






1.线程和进程
之前看过一篇文章,认为讲的非常到位
总有人说线程是系统调度的最小单位,如此说法真的是含糊不清。线程到底是什么,是一个单位?
也提到线程是进程上划分更细的运行单元,线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反。
那么线程和进程究竟是个什么东西
首先来一句概括的总论:进程和线程都是一个时间段的描述,是CPU工作时间段的描述。
CPU太快了,xGhz = 1秒有 x* 10亿次时钟脉冲信号。
1s = 10亿纳秒
1GHZ = 10亿时钟脉冲信号/ s = 1个时钟周期为1纳秒
一个时钟周期完成的指令数是固定的,所以主频越高,CPU的速度也就越快了。不过由于各种CPU的内部结构也不尽相同,所以并不能完全用主频来概括CPU的性能。但CPU主频的高低可以决定电脑的档次和价格水平。
以Pentium 4 2.0为例,它的工作主频为2.0GHz,这说明了什么呢?具体来说,2.0GHz意味着每秒钟它会产生20亿个时钟脉冲信号,每个时钟信号周期为0.5纳秒。
而Pentium 4 CPU有4条流水线运算单元,如果负载均匀的话,CPU在1个时钟周期内可以进行4个二进制加法运算。这就意味着该Pentium 4 CPU每秒钟可以执行80亿条二进制加法运算。
但如此惊人的运算速度不能完全为用户服务,电脑硬件和操作系统本身还要消耗CPU的资源。
串联起来的事实:前面讲过在CPU看来所有的任务都是一个一个的轮流执行的,具体的轮流方法就是:先加载程序A的上下文,然后开始执行A,保存程序A的上下文,调入下一个要执行的程序B的程序上下文,然后开始执行B,保存程序B的上下文。。。。
进程和线程就是这样的背景出来的,两个名词不过是对应的CPU时间段的描述,名词就是这样的功能。
- 进程就是包换上下文切换的程序执行时间总和 = CPU加载上下文+CPU执行+CPU保存上下文
线程是什么呢?
进程的颗粒度太大,每次都要有上下的调入,保存,调出。如果我们把进程比喻为一个运行在电脑上的软件,那么一个软件的执行不可能是一条逻辑执行的,必定有多个分支和多个程序段,就好比要实现程序A,实际分成 a,b,c等多个块组合而成。那么这里具体的执行就可能变成:
程序A得到CPU =》CPU加载上下文,开始执行程序A的a小段,然后执行A的b小段,然后再执行A的c小段,最后CPU保存A的上下文。
这里a,b,c的执行是共享了A的上下文,CPU在执行的时候没有进行上下文切换的。这里的a,b,c就是线程,也就是说线程是共享了进程的上下文环境,的更为细小的CPU时间段。
到此全文结束,再一个总结:
进程和线程都是一个时间段的描述,是CPU工作时间段的描述,不过是颗粒大小不同。
2.线程共享内存
线程私有:程序计数器,虚拟机栈(存放方法局部变量引用、方法信息等),本地方法栈。
线程共享:堆、方法区(元空间)
3.线程-new-(ready+runnable)-wait-timed-waitting
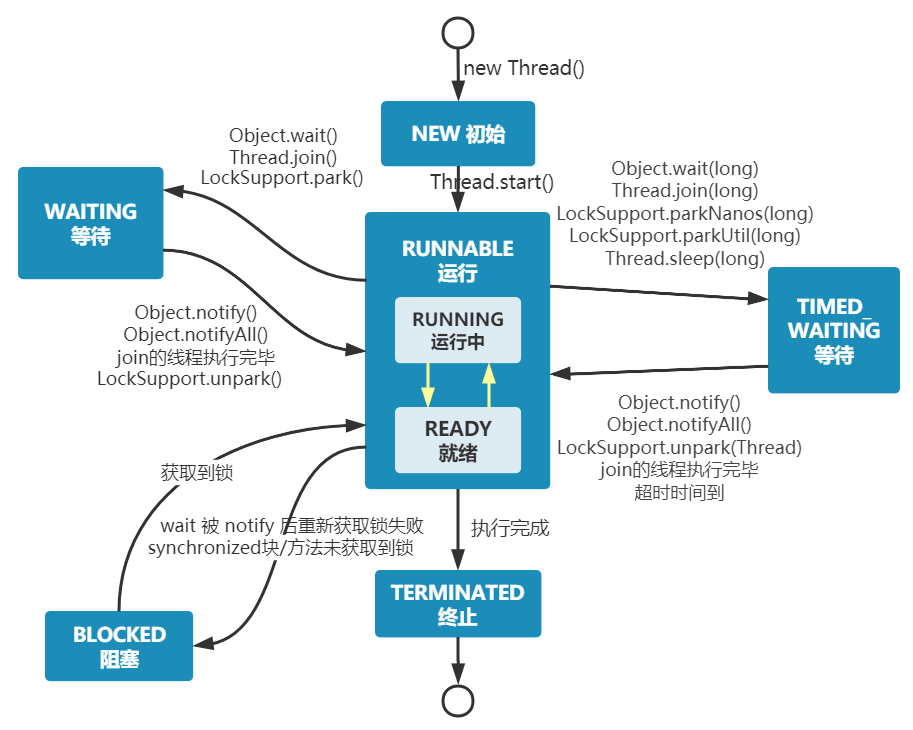
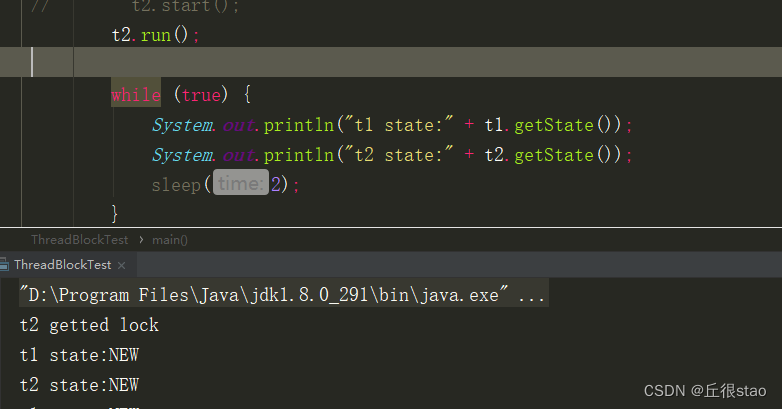
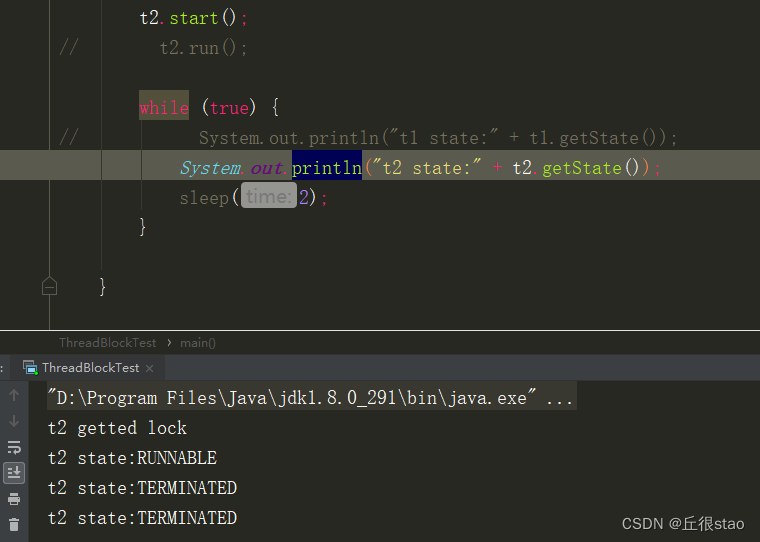
4.thread 的run方法可以直接调用,但是就只会当做一个普通方法执行。start是将线程置为runable。
对比
5.java内存模型和JVM内存结构
- JVM 内存结构和 Java 虚拟机的运行时区域相关,定义了 JVM 在运行时如何分区存储程序数据,就比如说堆主要用于存放对象实例。
- Java 内存模型和 Java 的并发编程相关,抽象了线程和主内存之间的关系就比如说线程之间的共享变量必须存储在主内存中,规定了从 Java 源代码到 CPU 可执行指令的这个转化过程要遵守哪些和并发相关的原则和规范,其主要目的是为了简化多线程编程,增强程序可移植性的。
6. happens-before
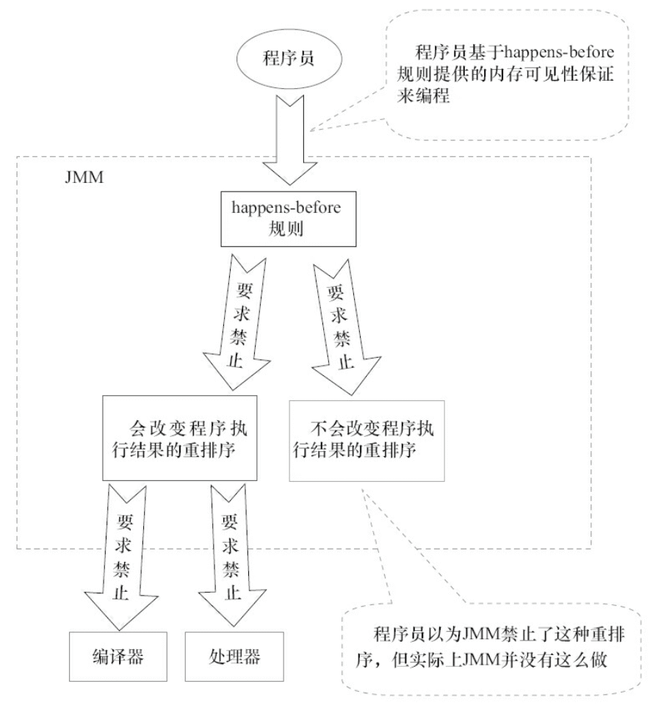
- 程序顺序规则 :一个线程内,按照代码顺序,书写在前面的操作 happens-before 于书写在后面的操作;
- 解锁规则 :解锁 happens-before 于加锁;
- volatile 变量规则 :对一个 volatile 变量的写操作 happens-before 于后面对这个 volatile 变量的读操作。说白了就是对 volatile 变量的写操作的结果对于发生于其后的任何操作都是可见的。
- 传递规则 :如果 A happens-before B,且 B happens-before C,那么 A happens-before C;
- 线程启动规则 :Thread 对象的
start()方法 happens-before 于此线程的每一个动作。
7.手写单例
public class Singleton {
private static volatile Singleton instance;
private Singleton() {
}
public static Singleton getSingletonInstance() {
if (instance != null) {
return instance;
}
synchronized (Singleton.class) {
return instance != null ? instance : new Singleton();
}
}
}8.悲观锁和乐观锁
悲观锁:必须持锁才可以执行程序,共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程。通常用于写比较多的场景
乐观锁: 只有在修改的时候,才去校验资源是否被其他线程修改了。CAS,版本号等策略。通常用于读多写少的场景
9.synchronized
synchronized 同步语句块的实现使用的是 monitorenter 和 monitorexit 指令,其中 monitorenter 指令指向同步代码块的开始位置,monitorexit 指令则指明同步代码块的结束位置。
synchronized 修饰的方法并没有 monitorenter 指令和 monitorexit 指令,取得代之的确实是 ACC_SYNCHRONIZED 标识,该标识指明了该方法是一个同步方法。
10.synchronized和ReentrantLock的区别
10.1 都是可重入锁
10.2 synchronized关键字依赖JVM,ReentrantLock依赖api
10.3 synchronized只能实现非公平锁,ReentrantLock可以实现公平锁和非公平锁
10.4 ReentrantLock可以实现锁中断等待
10.5 ReentrantLock+Condition可以实现选择性通知线程,synchronized不行,如果唤醒就会唤醒所有抢占该对象锁的线程
11.AQS
AQS 为构建锁和同步器提供了一些通用功能的是实现,因此,使用 AQS 能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的 ReentrantLock,Semaphore,CountDownLatch 其他的诸如 ReentrantReadWriteLock,SynchronousQueue等等皆是基于 AQS 的。
AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是用 CLH 队列锁 实现的,即将暂时获取不到锁的线程加入到队列中。















 6164
6164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









