







Elasticsearch 使用的是标准的 RESTful 风格的 API 和 JSON。此外,官方还构建和维护了很多其他语言的客户端,例如 Java、Python、.NET、SQL 和 PHP。与此同时,社区也贡献了很多客户端。这些客户端使用起来简单自然,而且就像 Elasticsearch 一样,不会对我们的使用方式进行限制。
在这一part,我们先回顾Elasticsearch的基本命令,后续再回顾ES再Java中的使用。
1、Restful风格
RESTFUL是一种网络应用程序的设计风格和开发方式,基于HTTP,可以使用XML格式定义或JSON格式定义。RESTFUL适用于移动互联网厂商作为业务接口的场景,实现第三方OTT调用移动网络资源的功能,动作类型为新增、变更、删除所调用资源。
Restful风格经常用,就不过多介绍了,看到本文的应该都是已经知道Restful的。
2、 Elasticsearch常用操作
演示的Elasticsearch版本为7.6.2
2.1、 索引操作
2.1.1创建没有结构的索引
PUT ip地址:端口号/索引名
路径:ip地址:端口号/索引名
注:在kibana中所有的请求都会省略ip地址:端口号,之后的路径我们省略写ip地址:端口号,请求方式:PUT
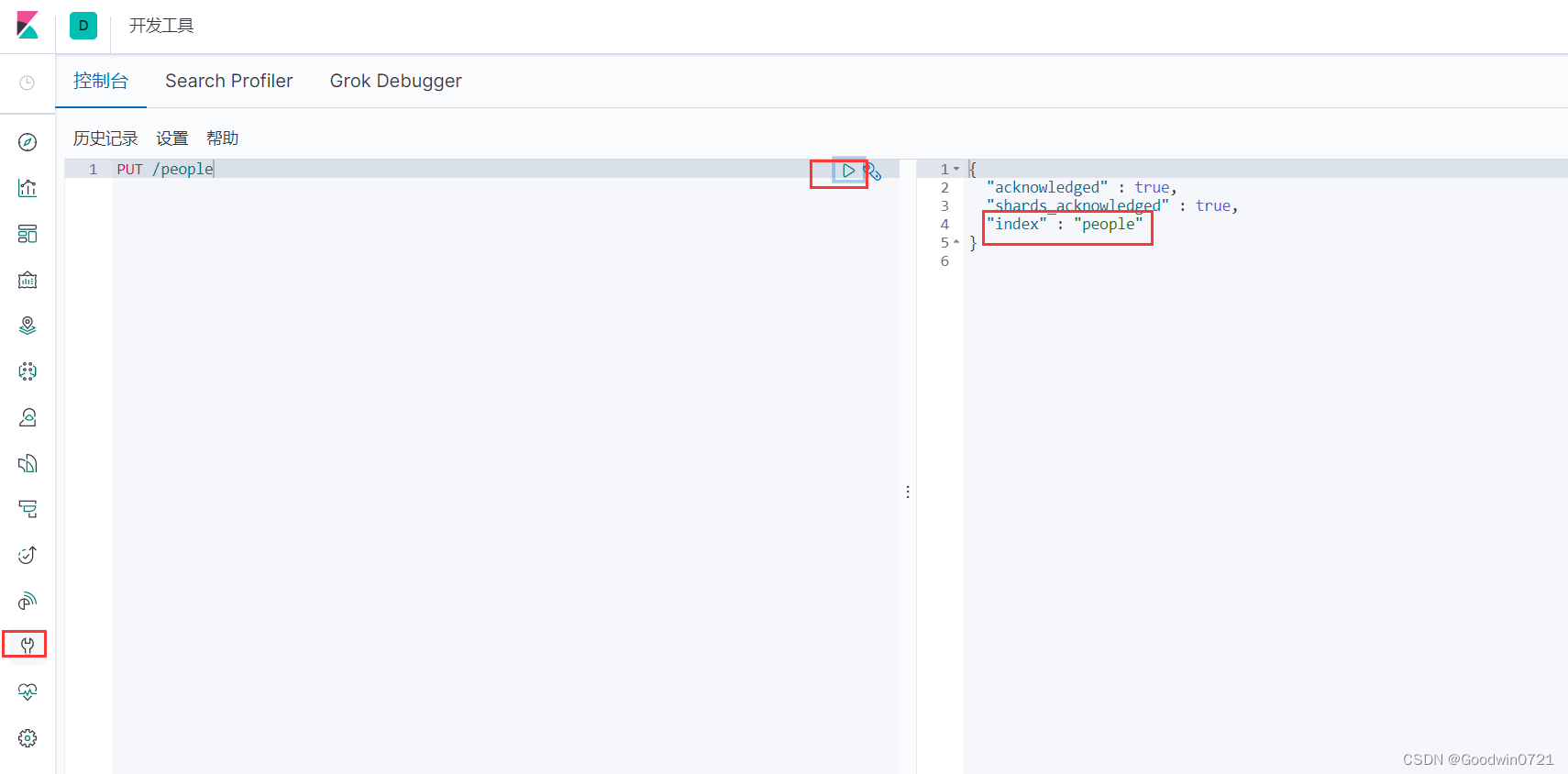

2.1.2为索引添加结构
POST /索引名/_mapping
{
"properties":{
"域名1":{
"type":域的类型,
"store":是否存储,
"index":是否创建索引,
"analyzer":分词器
},
"域名2":{
...
}
}
}
- 域的类型:
| 核心类型 | 具体类型 |
|---|---|
| 字符串类型 | text |
| 整数类型 | long,integer,short,byte |
| 浮点类型 | double,float |
| 日期类型 | date |
| 布尔类型 | boolean |
| 数组类型 | array |
| 对象类型 | object |
| 不进行分词的字符串 | keyword |
index:该域是否创建索引。只有值设置为true,才能根据该域的关键词查询文档。store:是否单独存储。如果设置为true,则该域能够单独查询。
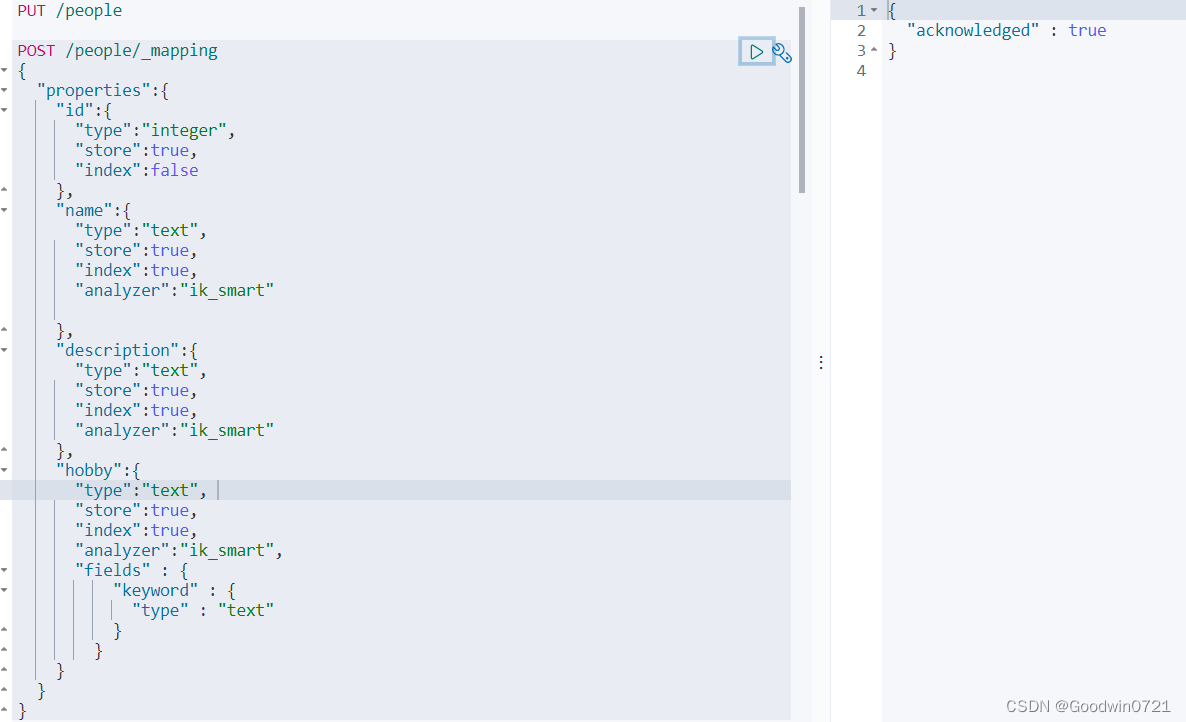
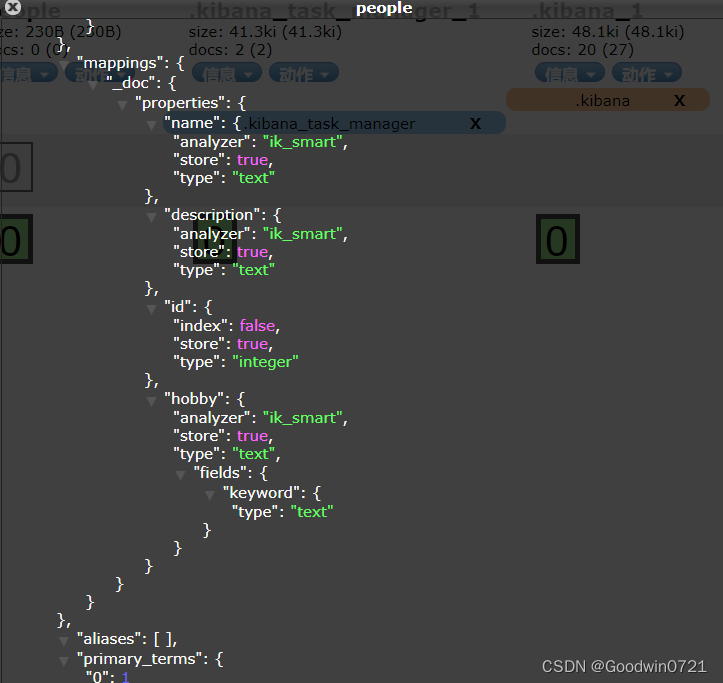
2.1.3创建有结构的索引
PUT /索引名
{
"mappings":{
"properties":{
"域名1":{
"type":域的类型,
"store":是否单独存储,
"index":是否创建索引,
"analyzer":分词器
},
"域名2":{
...
}
}
}
}
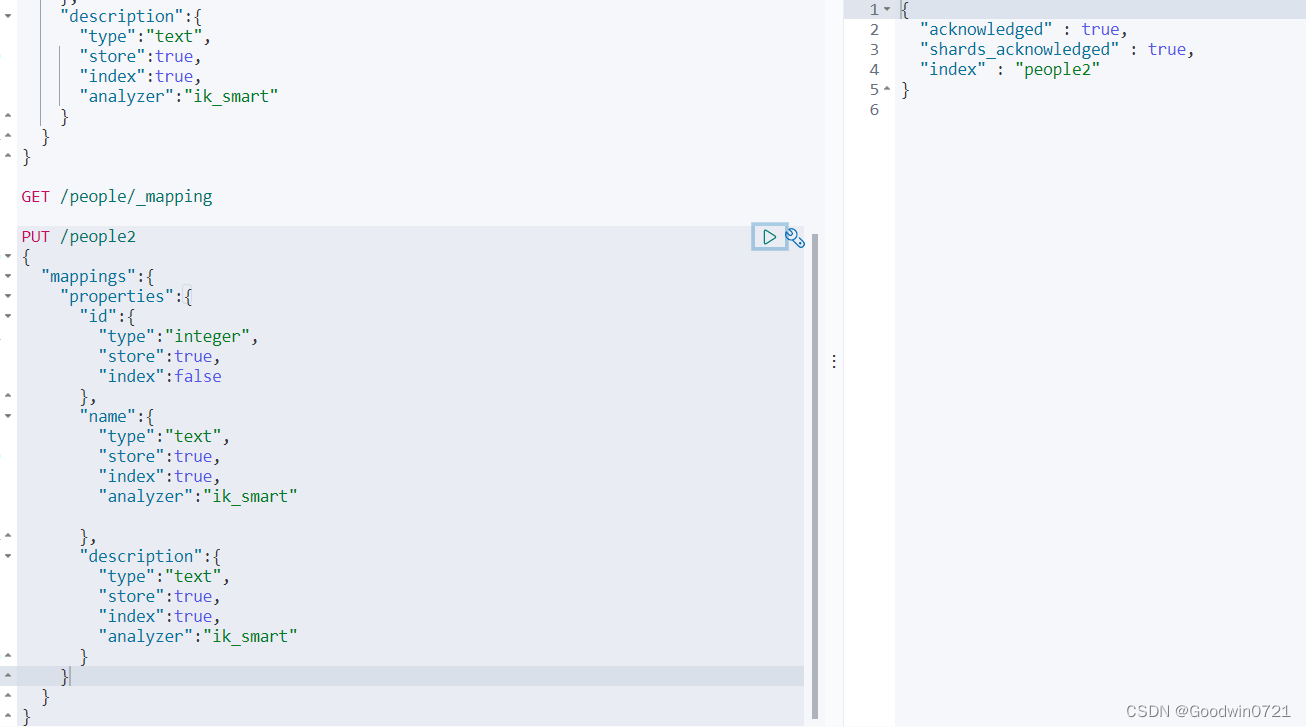
2.1.4删除索引
DELETE /索引名

2.2 文档操作
| method | url地址 | 描述 |
|---|---|---|
| PUT(创建,修改) | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST(创建) | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST(修改) | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE(删除) | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET(查询) | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档ID |
| POST(查询) | localhost:9200/索引名称/类型名称/文档id/_search | 查询所有数据 |
2.2.1 新增
PUT方式
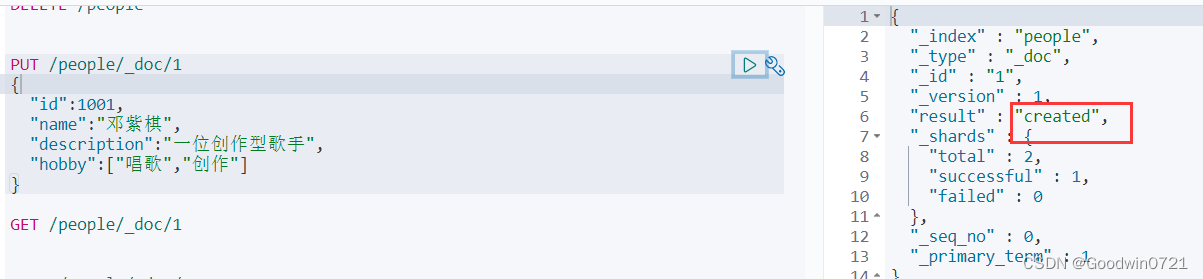
PUT /索引/_doc/id值
{
"field名":field值
}
_doc 默认类型(default type),type 在未来的版本中会逐渐弃用,因此产生一个默认类型进行代替。
POST方式
POST /索引/_doc/[id值]
{
"field名":field值
}
id值不写时自动生成文档 id,id 和已有 id重复时修改文档。
-
写
id

-
不写
id
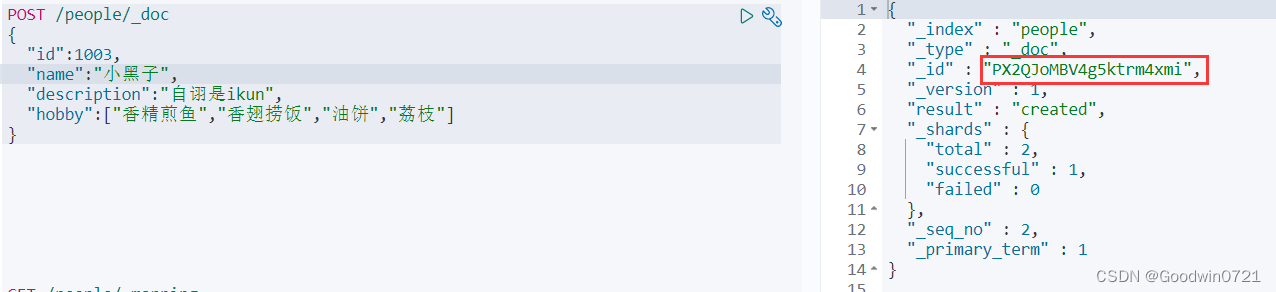
可以看到,id是个随机生成的。
我们对已有的id进行新增
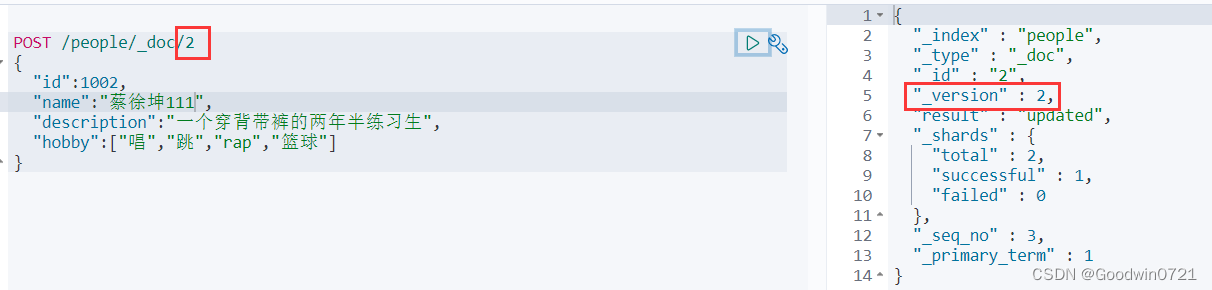
这时,_version增加了1。
2.2.2 修改
有两种方式:
-
通过新增同一个
id进行覆盖
上面使用POST对id为2的进行重复插入时修改了name,接下来我们尝试部分数据进行修改,故意省略不修改部分数据
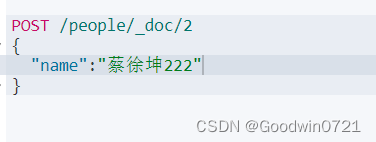
结果发现,省略的部分已经丢失

重新插入原来的数据,使用PUT命令重复以上实验,结果相同。

通过以上方式修改,发现
1.版本+1(_version)
2.但是如果漏掉某个字段没有写,那么更新是没有写的字段 ,会消失。 -
通过以下
_update命令修改
POST /索引/_doc/id值/_update
{
"doc":{
域名:值
}
}
先将上面修改的2号数据恢复一下。

修改

查看结果,发现没有修改的域没有丢失,而且修改成功了!

修改成功的时候,发现上面显示一段红字
#! Deprecation: [types removal] Specifying types in document update requests is deprecated, use the endpoint
/{index}/_update/{id}instead.
我们尝试用该命令修改,也可以成功修改(我也是第一次发现这个 = _ = !)


通过以上方式修改,发现
1.版本+1(_version)(有些人说这个版本不会改变,我上面修改显示_version也会变化)
2.如果漏掉某个字段没有写,也不会丢失数据。
综上所述,建议使用POST /索引/_doc/id值/_update 或POST /索引/_update/id值进行修改。
2.2.3 删除
DELETE /索引/_doc/id值
先查一下,看到版本是13
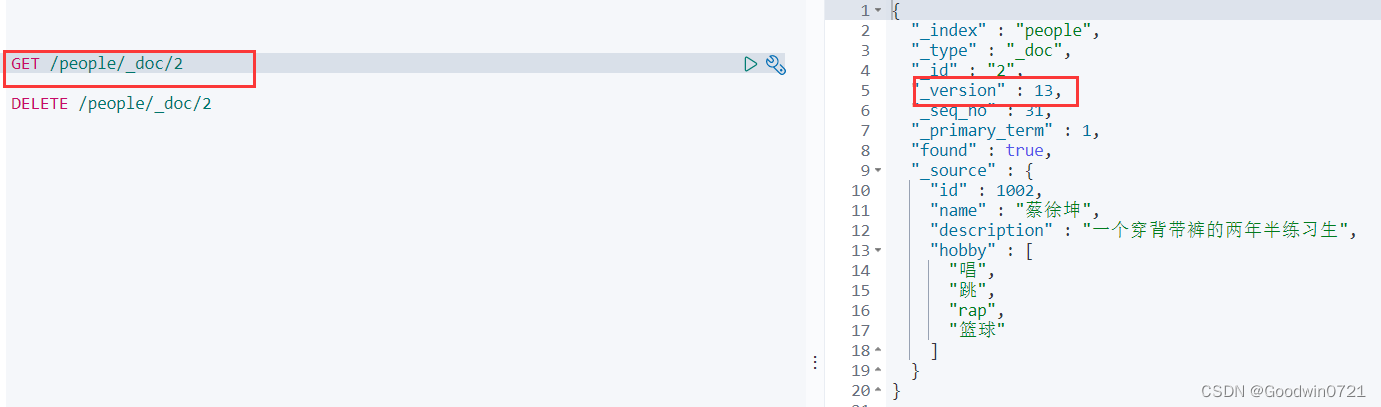

可以看到版本号+1了。
注: ElasticSearch执行删除操作时,ES先标记文档为
deleted状态,而不是直接物理删除。当ES存储空间不足或工作空闲时,才会执行物理删除操作。
ElasticSearch执行修改操作时,ES不会真的修改Document中的数据,而是标记ES中原有的文档为deleted状态,再创建一个新的文档来存储数据。
查询太多内容,另起一节。
2.3 文档查询
所有的查询操作都是使用GET命令。
搜索前我们准备一些示例数据
{
"id":1001,
"name":"邓紫棋",
"description":"一位创作型歌手,是一个天才美女。",
"hobby":["唱歌","创作"]
},
{
"id":1002,
"name":"蔡徐坤",
"description":"一个穿背带裤的两年半练习生,是一个人气艺人。",
"hobby":["唱","跳","rap","篮球"]
},
{
"id":1003,
"name":"小黑子",
"description":"自诩是ikun,是一类自称是蔡徐坤粉丝的群体,包括俊男美女。",
"hobby":["香精煎鱼","香翅捞饭","油饼","荔枝","美食","卤醋鸡脚"]
},
{
"id":1004,
"name":"Gloria",
"description":"是邓紫棋在新专辑《启示录》MV中的虚拟人物,同时也是邓紫棋爸爸给她取得英文名字。",
"hobby":["未知"]
}
2.3.1 简单搜索
查询所有
match_all:查询所有数据
GET /索引名/_search
{
"query": {
"match_all": {}
}
}

分词检索
match:全文检索。将查询条件分词后再进行搜索。
GET /索引名/_search
{
"query": {
"match": {
"FIELD": "TEXT"
}
}
}

“一美女”分词后可分为“一”、“美女”,可以看到匹配了两条数据,max_score显示最大的_score,_score 体现匹配程度。
短语检索
match_phrase:短语检索。搜索条件不做任何分词解析,在搜索字段对应的倒排索引中精确匹配。
GET /索引名/_search
{
"query": {
"match_phrase": {
"FIELD": "PHRASE"
}
}
}
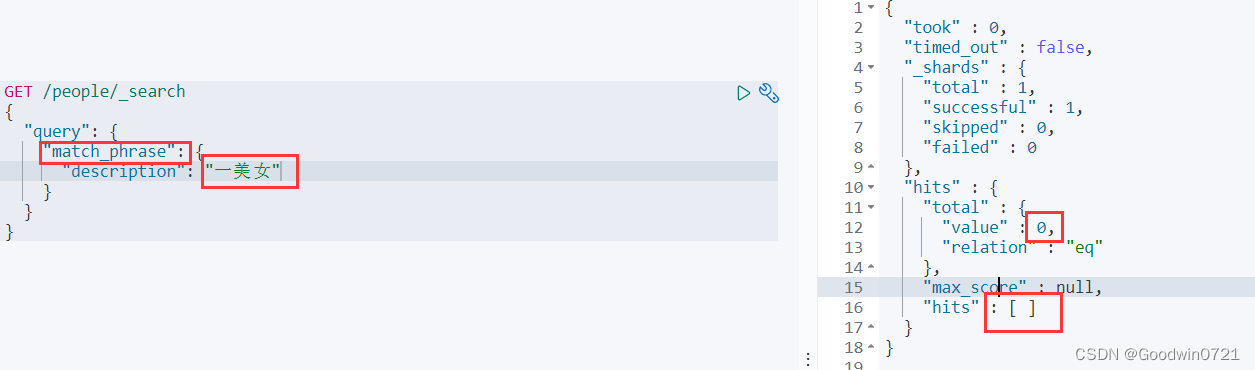
“一美女”不分词,自然是匹配不到合适的。
范围搜索
range:范围搜索。对数字类型的字段进行范围搜索
GET /索引名/_search
{
"query": {
"range": {
"FIELD": {
"gt/gte": 最小值,
"lt/lte": 最大值
}
}
}
}
gt/lt:大于/小于
gte/lte:大于等于/小于等于

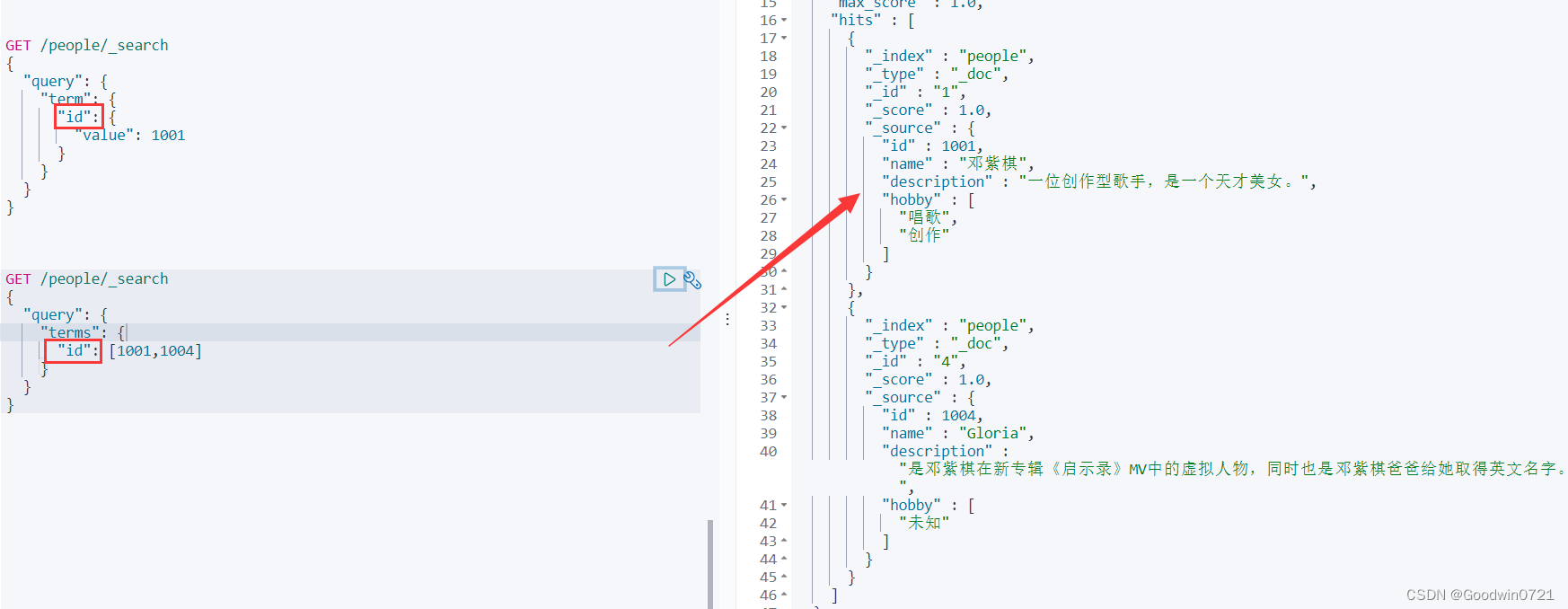
单词/词组搜索(精确查询)
term/terms:搜索条件不做任何分词解析,在搜索字段对应的倒排索引中精确匹配
term直接通过 倒排索引 指定词条查询- 适合查询
number、date、keyword,不适合text
text和keyword
text:
- 支持分词,全文检索、支持模糊、精确查询,不支持聚合,排序操作;
- text类型的最大支持的字符长度无限制,适合大字段存储;
keyword:
- 不进行分词,直接索引、支持模糊、支持精确匹配,支持聚合、排序操作。
keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
GET /索引名/_search
{
"query": {
"term": {
"FIELD": {
"value": "VALUE"
}
}
}
}
GET /索引名/_search
{
"query": {
"terms": {
"FIELD": [
"VALUE1",
"VALUE2"
]
}
}
}
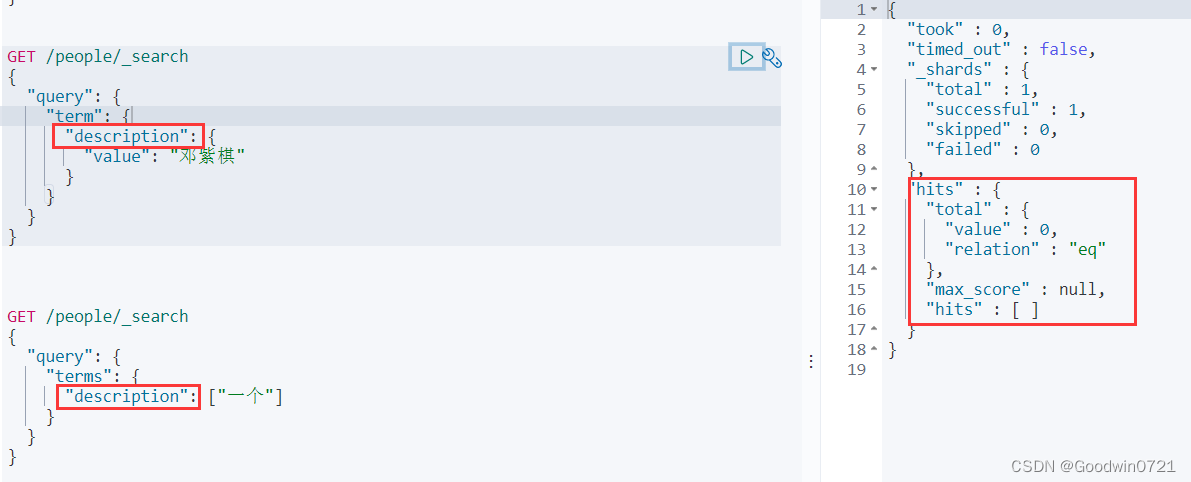
我们的description是text类型,查询不到内容,但id是integer类型,可以查到
其他查询方式
上面我们把查询条件写在{}内,另外可以写成一行
例如:GET /people/_doc/_search?q=name:Gloria
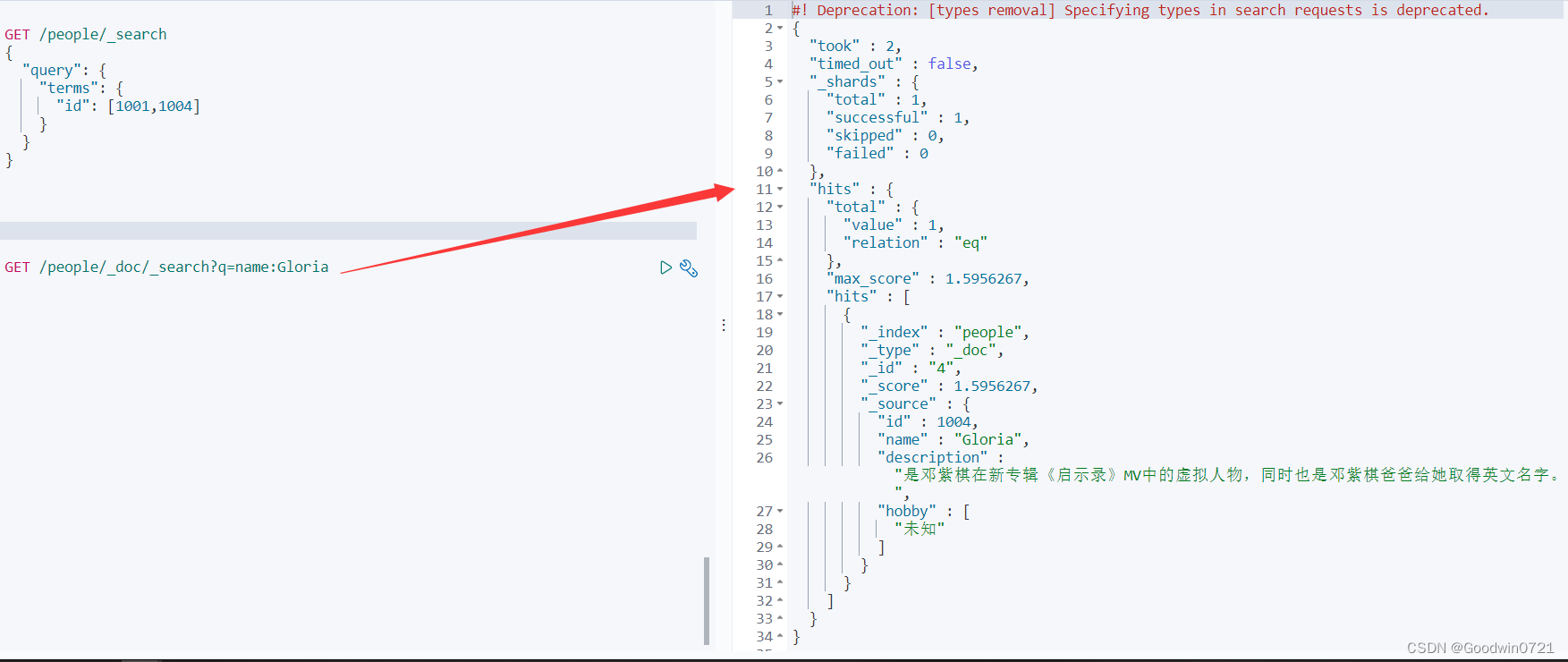
2.3.2 复杂搜索
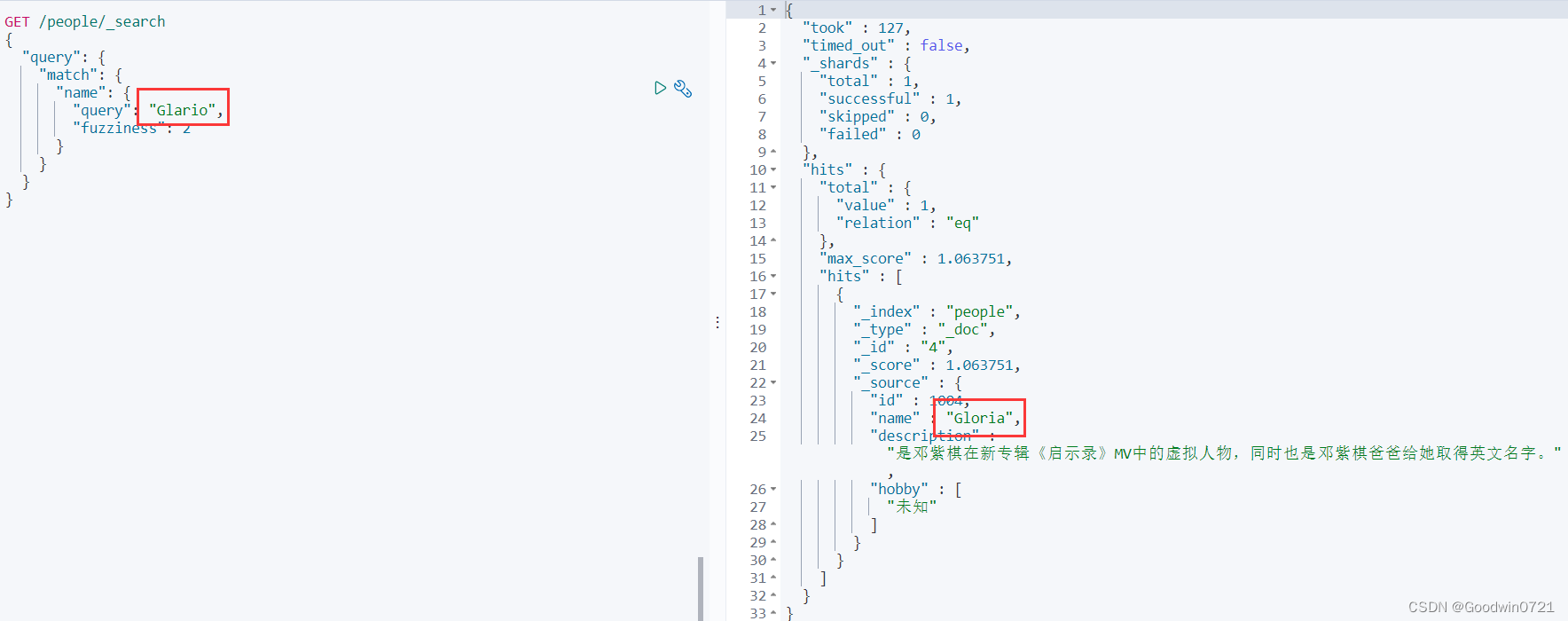
模糊搜索
match:匹配(会使用分词器解析(先分析文档,然后进行查询))
在搜索时关键词有可能会输入错误,ES搜索提供了自动纠错功能,即ES的模糊查询。使用match方式可以实现模糊查询。模糊查询对中文的支持效果一般,我们使用英文数据测试模糊查询。
GET /索引名/_search
{
"query": {
"match": {
"FIELD": {
"query": 搜索条件,
"fuzziness": 最多错误字符数,不能超过2
}
}
}
}
可以看到我们搜的是Glario,在容错范围内,能搜到Gloria。
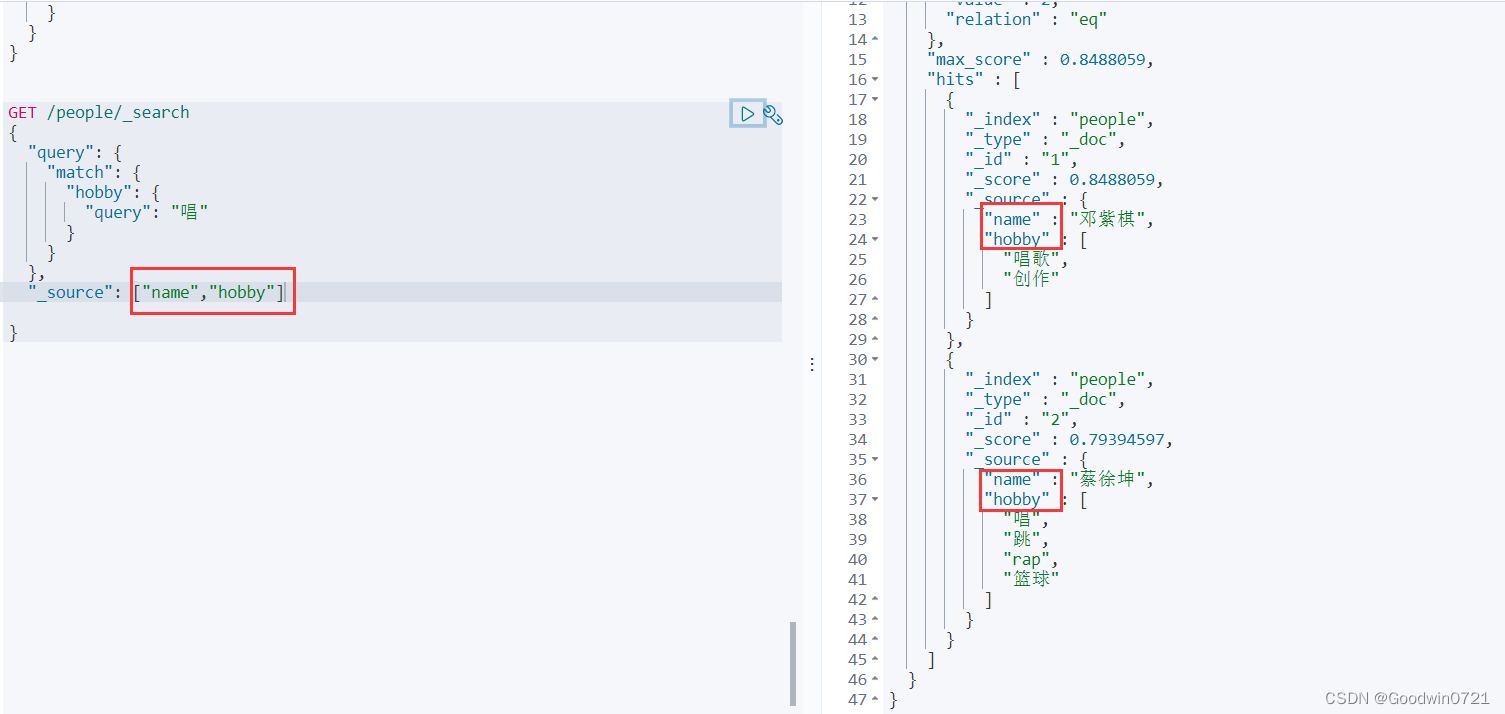
过滤其他字段
- 使用
source过滤其他字段,展示需要的部分
GET /index/_search
{
"query": {
……
},
"_source": "{field}"
}
结果排序
ES中默认使用相关度分数_score实现排序,可以通过搜索语法定制化排序。
GET /people/_search
{
"query": {
……
},
"sort": [
{
"FIELD": {
"order": "desc"/"asc"
}
}
]
}

当我们使用排序后,搜索结果的 "_score" : null。
多条件查询(bool)
must相当于andshould相当于ormust_not相当于not (... and ...)filter过滤
must
以下匹配'description'包含“美女”and 'hobby'包含“唱歌”,以下类似。

should
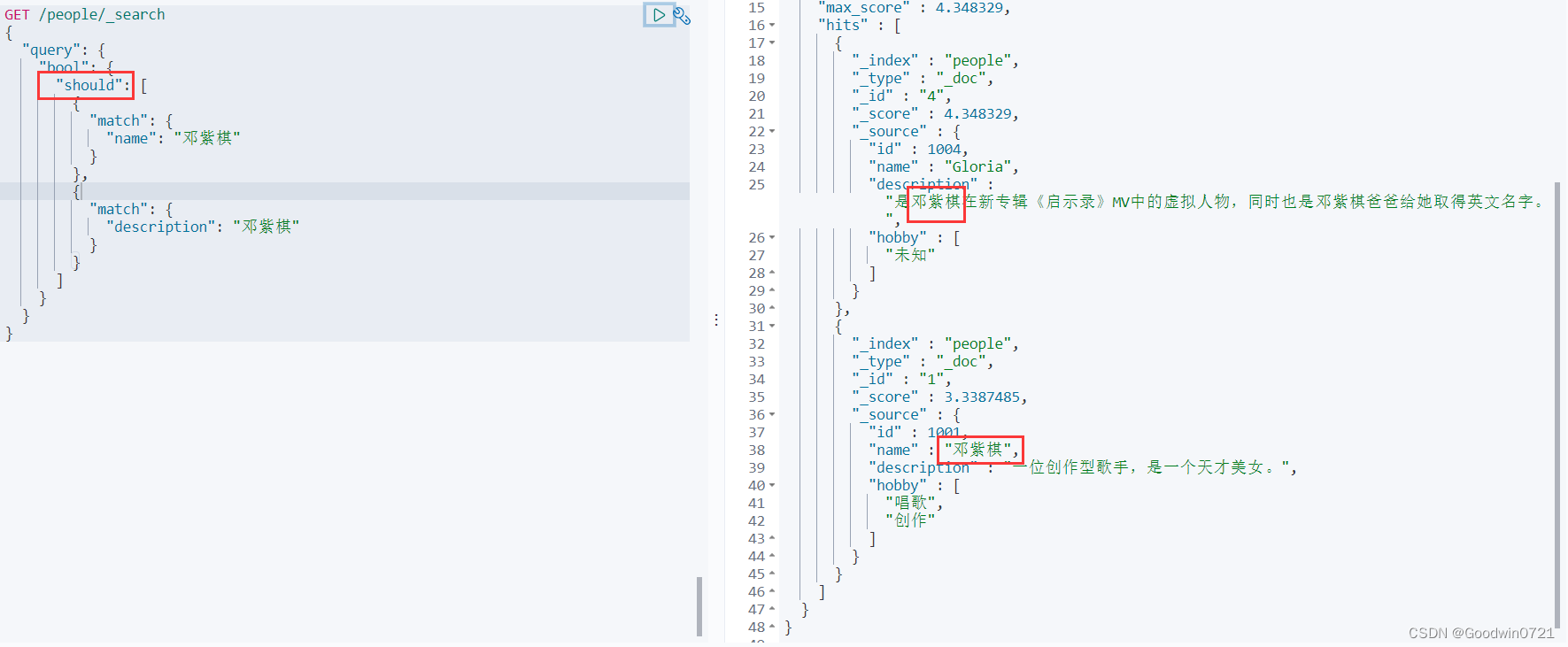
must_not
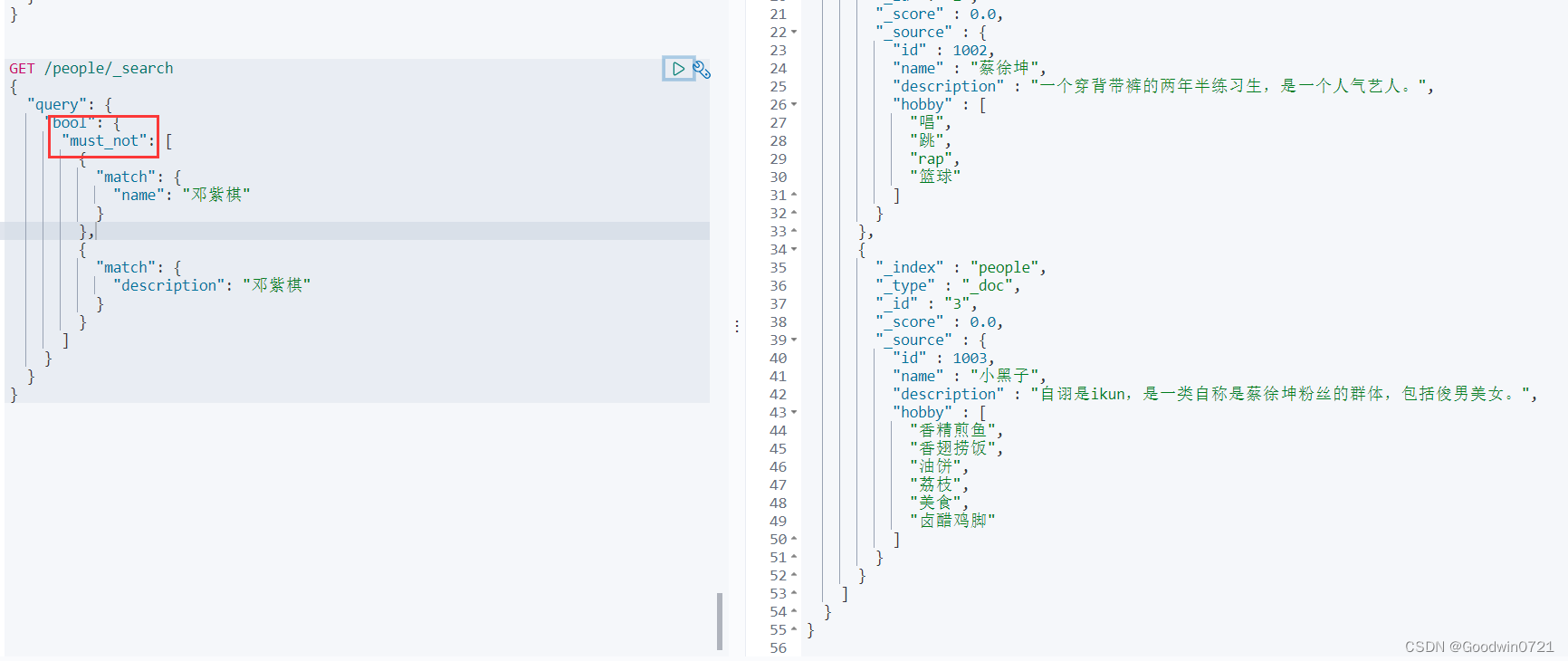
filter
注意,不是过滤掉
filter体内的,从结果来看,是留下符合filter规则的

分页查询
form、size 分页
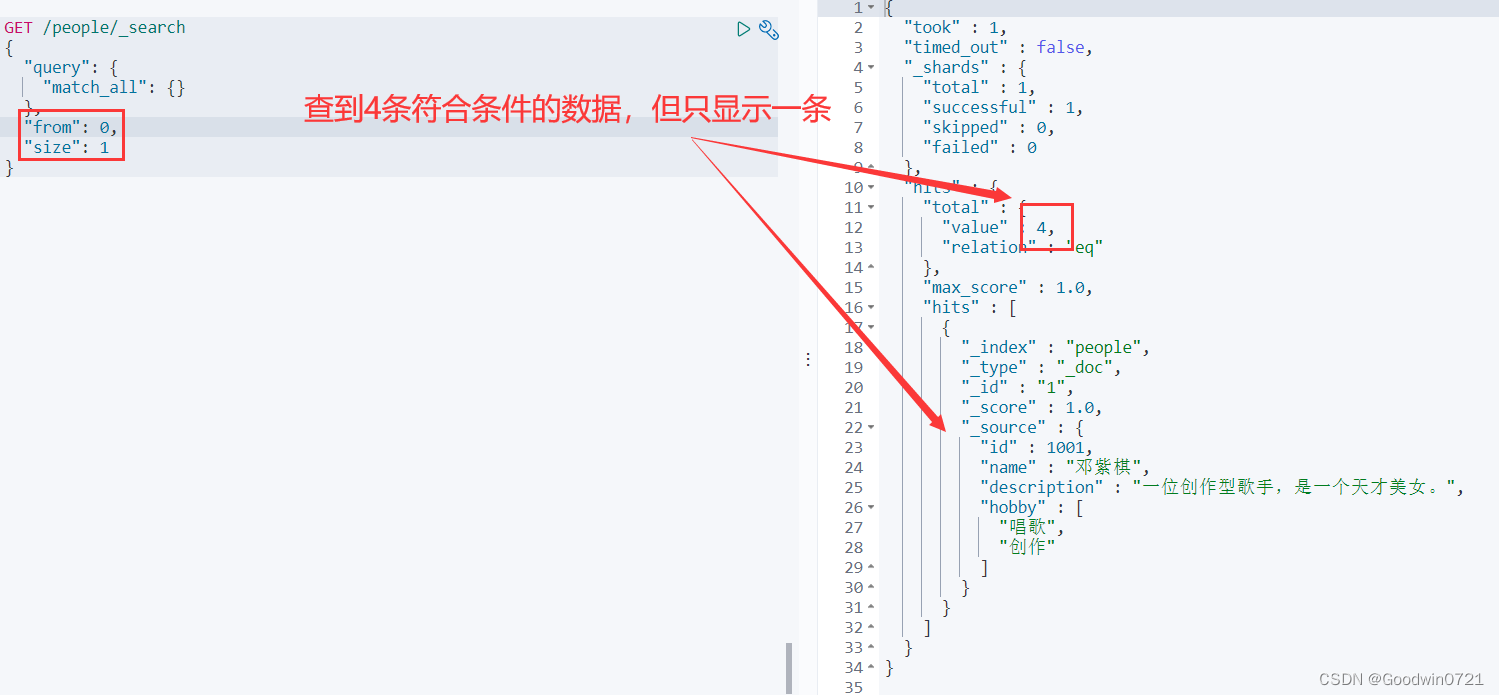
高亮查询
在进行关键字搜索时,搜索出的内容中的关键字会显示不同的颜色,称之为高亮。如:

我们通过开发者工具查看网页源码,可以看到源码中给这些高亮的关键字加了标签

我们可以在关键字左右加入标签字符串,数据传入前端即可完成高亮显示,ES可以对查询出的内容中关键字部分进行标签和样式的设置。
GET /索引名/_search
{
"query": {
……
},
#高亮
"highlight": {
#前缀
"pre_tags": {},
#后缀
"post_tags": {},
"高亮显示的字段名": {
// 返回高亮数据的最大长度
"fragment_size":100,
// 返回结果最多可以包含几段不连续的文字
"number_of_fragments":5
}
}

SQL查询
在ES7之后,支持SQL语句查询文档:
GET /_sql?format=txt
{
"query": SQL语句
}

开源版本的ES并不支持通过Java操作SQL进行查询,如果需要操作 SQL查询,则需要氪金(购买白金版)
3、 预告
今天是中秋节,祝我中秋节快乐。这篇就写到这了。下一篇,把ES整合到springboot中去。拜拜















 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









