






多线程
一 线程池的创建
当我们想要一个线程池的时候,可以通过Executors.newFixedThreadPool来创建指定数量的线程
Thread thread1 = new Thread(new Runnable(){public void run(){
//实现run方法
}}
//其中10代表着线程池想要创建的线程数
ExecutorService service = Executors.newFixedThreadPool(10);
//执行线程,注意到thread1是实现了Runnable接口的run方法的线程
service.execute(thread1);
但newFixedThreadPool其实是调用了ThreadPoolExecutor
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
//也就是
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
//corePoolSize:线程池核心线程数量
//maximumPoolSize:线程池最大线程数量
// keepAliverTime:当活跃线程数大于核心线程数时,空闲的多余线程最大存活时间
//unit:存活时间的单位
// workQueue:存放任务的队列
//handler:超出线程范围和队列容量的任务的处理程序
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
Java提供的常用的四种线程池
- newCachedThreadPool
public static ExecutorService newCachedThreadPool(){
return new ThreadPoolExecutor(0,Integer.Max_VALUE,
60L,TimeUnit.SECONDS,
new SynchronousQueue<RUnnable>())
}
SynchronousQueue不是一个真正的队列,而是一种线程之间移交的机制。要将一个元素放入 SynchronousQueue中,必须有另一个线程正在等待接收这个元素。只有在使用无界线程池或者有饱和策略时才建议使用该队列。
在newCachedThreadPool中如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
- newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads){
return new ThreadPoolExecutor(nThreads,nThreads,
0L,TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>());
}
- newScheduleThreadPool
创建一个定长线程池,支持定时及周期性任务执行。
public static ScheduleExecutorService newScheduleThreadPool(int corePoolSize){
return new ScheduleThreadPoolExecutor(corePoolSize);
}
//ScheduleThreadPoolExecutor 构造函数
public ScheduleThreadPoolExecutor(int corePoolSize){
super(corePoolSize,Integer.MAX_VALUE,0,NANOSECONDS,new DelayWorkQueue());
}
ScheduledThreadPoolExecutor的父类即ThreadPoolExecutor,因此这里各参数含义和上面一样。DelayedWorkQueue是一个无界队列,它能按一定的顺序对工作队列中的元素进行排列。因此这里 设置的最大线程数 Integer.MAX_VALUE没有任何意义。
- newDelayedThreadPool
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务, 保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService(
new ScheduledThreadPoolExecutor(1));
}
//其中DelegatedScheduledExecutorService
DelegatedScheduledExecutorService(ScheduledExecutorService executor) {
super(executor);
e = executor;
}
//而他的父类则是
DelegatedExecutorService(ExecutorService executor) {
e = executor;
}
其实就是使用装饰模式增强了ScheduledExecutorService(1)的功能,不仅确保只有一个线程顺序执 行任务,也保证线程意外终止后会重新创建一个线程继续执行任务。
- newWorkStealingPool
创建一个拥有多个任务队列(以便减少连接数)的线程池。
public static ExecutorService newWorkStealingPool(){
return new ForkJoinPool(Runtime.getRuntime().avaliableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null,true);
}
二 线程池的处理流程
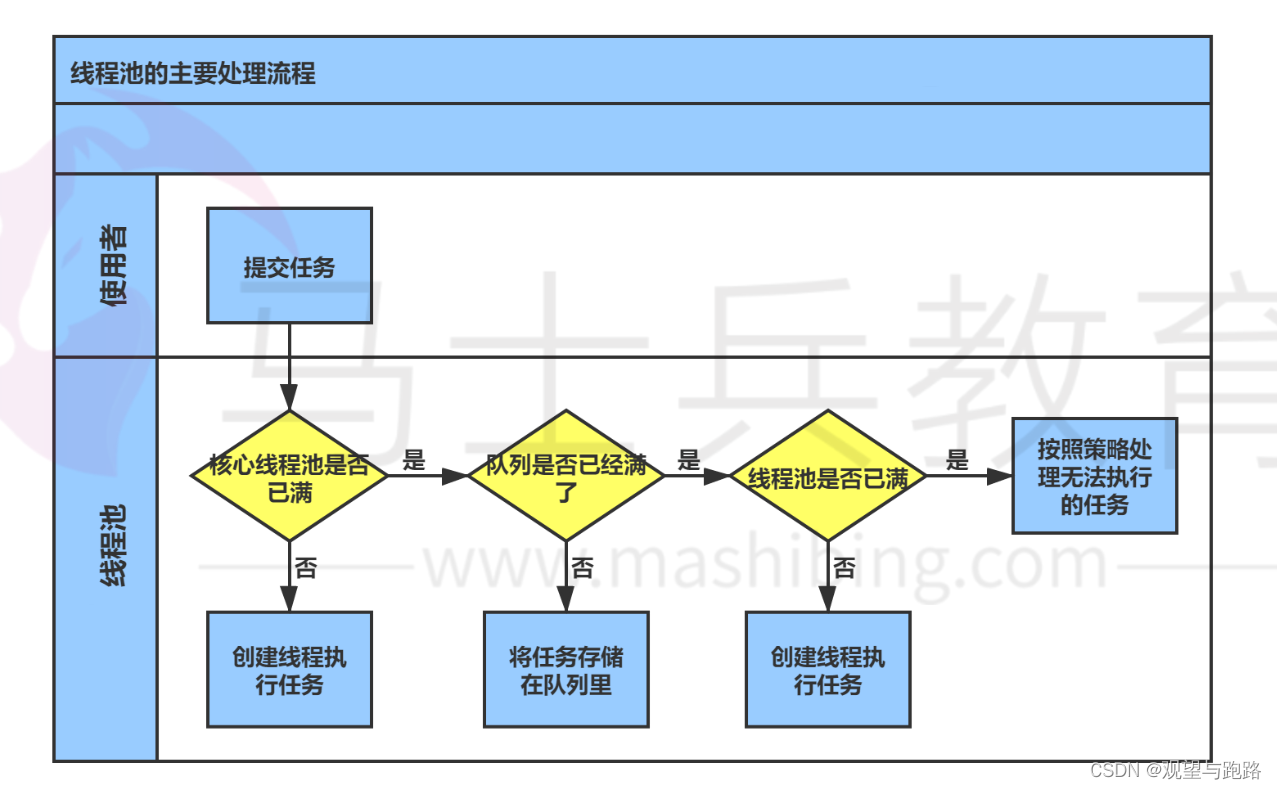
//现在假设我们建立了一个核心线程为5,最大线程为10,空闲的线程最大存活时间为60s,阻塞队列为5的线程池
ThreadPoolExecutor threadPool = ThreadPoolExecutor(5,10,60,TimeUnit.SECONDS,queue)
//从线程池中取16个线程,假设这16个线程都是一直执行不会死亡的。
for(16){
threadPool(new Thread());
sout("活跃线程数为"+threadPool.getPoolSize());
sout("阻塞线程数为"+queue.size());
}
/*
其输出为:
线程池中的活跃线程数:1
线程池中的活跃线程数:2
线程池中的活跃线程数:3
线程池中的活跃线程数:4
线程池中的活跃线程数:5
线程池中的活跃线程数:5
队列中阻塞的线程数1
线程池中的活跃线程数:5
队列中阻塞的线程数2
线程池中的活跃线程数:5
队列中阻塞的线程数3
线程池中的活跃线程数:5
队列中阻塞的线程数4
线程池中的活跃线程数:5
队列中阻塞的线程数5
线程池中的活跃线程数:6
队列中阻塞的线程数5
线程池中的活跃线程数:7
队列中阻塞的线程数5
线程池中的活跃线程数:8
队列中阻塞的线程数5
线程池中的活跃线程数:9
队列中阻塞的线程数5
线程池中的活跃线程数:10
队列中阻塞的线程数5
Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task Thread[Thread15,5,main] rejected from java.util.concurrent.ThreadPoolExecutor@4b67cf4d[Running, pool size = 10, active threads = 10, queued tasks = 5, completed tasks = 0]
at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063)
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379)
at MainTest.main(MainTest.java:20)
*/
分析上述代码的过程,可以发现,前五个线程是直接分配给核心线程的。
线程池中的活跃线程数:1
线程池中的活跃线程数:2
线程池中的活跃线程数:3
线程池中的活跃线程数:4
线程池中的活跃线程数:5
当核心线程池满了以后,此时再要线程,并不会创建新的线程,而是将该要求阻塞,究其原因,我认为是为了等待核心线程池中的某个线程能突然跑完,然后再将该线程分配出去,这样可以节省开辟线程的资源。
线程池中的活跃线程数:5
队列中阻塞的线程数1
线程池中的活跃线程数:5
队列中阻塞的线程数2
线程池中的活跃线程数:5
队列中阻塞的线程数3
线程池中的活跃线程数:5
队列中阻塞的线程数4
线程池中的活跃线程数:5
队列中阻塞的线程数5
但是当队列也满了之后,此时再接到新的线程要求,就会启用非核心线程池的线程。
线程池中的活跃线程数:6
队列中阻塞的线程数5
线程池中的活跃线程数:7
队列中阻塞的线程数5
线程池中的活跃线程数:8
队列中阻塞的线程数5
线程池中的活跃线程数:9
队列中阻塞的线程数5
线程池中的活跃线程数:10
队列中阻塞的线程数5
如果线程池全满了,那么就报错(这是AbortPolicy策略)
Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task Thread[Thread15,5,main] rejected from java.util.concurrent.ThreadPoolExecutor@4b67cf4d[Running, pool size = 10, active threads = 10, queued tasks = 5, completed tasks = 0]
at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063)
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379)
at MainTest.main(MainTest.java:20)
*/
2.1 饱和策略 RejectedExecutionHandler
当线程池全满了,java提供了四种策略。
- AbortPolicy:报错
- CallerRunsPolicy:只调用所在的线程执行任务
- DiscardOldestPolicy:丢弃掉队列中最近的一个任务,并执行当前任务
- DiscardPolicy:直接丢掉,不执行。
那么该如何使用呢?
RejectedExecutionHandler handler = new ThreadPoolExecutor.DiscardOldestPolicy();
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(5,10,60,TimeUnit.SECONDS,queue,handler);
//或者
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(5,10,60,TimeUnit.SECONDS,queue);
threadPool.setRejectedExecutionHandler(new ThreadPoolExecutor.DiscardePolicy());
三 Callable和Runnable
- Callable有返回值,Runnable没有返回值
- Callable实现call(),Runnable实现run()方法
//这是Callable
Callable<Integer> callable = new Callable<>(){
public Integer call(){
//实现体
return 100;
}
}
FutureTask<Integer> future = new FutureTask<>(callable);
//第一种
Thread t1 = new Thread(future);
t1.start();
future.cancel(true);//中途结束执行
future.isCancelled();//返回是否中途结束成功
future.isDone();//程序是否已经执行结束(包括正常和非正常结束)
future.get();//获取线程执行返回的结果,如果线程还未执行结束,则这条语句会阻塞;
// 除此之外,t1.join()也可以阻塞线程,直到线程结束
//第二种
ExecutorService es = Executors.newFixedThreadPool(10);
es.submit(future);
es.shutdown();
//第三种
ExecutorService es = Executors.newFixedThreadPool(10);
Futuer<Integer> future = es.submit(callable);
es.shutdown();
//这是Runnable
Runnable runnable = new Runnable(){
public void run(){
//实现体
}
}
//第一种
Thread t1 = new Thread(runnable);
t1.start();
//第二种
ExecutorService es = Executors.newFixedThreadPool(10);
es.submit(runnable);
es.shutdown();
四 java锁机制
-
悲观锁(天下所有人都要害我!)
认为所有访问资源行为都有可能导致资源被同时访问,所以在访问前先获得锁,这样就只有获得所得人才有资格访问资源。
互斥同步锁也叫做阻塞同步锁,特征是会对没有获取锁的线程进行阻塞。互斥同步锁是可重入锁。可重入锁的意思就是可以对自己反复加锁。
互斥同步锁有两种:- Synchorized
- ReentrantLock
互斥同步锁都是可重入锁,好处是可以保证不会死锁。但是因为涉及到核心态和用户态的切换,因此比 较消耗性能。
-
乐观锁 ( 天下间还是好人多啊!)
认为访问行为不一定会导致资源被同时访问,可以先对值进行修改,然后根据主存中的旧值进行比较,如果一开始主存的值和后来的不一样,说明我在操作的过程中,有别的线程访问过了,那我修改的值就不能写入主存,而是不断的访问主存,知道前后两个时刻的主存值一致,才可以将我修改的值写入主存。
相比悲观锁来说,它会先进行资源在工作内存中的更新,然后根据与主存中 旧值的对比来确定在此期间是否有其他线程对共享资源进行了更新,如果旧值与期望值相同,就认为没 有更新,可以把新值写回内存,否则就一直重试直到成功。 -
无同步方案
1)可重入代码 在执行的任何时刻都可以中断-重入执行而不会产生冲突。特点就是不会依赖堆上的共享资源
2)ThreadLocal/Volaitile 线程本地的变量,每个线程获取一份共享变量的拷贝,单独进行处理。
3) 线程本地存储 如果一个共享资源一定要被多线程共享,可以尽量让一个线程完成所有的处理操作,比如生产者消费者 模式中,一般会让一个消费者完成对队列上资源的消费。
五 Volatile,ThreadLocal
volatile变量进行写操作时,JVM 会向处理器发送一条 Lock 前缀的指令,将这个变量所在缓存行的数据写会到系统内存。 Lock 前缀指令实际上相当于一个内存屏障(也成内存栅栏),它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成。
看了一些blog,但还是有些不懂,但记住volatile有两个功能:
- 内存屏障,防止指令重排序导致的代码执行错误
- 可见性,被volatile标记的变量修改后会直接写回到主存,可以被所有线程看到。
ThreadLocal是用来维护本线程的变量的,并不能解决共享变量的并发问题。ThreadLocal是各线程将值存入该线程的map中,以ThreadLocal自身作为key,需要用时获得的是该线程之前存入的值。如果存入的是共享变量,那取出的也是共享变量,并发问题还是存在的。
Thread 类中有一句定义
ThreadLocal.ThreadLocalMap threadLocals = null;
说明了,每个Thread 对应一个ThreadLocalMap,
而ThreadLocalMap中有一个静态内部类:
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
private static final int INITIAL_CAPACITY = 16;
说明了一个ThreadLocalMap中可以存放16个Entry,ThreadLocal被包装成弱引用对象。
ThreadLocal的set方法
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
map.set(this, value);
} else {
createMap(t, value);
}
}
ThreadLocalMap 中 private Entry[] table 的 初始大小是16。超过容量的2/3时,会扩容。
ThreadLocalMap的垃圾回收
如果线程可以活很长的时间,并且该线程保存的线程局部变量有很多(也就是 Entry 对象很多),那么就涉 及到在线程的生命期内如何回收 ThreadLocalMap 的内存了,不然的话,Entry对象越多,那么 ThreadLocalMap 就会越来越大,占用的内存就会越来越多,所以对于已经不需要了的线程局部变量, 就应该清理掉其对应的Entry对象。 使用的方式是,Entry对象的key是WeakReference 的包装,当ThreadLocalMap 的 private Entry[] table ,已经被占用达到了三分之二时 threshold = 2/3 (也就是线程拥有的局部变量超过了10个) , 就会尝试回收 Entry 对象
ThreadLocal的垃圾回收
当线程死亡时,那么所有的保存在的线程局部变量就会被回收,其实这里是指线程Thread对象中的 ThreadLocal.ThreadLocalMap threadLocals 会被回收,这是显然的。
ThreadLocal可能引起的OOM内存溢出问题简要分析
ThreadLocal在没有线程池使用的情况下,正常情况下不会存在内存泄露,但是如果使用了 线程池的话,就依赖于线程池的实现,如果线程池不销毁线程的话,那么就会存在内存泄露。所以我们 在使用线程池的时候,使用ThreadLocal要格外小心!
六、synchronized,volatile区别
- volatile主要应用在多个线程对实例变量更改的场合,刷新主内存共享变量的值从而使得各个线程可以获得最新的值,线程读取变量的值需要从主存中读取;synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。另外,synchronized还会创建一个内存屏障,内存屏障指令保证了所有CPU操作结果都会直接刷到主存中(即释放锁前),从而保证了操作的内存可见性。
- volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别。 volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞,比如多个线程争抢 synchronized锁对象时,会出现阻塞。
- volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量可见性和原子性,因为线程获得锁才能进入临界区,从而保证临界区中的所有语句全部得到执行。
- volatile标记的变量不会被编译器优化,可以禁止进行指令重排;synchronized标记的变量可以被编译器优化。
java内存模 型中定义了8种操作都是原子的,不可再分的。
- lock(锁定):作用于主内存中的变量,它把一个变量标识为一个线程独占的状态;
- unlock(解锁):作用于主内存中的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可 以被其他线程锁定
- read(读取):作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便 后面的load动作使用;
- load(载入):作用于工作内存中的变量,它把read操作从主内存中得到的变量值放入工作内存中 的变量副本
- use(使用):作用于工作内存中的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚 拟机遇到一个需要使用到变量的值的字节码指令时将会执行这个操作;
- assign(赋值):作用于工作内存中的变量,它把一个从执行引擎接收到的值赋给工作内存的变 量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作;
- store(存储):作用于工作内存的变量,它把工作内存中一个变量的值传送给主内存中以便随后 的write操作使用;
- write(操作):作用于主内存的变量,它把store操作从工作内存中得到的变量的值放入主内存的 变量中。
6.1 类锁 对象锁
类锁:类锁是加在类上的,而类信息是存在JVM 方法区的,并且整个JVM 只有一份,方法区又是所有线程共享的,所以类锁是所有线程共享的。只要有一个线程获得了类锁,那么其他所有线程都无法访问该类的任何类容。
类锁的使用方法:
- 类中的静态变量
public class Test{
public static Object lock = new Object();
public void test(){
synchronized(lock){
//锁住!因为静态变量和类信息一样也是存在方法区的并且整个JVM只有一份,
//所以加在静态变量上可以达到类锁的目的。
}
}
}
- 类名
public class Test{
public void test(){
synchronized(Test.class){
//锁住!因为类信息在方法区的并且整个JVM只有一份
}
}
}
- 类中的静态方法
public class Test{
public static synchronized void test(Test.class){
//锁住!因为静态方法在方法区的并且整个JVM只有一份
}
}
对象锁:对象锁是每个实例独一份的,只有当多个线程对同一实例进行操作时才会被影响
对象锁的使用方法
4. 对局部变量加锁
public class Test{
public Object lock = new Object();
public void test(){
synchronized(lock){
//锁住!
}
}
}
- this对象锁
public class Test{
public void test(){
synchronized(this){
//锁住!
}
}
}
- 非静态方法上加锁
public class Test{
public synchronized void test(){
//锁住!
}
}
七 进程通讯方式
Linux进程间通信方式
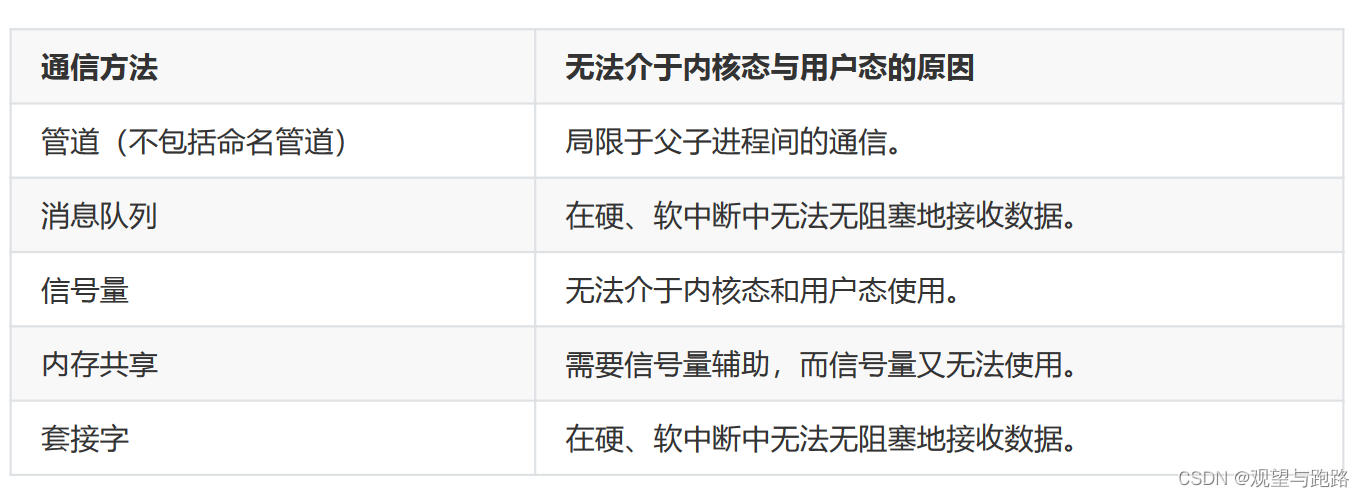
- 信号
信号又称软终端,通知程序发生异步事件,程序执行中随时被各种信号中断,进程可以忽略该信号,也 可以中断当前程序转而去处理信号,引起信号原因:
1).程序中执行错误码;
2).其他进程发送来的;
3).用户通过控制终端发送来;
4).子进程结束时向父进程发送SIGCLD;
5).定时器生产的SIGALRM; - 管道
管道的优点是不需要加锁,缺点是默认缓冲区太小,只有4K,同时只适合父子进程间通信,而且一个管 道只适合单向通信,如果要双向通信需要建立两个。而且不适合多个子进程,因为消息会乱,它的发送 接收机制是用read/write这种适用流的,缺点是数据本身没有边界,需要应用程序自己解释,而一般消 息大多是一个固定长的消息头,和一个变长的消息体,一个子进程从管道read到消息头后,消息体可能 被别的子进程接收到。
管道是单向,一段输入,另一端输出,先进先出FIFO。管道也是文件。管道大小4096字节。
特点:管道满时,写阻塞;空时,读阻塞。
分类:普通管道(仅父子进程间通信)位于内存;命名管道位于文件系统,没有亲缘关系管道只要知道 管道名也可以通讯。
管道是由内核管理的一个缓冲区(buffer),相当于我们放入内存中的一个纸条。管道的一端连接一个进程 的输出。这个进程会向管道中放入信息。管道的另一端连接一个进程的输入,这个进程取出被放入管道 的信息。一个缓冲区不需要很大,它被设计成为环形的数据结构,以便管道可以被循环利用。当管道中 没有信息的话,从管道中读取的进程会等待,直到另一端的进程放入信息。当管道被放满信息的时候, 尝试放入信息的进程会等待,直到另一端的进程取出信息。当两个进程都终结的时候,管道也自动消失。 - 消息队列
消息队列也不要加锁,默认缓冲区和单消息上限都要大一些,它并不局限于父子进程间通信,只要一个相同的key,就可以让不同的进程定位到同一个消息队列上,它也可以用来给双向通信,不过稍微加个标识,可以通过消息中的type进行区分,比如一个任务分派进程,创建了若干个执行子进程,不管是父进程发送分派任务的消息,还是子进程发送任务执行的消息,都将type设置为目标进程的pid,因为msgrcv可以指定只接收消息类型为type的消息,这样就实现了子进程只接收自己的 任务,父进程只接收任务结果。 - 信号量
信号量是一种用于提供不同进程间或一个进程间的不同线程间线程同步手段的原语,systemV信号量在 内核中维护 二值信号量 : 其值只有0、1 两种选择,0表示资源被锁,1表示资源可用; 计数信号量:其值在0 和某个限定值之间,不限定资源数只在0 1 之间; 计数信号量集 ;多个信号量的集合组成信号量集 - 内存共享
共享内存几乎可以认为没有上限,它也是不局限与父子进程,采用跟消息队列类似的定位方式,因为内存是共享的,不存在任何单向的限制,最大的问题就是需要应用程序自己做互斥,有如下几种方案
1)只适用两个进程共享,在内存中放一个标志位,一定要声明为volatile,大家基于标志位来互斥,例如 为0时第一个可以写,第二个就等待,为1时第一个等待,第二个可以写/读
2 )也只适用两个进程,是用信号,大家等待不同的信号,第一个写完了发送信号2,等待信号1,第二个 等待信号2,收到后读取/写入完,发送信号1,它不是用更多进程是因为虽然父进程可以向不同子进程分 别发送信号,但是子进程收到信号会同时访问共享内存,产生不同子进程间的竞态条件,如果用多块共 享内存,又存在子进程发送结果通知信号时,父进程收到信号后,不知道是谁发送,也意味着不知道访问哪块共享内存,即使子进程发送不同的结果通知信号,因为等待信号的一定是阻塞的,如果某个子 进程意外终止,父进程将永远阻塞下去,而不能超时处理
3 )采用信号量或者msgctl自己的加锁、解锁功能,不过后者只适用于linux - 套接字
7.1 wait和notify
- wait( ),notify( ),notifyAll( )都不属于Thread类,而是属于Object基础类,也就是每个对象都有 wait( ),notify( ),notifyAll( ) 的功能,因为每个对象都有锁,锁是每个对象的基础,当然操作锁的方法也是最基础了。
- 当需要调用以上的方法的时候,一定要对竞争资源进行加锁,如果不加锁的话,则会报 IllegalMonitorStateException 异常
- 当想要调用wait( )进行线程等待时,必须要取得这个锁对象的控制权(对象监视器),一般是放到 synchronized(obj)代码中。
- 在while循环里而不是if语句下使用wait,这样,会在线程暂停恢复后都检查wait的条件,并在条件 实际上并未改变的情况下处理唤醒通知
- 调用obj.wait( )释放obj的锁,否则其他线程也无法获得obj的锁,也就无法在synchronized(obj){ obj.notify() } 代码段内唤醒A。
- notify( )方法只会通知等待队列中的第一个相关线程(不会通知优先级比较高的线程)
- notifyAll( )通知所有等待该竞争资源的线程(也不会按照线程的优先级来执行)
- 假设有三个线程执行了obj.wait( ),那么obj.notifyAll( )则能全部唤醒tread1,thread2, thread3,但是要继续执行obj.wait()的下一条语句,必须获得obj锁,因此,tread1,thread2,thread3只有一个有机会获得锁继续执行,例如tread1,其余的需要等待thread1释放 obj锁之后才能继续执行。
- 当调用obj.notify/notifyAll后,调用线程依旧持有obj锁,因此,thread1,thread2,thread3虽被 唤醒,但是仍无法获得obj锁。直到调用线程退出synchronized块,释放obj锁后,thread1, thread2,thread3中的一个才有机会获得锁继续执行。
八 等待线程结束
8.1 如果想等待线程结束后继续执行主线程
前面提过两种阻塞的方法,future.get()和thread.join(),具体看第三章。不过这些都是适用于一条额外线程的。如果多线程的话,就比较麻烦了。
下面这方法相当于弄了个计数器,每个线程结束时,自减一下,计数器为0时,表示全部线程结束
public class MainThread {
public static void main(String[] args) throws InterruptedException {
int threads = 5; //先指定多少条线程
CountDownLatch counts = new CountDownLatch(5);//计数器
for (int i = 0; i < threads; i++) {
SubThread thread = new SubThread(2000 * (i + 1), counts); //让每个线程都持有这个公共的计数器
thread.start();
}
counts.await();//等待直到计数器为0
}
}
class SubThread extends Thread{
private CountDownLatch countDownLatch;
private long work;
public SubThread(long work,CountDownLatch countDownLatch){
this.countDownLatch = countDownLatch;
this.work = work;
}
@Override
public void run() {
try {
Thread.sleep(1000);
System.out.println(work);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}finally {
countDownLatch.countDown();//线程结束时,必定减一
}
}
}















 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









