






语音识别数学表示:argmax p(W|O)=argmax p(O|W)p(W)
W:输出的文本序列
O:输入的语音波形序列
语音识别两大组成部分:
1:p(O|W),在给定的文本序列下,模型生成语音波形序列的概率
称为声学模型(Acoustic Model) 占据主要的计算任务
2:p(W),表示输出W文本序列的概率
称为语言模型(Language Model)
语音识别的过程:
声波:

预处理(前端处理):
1,首尾端静音切除,减少对后续操作的干扰
2,降噪
3,分帧,一般取20-30MS,分帧后的稳态信息才可以进行信号处理。

移动窗口实现,每次往前移动10MS进行分帧,交替部分为了保持语音信息的上下文联系。
声学特征提取(语音特征):
理解:语音的波形在一维时间上无法进行描述,不能作为输入在模型中进行训练,所以要进行波形的变换(FFT快速傅里叶变换),将其他的参数作为语音特征。
目前最常用的语音特征:MFCC(梅尔倒谱系数)
梅尔频率倒谱系数:将线性频谱映射到基于听觉感知的Mel非线性频谱中,再进行倒谱分析得到特征参数。
过程:

将普通频率转化到Mel频率的公式:

Mel滤波:将不统一的频率转化成统一的频率,如果两端语音的Mel频率相差两倍,那么人耳听起来的音调也相差两倍。

倒谱分析:取对数加逆变换(DCT离散余弦变换),得到一组系数(12个),这组MFCC就是这帧语音的特征,对于一段划分为N帧的语音,那么输入矩阵的大小就是12*N。
神经网络:
RNN模型(循环神经网络recurrent neural network):
处理序列数据,即数据在时间或者次序上具有前后联系,很明显语音信号是具有强烈的前后联系的。

RNN的正向传播:

模型的参数训练:反向传播梯度下降算法。
目前使用较多的两种RNN的变形:
LSTM模型(长短时记忆网络),解决RNN前后文关联序列距离太长时引起的梯度消失问题
改进处:增加了3个门运算,“遗忘门”,“输入门”,“输出门”
每个LSTM单元都包括三个输入:上一时刻的单元状态Ct-1、上一时刻的单元输出ht-1,以及当前时刻的输入Xt
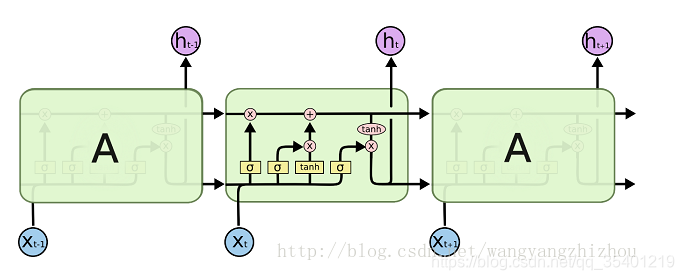
处理机制:
遗忘门:主要计算需要丢弃哪些信息


输入门:用于计算哪些信息保存在状态单元中


最后由之前得到的遗忘门的输出ft以及上一时刻状态Ct-1的积加上输入门两部分的乘积得到当前时刻的单元状态Ct

输出门:通过sigmoid函数计算需要输出哪些信息,与当前的状态Ct经过tanh函数后进行乘积得到当前的输出

总结:从LSTM的网络模型可以看出来,其实LSTM实际上是通过多次累加运算,使得在梯度下降求解时,不会因为链式法则的求导连乘而导致经过sigmoid函数的输出值越来越小直至趋向于0,导致梯度消失的情况。
例如RNN神经网络,他的当前状态计算公式是St=f(Xt,St-1),如果关系距离过远,会导致梯度消失的问题。
GRU模型(门控制循环单元):属于LSTM的一个变形,基于LSTM较为复杂的门结构,改为了只有两个门运算,
分别为更新门和重置门,原理差不多。
损失函数:CTC loss function(Connectionist temporal classification)。。。。。。。??
语言模型:自然语言处理,根据声学模型的输出,给出最大概率的文本输出。
N-gram。。。。?基于RNN的语言模型。。。??















 2465
2465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









