






Basic data types and built-in methods
引言
在上一节中,我们已经对python这门语言的基本语法(数据类型,垃圾回收机制,基本交互,流程控制)有了大概的了解。下面我们将具体认识每一种数据类型的内置方法以及它的详细定义和各类型之间转换。
第一节 数字(Number)
暂略
第二节 字符串(string)
定义
字符串是 Python 中最常用的数据类型。我们可以使用引号( ’ 或 "或’’’)来创建字符串。创建字符串很简单,只要为变量分配一个值即可。例如:
# 定义:在单引号\双引号\三引号内包含一串字符
name1 = 'jason' # 本质:name = str('任意形式内容')
name2 = "lili" # 本质:name = str("任意形式内容")
name3 = """ricky""" # 本质:name = str("""任意形式内容""")
类型转换
数据类型转换:str()可以将任意数据类型转换成字符串类型,例如:
# 数据类型转换:str()可以将任意数据类型转换成字符串类型,例如
>>> type(str([1,2,3])) # list->str
<class 'str'>
>>> type(str({"name":"jason","age":18})) # dict->str
<class 'str'>
>>> type(str((1,2,3))) # tuple->str
<class 'str'>
>>> type(str({1,2,3,4})) # set->str
<class 'str'>
常用操作(★★★★)
str1 = 'hello python!'
# 1.按索引取值(正向取,反向取):
# 1.1 正向取(从左往右)
print(str1[6]) # p
# 1.2 反向取(负号表示从右往左)
print(str1[-4])# h
# 1.3 对于str来说,只能按照索引取值,不能改
str1[0]='H' # 报错TypeError
# 2.切片(顾头不顾尾,步长)
# 2.1 顾头不顾尾:取出索引为0到8的所有字符
print(str1[0:9]) # hello pyt
# 2.2 步长:0:9:2,第三个参数2代表步长,会从0开始,每次累加一个2即可,所以会取出索引0、2、4、6、8的字符
print(str1[0:9:2]) # hlopt
# 2.3 反向切片 -1表示从右往左依次取值
print(str1[::-1] ) # !nohtyp olleh
# 3.长度len
# 3.1 获取字符串的长度,即字符的个数 空格也算字符,但凡存在于引号内的都算作字符)
print(len(str1)) # 13
# 4.成员运算 in 和 not in
# 4.1 int:判断hello 是否在 str1里面
print('hello' in str1) # True
# 4.2 not in:判断tony 是否不在 str1里面
print('tony' not in str1) # True
# 5.strip移除字符串首尾指定的字符(默认移除空格)
# 5.1 括号内不指定字符,默认移除首尾空格
str1 = ' life is short! '
print(str1.strip()) # life is short!
# 5.2 括号内指定字符,移除首尾指定的字符
str2 = '**tony**'
print(str2.strip('*')) # tony
# 6.切分split
# 6.1 括号内不指定字符,默认以空格作为切分符号
str3='hello world'
print(str3.split())# ['hello', 'world']
# 6.2 括号内指定分隔字符,则按照括号内指定的字符切割字符串
str4 = '127.0.0.1'
print(str4.split('.')) #['127', '0', '0', '1'] 注意:split切割得到的结果是列表数据类型
# 7.循环
str5 = '世界你好?'
for line in str5: # 依次取出字符串中每一个字符
print(line)
# 世
# 界
# 你
# 好
# ?

需掌握操作(★★★)
1. strip, lstrip, rstrip
str1 = '**tony***'
print(str1.strip('*')) # 移除左右两边的指定字符
# 'tony'
print(str1.lstrip('*')) # 只移除左边的指定字符
# tony***
print(str1.rstrip('*')) # 只移除右边的指定字符
# **tony
2. lower(),upper()
str2 = 'My nAme is tonY!'
print(str2.lower()) # 将英文字符串全部变小写
# my name is tony!
print(str2.upper()) # 将英文字符串全部变大写
# MY NAME IS TONY!
3. startswith,endswith
str3 = 'tony jam'
# startswith()判断字符串是否以括号内指定的字符开头,结果为布尔值True或False
print(str3.startswith('t'))
#True
print(str3.startswith('j'))
#False
# endswith()判断字符串是否以括号内指定的字符结尾,结果为布尔值True或False
print(str3.endswith('jam'))
#True
print(str3.endswith('tony'))
#False
4. 格式化输出之format
#之前我们使用%s来做字符串的格式化输出操作,在传值时,必须严格按照位置与%s一一对应,
# 而字符串的内置方法format则提供了一种不依赖位置的传值方式
#案例:
# format括号内在传参数时完全可以打乱顺序,但仍然能指名道姓地为指定的参数传值,name=‘tony’就是传给{name}
str4 = 'my name is {name}, my age is {age}!'.format(age=18,name='tony')
print(str4)# 'my name is tony, my age is 18!'
str4 = 'my name is {name}{name}{name}, my age is {name}!'.format(name='tony', age=18)
print(str4) # my name is tonytonytony, my age is tony!
# format的其他使用方式(了解)
# 类似于%s的用法,传入的值会按照位置与{}一一对应
str4 = 'my name is {}, my age is {}!'.format('tony', 18)
print(str4) # my name is tony, my age is 18!
# 把format传入的多个值当作一个列表,然后用{索引}取值
str4 = 'my name is {0}, my age is {1}!'.format('tony', 18)
print(str4) # my name is tony, my age is 18!
str4 = 'my name is {1}, my age is {0}!'.format('tony', 18)
print(str4) # y name is 18, my age is tony!
str4 = 'my name is {1}, my age is {1}!'.format('tony', 18)
print(str4) # my name is 18, my age is 18!

5. split,rsplit
# split会按照从左到右的顺序对字符串进行切分,可以指定切割次数
str5='C:/a/b/c/d.txt'
print(str5.split('/',1)) # ['C:', 'a/b/c/d.txt']
# rsplit刚好与split相反,从右往左切割,可以指定切割次数
str5='a|b|c'
print(str5.rsplit('|',1)) # ['a|b', 'c']
6. join
# 从可迭代对象中取出多个字符串,然后按照指定的分隔符进行拼接,拼接的结果为字符串
'%'.join('hello') # 从字符串'hello'中取出多个字符串,然后按照%作为分隔符号进行拼接
#'h%e%l%l%o'
'|'.join(['tony','18','read']) # 从列表中取出多个字符串,然后按照*作为分隔符号进行拼接
#'tony|18|read'
7.replace
# 用新的字符替换字符串中旧的字符
str7 = 'my name is tony, my age is 18!' # 将tony的年龄由18岁改成73岁
str7 = str7.replace('18', '73') # 语法:replace('旧内容', '新内容')
print(str7) # my name is tony, my age is 73!
# 可以指定修改的个数
str7 = 'my name is tony, my age is 18!'
str7 = str7.replace('my', 'MY',1) # 只把一个my改为MY
print(str7)# MY name is tony, my age is 18!
8. isdigit
# 判断字符串是否是纯数字组成,返回结果为True或False
str8 = '5201314'
print(str8.isdigit()) # True
str8 = '123g123'
print(str8.isdigit()) # False

需了解操作(★)
暂略
第三节 列表(list)
定义
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型。创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
list1 = ['Google', 'Runoob', 1997, 2000];
list2 = [1, 2, 3, 4, 5 ];
list3 = ["a", "b", "c", "d"];
类型转换
但凡能被for循环遍历的数据类型都可以传给list()转换成列表类型,list()会跟for循环一样遍历出数据类型中包含的每一个元素然后放到列表中
# 但凡能被for循环遍历的数据类型都可以传给list()转换成列表类型,list()会跟for循环一样遍历出数据类型中包含的每一个元素然后放到列表中
>>> list('wdad') # 结果:['w', 'd', 'a', 'd']
>>> list([1,2,3]) # 结果:[1, 2, 3]
>>> list({"name":"jason","age":18}) #结果:['name', 'age']
>>> list((1,2,3)) # 结果:[1, 2, 3]
>>> list({1,2,3,4}) # 结果:[1, 2, 3, 4]
常用操作(★★★★)
1. 索引
# 1.按索引存取值(正向存取+反向存取):即可存也可以取
# 1.1 正向取(从左往右)
my_friends=['tony','jason','tom',4,5]
print(my_friends[0]) # tony
# 1.2 反向取(负号表示从右往左)
print(my_friends[-1]) # 5
# 1.3 对于list来说,既可以按照索引取值,又可以按照索引修改指定位置的值,但如果索引不存在则报错
my_friends = ['tony','jack','jason',4,5]
my_friends[1] = 'martthow'
print(my_friends) # ['tony', 'martthow', 'jason', 4, 5]
2. 切片
# 2.切片(顾头不顾尾,步长)
# 2.1 顾头不顾尾:取出索引为0到3的元素
print(my_friends[0:4]) # ['tony', 'jason', 'tom', 4]
# 2.2 步长:0:4:2,第三个参数2代表步长,会从0开始,每次累加一个2即可,所以会取出索引0、2的元素
print(my_friends[0:4:2]) # ['tony', 'tom']
3. 长度
# 3.长度
print(len(my_friends)) # 5
4. in,not in
# 4.成员运算in和not in
print('tony' in my_friends) # True
print('xxx' not in my_friends) # True
5. 添加
# 5.添加
# 5.1 append()列表尾部追加元素
l1 = ['a','b','c'].append('d')
print(l1) # ['a', 'b', 'c', 'd']
# 5.2 extend()一次性在列表尾部添加多个元素
l1.extend(['a','b','c'])
print(l1) # ['a', 'b', 'c', 'd', 'a', 'b', 'c']
# 5.3 insert()在指定位置插入元素
l1.insert(0,"first") # 0表示按索引位置插值
print(l1) # ['first', 'a', 'b', 'c', 'd', 'a', 'b', 'c']
6. 删除
# 6.删除
# 6.1 del
l = [11,22,33,44]
del l[2] # 删除索引为2的元素
print(l) # [11,22,44]
# 6.2 pop()默认删除列表最后一个元素,并将删除的值返回,括号内可以通过加索引值来指定删除元素
l = [11,22,33,22,44]
res=l.pop()
print(res) # 44
res=l.pop(1)
print(res)# 22
# 6.3 remove()括号内指名道姓表示要删除哪个元素,没有返回值
l = [11,22,33,22,44]
print(l.remove(22)) #从左往右查找第一个括号内需要删除的元素 None
7. reverse()
# 7.reverse()颠倒列表内元素顺序
l = [11,22,33,44]
l.reverse()
print(l) # [44,33,22,11]
8. sort()
# 8.sort()给列表内所有元素排序
# 8.1 排序时列表元素之间必须是相同数据类型,不可混搭,否则报错
l = [11,22,3,42,7,55]
l.sort()
print(l)# [3, 7, 11, 22, 42, 55] # 默认从小到大排序
l = [11,22,3,42,7,55]
l.sort(reverse=True) # reverse用来指定是否跌倒排序,默认为False
print(l) # [55, 42, 22, 11, 7, 3]
# 8.2 了解知识:
# 我们常用的数字类型直接比较大小,但其实,字符串、列表等都可以比较大小,原理相同:都是依次比较对应位置的元素的大小,如果分出大小,则无需比较下一个元素,比如
l1=[1,2,3]
l2=[2,]
print(l2 > l1) # True
# 字符之间的大小取决于它们在ASCII表中的先后顺序,越往后越大
s1='abc'
s2='az'
print(s2 > s1) # s1与s2的第一个字符没有分出胜负,但第二个字符'z'>'b',所以s2>s1成立 True
# 所以我们也可以对下面这个列表排序
l = ['A','z','adjk','hello','hea']
l.sort()
print(l) # ['A', 'adjk', 'hea', 'hello','z']
9. 循环
# 9.循环
# 循环遍历my_friends列表里面的值
for line in my_friends:
print(line)
#'tony'
#'jack'
#'jason'
#4
#5
需了解操作(★)
暂略

第四节 元组(tuple)
Python 的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号。元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。单纯用于

定义方式
# 在()内用逗号分隔开多个任意类型的值
>>> countries = ("中国","美国","英国") # 本质:countries = tuple("中国","美国","英国")
# 强调:如果元组内只有一个值,则必须加一个逗号,否则()就只是包含的意思而非定义元组
>>> countries = ("中国",) # 本质:countries = tuple("中国")
类型转换
# 但凡能被for循环的遍历的数据类型都可以传给tuple()转换成元组类型
>>> tuple('wdad') # 结果:('w', 'd', 'a', 'd')
>>> tuple([1,2,3]) # 结果:(1, 2, 3)
>>> tuple({"name":"jason","age":18}) # 结果:('name', 'age')
>>> tuple((1,2,3)) # 结果:(1, 2, 3)
>>> tuple({1,2,3,4}) # 结果:(1, 2, 3, 4)
# tuple()会跟for循环一样遍历出数据类型中包含的每一个元素然后放到元组中
常用操作(★★★)
>>> tuple1 = (1, 'hhaha', 15000.00, 11, 22, 33)
# 1、按索引取值(正向取+反向取):只能取,不能改否则报错!
>>> tuple1[0]
1
>>> tuple1[-2]
22
>>> tuple1[0] = 'hehe' # 报错:TypeError:
# 2、切片(顾头不顾尾,步长)
>>> tuple1[0:6:2]
(1, 15000.0, 22)
# 3、长度
>>> len(tuple1)
6
# 4、成员运算 in 和 not in
>>> 'hhaha' in tuple1
True
>>> 'hhaha' not in tuple1
False
# 5、循环
>>> for line in tuple1:
... print(line)
1
hhaha
15000.0
11
22
33
第五节 字典(dictionary)
定义
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 ,格式如下所示:
# 定义:在{}内用逗号分隔开多元素,每一个元素都是key:value的形式,其中value可以是任意类型,而key则必须是不可变类型,详见第六节,通常key应该是str类型,因为str类型会对value有描述性的功能
info={'name':'tony','age':18,'sex':'male'} #本质info=dict({....})
# 也可以这么定义字典
info=dict(name='tony',age=18,sex='male') # info={'age': 18, 'sex': 'male', 'name': 'tony'}
类型转换
# 转换1:
>>> info=dict([['name','tony'],('age',18)])
>>> info
{'age': 18, 'name': 'tony'}
# 转换2:fromkeys会从元组中取出每个值当做key,然后与None组成key:value放到字典中
>>> {}.fromkeys(('name','age','sex'),None)
{'age': None, 'sex': None, 'name': None}
常用操作(★★★★)
1. 按key存取值
# 1.1 取
dic = {
'name': 'xxx',
'age': 18,
'hobbies': ['play game', 'basketball']
}
print(dic['name']) # 'xxx'
print(dic['hobbies'][1]) # 'basketball'
# 1.2 对于赋值操作,如果key原先不存在于字典,则会新增key:value
dic['gender'] = 'male'
print(dic)
#{'name': 'tony', 'age': 18, 'hobbies': ['play game', 'basketball'],'gender':'male'}
# 1.3 对于赋值操作,如果key原先存在于字典,则会修改对应value的值
dic['name'] = 'tony'
print(dic)
#{'name': 'tony', 'age': 18, 'hobbies': ['play game', 'basketball']}
2. 长度len,3. in和not in,4. 删除
# 2、长度len
print(len(dic))
3
# 3、成员运算in和not in
print('name' in dic ) # 判断某个值是否是字典的key)
True
# 4、删除
print(dic.pop('name') ) # 通过指定字典的key来删除字典的键值对
print(dic)
# {'age': 18, 'hobbies': ['play game', 'basketball']}
5. 键keys(),值values(),键值对items()
# 5、键keys(),值values(),键值对items()
dic = {'age': 18, 'hobbies': ['play game', 'basketball'], 'name': 'xxx'}
# 获取字典所有的key
dic.keys()
# dic.keys()(['name', 'age', 'hobbies'])
# 获取字典所有的value
dic.values()
#dict_values(['xxx', 18, ['play game', 'basketball']])
# 获取字典所有的键值对
dic.items()
# dict_items([('name', 'xxx'), ('age', 18), ('hobbies', ['play game', 'basketball'])])
6. 循环
# 6、循环
# 6.1 默认遍历的是字典的key
>>> for key in dic:
... print(key)
...
age
hobbies
name
# 6.2 只遍历key
>>> for key in dic.keys():
... print(key)
...
age
hobbies
name
# 6.3 只遍历value
>>> for key in dic.values():
... print(key)
...
18
['play game', 'basketball']
xxx
# 6.4 遍历key与value
>>> for key in dic.items():
... print(key)
...
('age', 18)
('hobbies', ['play game', 'basketball'])
('name', 'xxx')

需掌握操作(★★★)
1.get()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> dic.get('k1')
'jason' # key存在,则获取key对应的value值
>>> res=dic.get('xxx') # key不存在,不会报错而是默认返回None
>>> print(res)
None
>>> res=dic.get('xxx',666) # key不存在时,可以设置默认返回的值
>>> print(res)
666
# ps:字典取值建议使用get方法
2.pop()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> v = dic.pop('k2') # 删除指定的key对应的键值对,并返回值
>>> dic
{'k1': 'jason', 'kk2': 'JY'}
>>> v
'Tony'
3.popitem()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> item = dic.popitem() # 随机删除一组键值对,并将删除的键值放到元组内返回
>>> dic
{'k3': 'JY', 'k2': 'Tony'}
>>> item
('k1', 'jason')
4.update()
# 用新字典更新旧字典,有则修改,无则添加
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> dic.update({'k1':'JN','k4':'xxx'})
>>> dic
{'k1': 'JN', 'k3': 'JY', 'k2': 'Tony', 'k4': 'xxx'}
5.fromkeys()
>>> dic = dict.fromkeys(['k1','k2','k3'],[])
>>> dic
{'k1': [], 'k2': [], 'k3': []}
6.setdefault()
# key不存在则新增键值对,并将新增的value返回
>>> dic={'k1':111,'k2':222}
>>> res=dic.setdefault('k3',333)
>>> res
333
>>> dic # 字典中新增了键值对
{'k1': 111, 'k3': 333, 'k2': 222}
# key存在则不做任何修改,并返回已存在key对应的value值
>>> dic={'k1':111,'k2':222}
>>> res=dic.setdefault('k1',666)
>>> res
111
>>> dic # 字典不变
{'k1': 111, 'k2': 222}
第六节 集合(set)

定义
集合(set)是一个无序的不重复元素序列。集合主要用于:去重、关系运算
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
创建格式:
"""
定义:在{}内用逗号分隔开多个元素,集合具备以下三个特点:
1:每个元素必须是不可变类型
2:集合内没有重复的元素
3:集合内元素无序
"""
s = {1,2,3,4} # 本质 s = set({1,2,3,4})
# 注意1:列表类型是索引对应值,字典是key对应值,均可以取得单个指定的值,而集合类型既没有索引也没有key与值对应,所以无法取得单个的值,而且对于集合来说,主要用于去重与关系元素,根本没有取出单个指定值这种需求。
# 注意2:{}既可以用于定义dict,也可以用于定义集合,但是字典内的元素必须是key:value的格式,现在我们想定义一个空字典和空集合,该如何准确去定义两者?
d = {} # 默认是空字典
s = set() # 这才是定义空集合
类型转换
# 但凡能被for循环的遍历的数据类型(强调:遍历出的每一个值都必须为不可变类型)都可以传给set()转换成集合类型
>>> s = set([1,2,3,4])
>>> s1 = set((1,2,3,4))
>>> s2 = set({'name':'jason',})
>>> s3 = set('egon')
>>> s,s1,s2,s3
{1, 2, 3, 4} {1, 2, 3, 4} {'name'} {'e', 'o', 'g', 'n'}
常用操作
1. 关系运算
>>> friends1 = {"zero","kevin","jason","egon"} # 用户1的好友们
>>> friends2 = {"Jy","ricky","jason","egon"} # 用户2的好友们
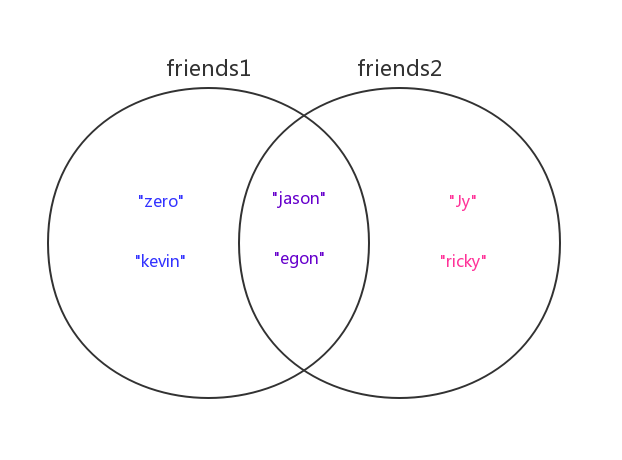
# 1.合集(|):求两个用户所有的好友(重复好友只留一个)
>>> friends1 | friends2
{'kevin', 'ricky', 'zero', 'jason', 'Jy', 'egon'}
# 2.交集(&):求两个用户的共同好友
>>> friends1 & friends2
{'jason', 'egon'}
# 3.差集(-):
>>> friends1 - friends2 # 求用户1独有的好友
{'kevin', 'zero'}
>>> friends2 - friends1 # 求用户2独有的好友
{'ricky', 'Jy'}
# 4.对称差集(^) # 求两个用户独有的好友们(即去掉共有的好友)
>>> friends1 ^ friends2
{'kevin', 'zero', 'ricky', 'Jy'}
# 5.值是否相等(==)
>>> friends1 == friends2
False
# 6.父集:一个集合是否包含另外一个集合
# 6.1 包含则返回True
>>> {1,2,3} > {1,2}
True
>>> {1,2,3} >= {1,2}
True
# 6.2 不存在包含关系,则返回True
>>> {1,2,3} > {1,3,4,5}
False
>>> {1,2,3} >= {1,3,4,5}
False
# 7.子集
>>> {1,2} < {1,2,3}
True
>>> {1,2} <= {1,2,3}
True
2. 去重
只能针对不可变类型
集合本身是无序的,去重之后无法保留原来的顺序
>>> l=['a','b',1,'a','a']
>>> s=set(l)
>>> s # 将列表转成了集合
{'b', 'a', 1}
>>> l_new=list(s) # 再将集合转回列表
>>> l_new
['b', 'a', 1] # 去除了重复,但是打乱了顺序
# 针对不可变类型,并且保证顺序则需要我们自己写代码实现,例如
l=[
{'name':'lili','age':18,'sex':'male'},
{'name':'jack','age':73,'sex':'male'},
{'name':'tom','age':20,'sex':'female'},
{'name':'lili','age':18,'sex':'male'},
{'name':'lili','age':18,'sex':'male'},
]
new_l=[]
for dic in l:
if dic not in new_l:
new_l.append(dic)
print(new_l)
# 结果:既去除了重复,又保证了顺序,而且是针对不可变类型的去重
[
{'age': 18, 'sex': 'male', 'name': 'lili'},
{'age': 73, 'sex': 'male', 'name': 'jack'},
{'age': 20, 'sex': 'female', 'name': 'tom'}
]
3.其他操作
# 1.长度
>>> s={'a','b','c'}
>>> len(s)
3
# 2.成员运算
>>> 'c' in s
True
# 3.循环
>>> for item in s:
... print(item)
...
c
a
b
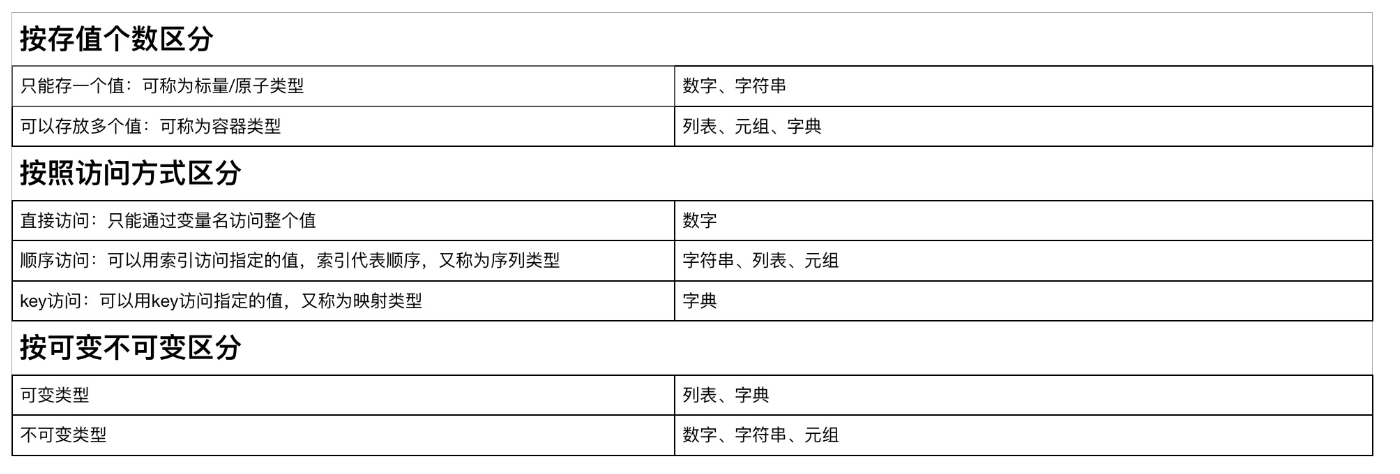
第六节 数据类型总结(Summary of data types)

可变数据类型:值发生改变时,内存地址不变,即id不变,证明在改变原值
不可变类型:值发生改变时,内存地址也发生改变,即id也变,证明是没有在改变原值,是产生了新的值
















 3064
3064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









