/local/nginx/sbin/nginx
修改Nginx.conf配置文件,试验安装是否成功
http {
vhost_traffic_status_zone;
vhost_traffic_status on;
vhost_traffic_status_filter_by_host on;
}
server {
#设定查看Nginx状态的地址
location /nginx_status {
stub_status on;
access_log off;
vhost_traffic_status_display;
vhost_traffic_status_display_format html;
}
}
配置解析:
1.1 打开vhost过滤:
vhost_traffic_status_filter_by_host on;
开启此功能,在Nginx配置有多个server_name的情况下,会根据不同的server_name进行流量的统计,否则默认会把流量全部计算到第一个server_name上。
1.2 在统计流量的server区域开启vhost_traffic_status,配置
vhost_traffic_status on;
在重新加载 Nginx 配置之前,先检查配置文件的语法是否正确。
sudo /usr/local/nginx/sbin/nginx -t
如果配置文件语法正确,你会看到类似以下的输出:
重新加载Nginx 配置(需要启动Nginx)
sudo /usr/local/nginx/sbin/nginx -s reload访问http://192.168.100.103/nginx_status可以查看是否监控是否成功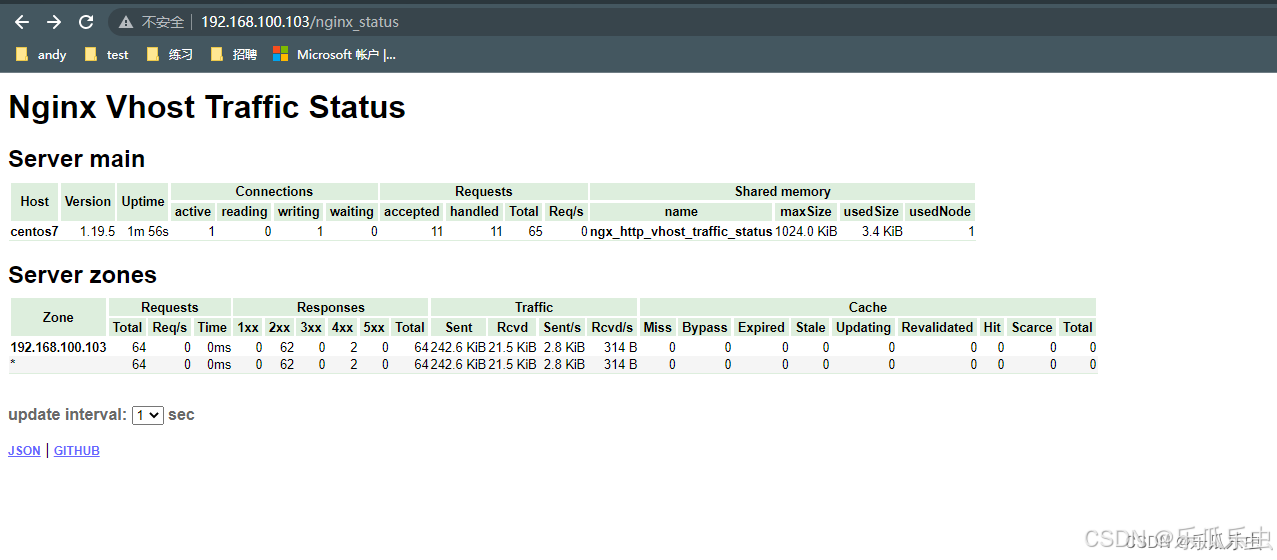
**安装nginx-vts-exporter**
在Prometheus机器上面,安装nginx-vts-exporter
sudo yum install wgetwget https://github.com/hnlq715/nginx-vts-exporter/releases/download/v0.10.3/nginx-vts-exporter-0.10.3.linux-amd64.tar.gztar xvfz nginx-vts-exporter-0.10.3.linux-amd64.tar.gz解压
进入解压后的文件夹
nohup ./nginx-vts-exporter -nginx.scrape_uri=http://localhost/status/format/json &
可以通过 ./nginx-vts-exporter --help 来查看参数帮助
安装nginx-vts-exporter 启动成功,
可以通过浏览器访问 http://ip地址:9913/metrics 如果界面显示数据比较多,说明已经有收集数据,
如果比较少,说明配置还有问题 默认端口为:9913
配置prometheus.yml
- job_name: 'nginx-prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['192.168.100.104:9913']保存配置文件,重启prometheus
./prometheus --config.file=prometheus.yml数据库监控
Prometheus + grafana + xxx_exporter
如果你要监控其他, 你就去github上,搜索 你要个的exporter
mysql监控
下载mysqld_exporter
解压
在解压后的路径中创建‘mysqld_exporter.cnf'配置文件
[client]
user=数据库的用户名
password=数据库的密码
host=数据库的ip地址
port=数据库的端口vim prometheus.yml
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'mysql-exporter'
static_configs:
- targets: ['数据库ip:9104']
模板:7362
redis监控
# 下载
wget https://github.com/oliver006/redis_exporter/releases/download/v1.17.1/redis_exporter-v1.17.1.linux-amd64.tar.gz
# 解压
tar xzf redis_exporter-v1.17.1.linux-amd64.tar.gz
# 启动
cd redis_exporter-v1.17.1.linux-amd64
nohup ./redis_exporter &# 修改配置文件
vim prometheus.yml
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: 'redis-export'
static_configs:
- targets: ['localhost:9121']模板id:763
















 503
503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









