







开始学习《ClickHouse原理解析与应用实践》,写博客作读书笔记。
本文全部内容都来自于书中内容,个人提炼。

第9章:
第10章 副本与分片
10.1 概述
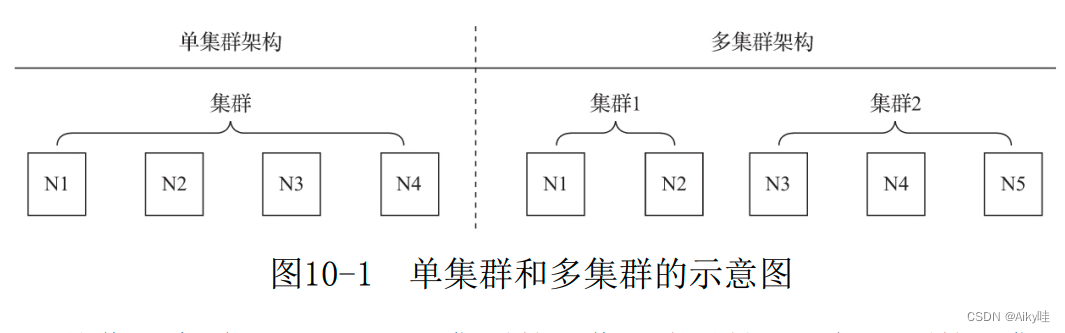
ClickHouse的集群配置非常灵活,用户既可以将所有节点组成一个单一集群,也可以按照业务的诉求,把节点划分为多个小的集群。
在每个小的集群区域之间,它们的节点、分区和副本数量可以各不相同 。
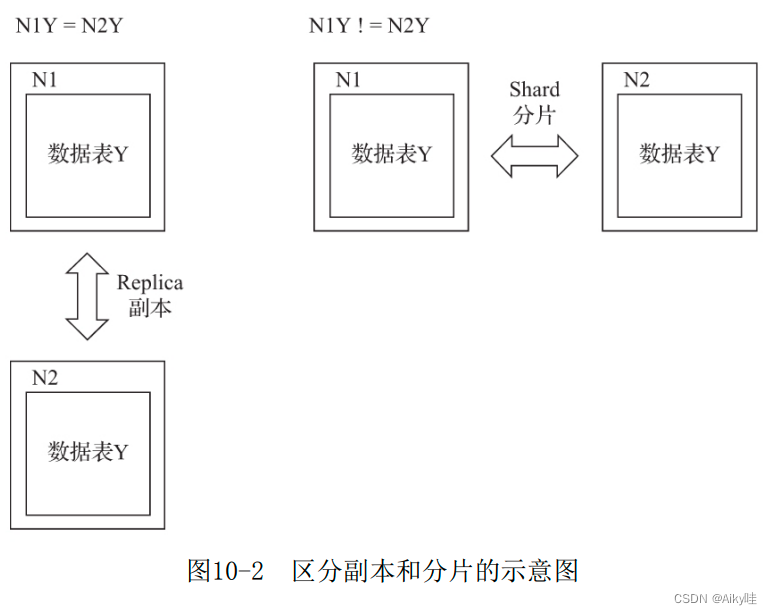
分片之间的数据是不同的,而副本之间的数据是完全相同的。
使用副本的主要目的是防止数据丢失,增加数据存储的冗余;而使用分片的主要目的是实现数据的水平切分。
10.2 数据副本
在MergeTree中,一个数据分区由开始创建到全部完成,会历经两类存储区域。
- 内存:数据首先会被写入内存缓冲区。
- 本地磁盘:数据接着会被写入tmp临时目录分区,待全部完成后再将临时目录重命名为正式分区。
ReplicatedMergeTree在上述基础之上增加了ZooKeeper的部分, 它会进一步在ZooKeeper内创建一系列的监听节点,并以此实现多个实例之间的通信。
在整个通信过程中,ZooKeeper并不会涉及表数据的传输。
10.2.1 副本的特点
- 依赖ZooKeeper:在执行INSERT和ALTER查询的时候, ReplicatedMergeTree需要借助ZooKeeper的分布式协同能力,以实现多个副本之间的同步。但是在查询副本的时候,并不需要使用 ZooKeeper。
- 多主架构(Multi Master):可以在任意一个副本上执行 INSERT和ALTER查询,它们的效果是相同的。这些操作会借助 ZooKeeper的协同能力被分发至每个副本以本地形式执行。
- Block数据块:在执行INSERT命令写入数据时,会依据 max_insert_block_size的大小(默认1048576行)将数据切分成若干个Block数据块。所以Block数据块是数据写入的基本单元,并且具有写入的原子性和唯一性。
- 原子性即:在数据写入时,一个Block块内的数据要么全部写入成功,要么全部失败。
- 唯一性即:在写入一个Block数据块的时候,会按照当前Block数据块的数据顺序、数据行和数据大小等指标,计算Hash信息摘要并记录在案。之后,如果某个待写入的Block数据块与先前已被写入的 Block数据块拥有相同的Hash摘要(Block数据块内数据顺序、数据大小和数据行均相同),则该Block数据块会被忽略。这项设计可以预防 由异常原因引起的Block数据块重复写入的问题。
10.2.2 ZooKeeper的配置方式
各个副本所使用的Zookeeper配置通常是相同的,为了便于在多个节点之间复制配置文件,更常见的做法是将这一 部分配置抽离出来,独立使用一个文件保存。
在服务器的/etc/clickhouse-server/config.d目录下创建一个 名为metrika.xml的配置文件:
<?xml version="1.0"?>
<yandex>
<zookeeper-servers> <!—ZooKeeper配置,名称自定义 -->
<node index="1"> <!—节点配置,可以配置多个地址-->
<host>hdp1.nauu.com</host>
<port>2181</port>
</node>
</zookeeper-servers>
</yandex>
在全局配置config.xml中使用<include_from>标签导入刚才定义的配置:
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
并引用ZooKeeper配置的定义:
<zookeeper incl="zookeeper-servers" optional="false" />ClickHouse提供了一张名为zookeeper的 代理表。通过这张表,可以使用SQL查询的方式读取远端ZooKeeper内的数据。
查询的SQL语句中,必须指定path条件:
SELECT * FROM system.zookeeper where path = '/'
┌─name───────┬─value─┬──────czxid─┬──────mzxid─┬───────────────ctime─┬───────────────mtime─┬─version─┬─cversion─┬─aversion─┬─ephemeralOwner─┬─dataLength─┬─numChildren─┬──────pzxid─┬─path─┐
│ zookeeper │ │ 0 │ 0 │ 1970-01-01 08:00:00 │ 1970-01-01 08:00:00 │ 0 │ -2 │ 0 │ 0 │ 0 │ 2 │ 0 │ / │
│ clickhouse │ │ 4294967299 │ 4294967299 │ 2022-06-20 10:52:21 │ 2022-06-20 10:52:21 │ 0 │ 1 │ 0 │ 0 │ 0 │ 1 │ 4294967301 │ / │
└────────────┴───────┴────────────┴────────────┴─────────────────────┴─────────────────────┴─────────┴──────────┴──────────┴────────────────┴────────────┴─────────────┴────────────┴──────┘
SELECT * FROM system.zookeeper where path = '/clickhouse';
┌─name───────┬─value─┬──────czxid─┬──────mzxid─┬───────────────ctime─┬───────────────mtime─┬─version─┬─cversion─┬─aversion─┬─ephemeralOwner─┬─dataLength─┬─numChildren─┬──────pzxid─┬─path────────┐
│ task_queue │ │ 4294967301 │ 4294967301 │ 2022-06-20 10:52:21 │ 2022-06-20 10:52:21 │ 0 │ 1 │ 0 │ 0 │ 0 │ 1 │ 4294967303 │ /clickhouse │
└────────────┴───────┴────────────┴────────────┴─────────────────────┴─────────────────────┴─────────┴──────────┴──────────┴────────────────┴────────────┴─────────────┴────────────┴─────────────┘10.2.3 副本的定义形式
使用副本增加了数据的冗余存储,所以降低了数据丢失的风险。
每个副本实例都可以作为数据读、写的入口,这无疑分摊了节点的负载。
ReplicatedMergeTree的定义方式如下:
ENGINE = ReplicatedMergeTree('zk_path', 'replica_name')zk_path用于指定在ZooKeeper中创建的数据表的路径,路径名称是自定义的,并没有固定规则,用户可以设置成自己希望的任何路径。
ck提供的配置模板:/clickhouse/tables/{shard}/table_name
- /clickhouse/tables/是约定俗成的路径固定前缀,表示存放数据表的根路径。
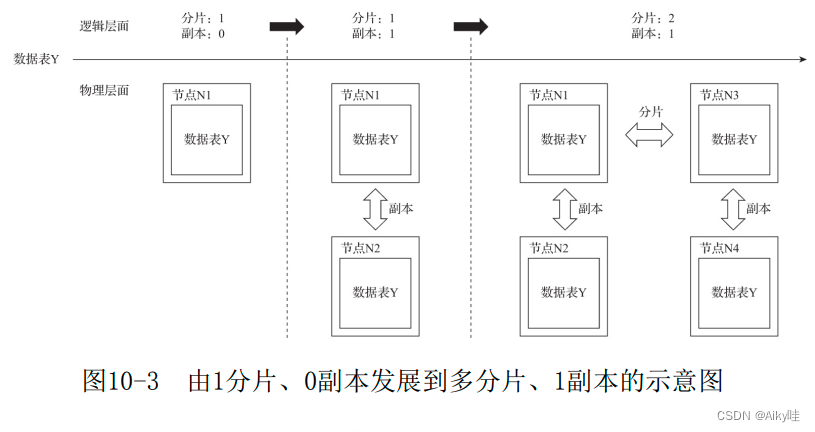
- {shard}表示分片编号,通常用数值替代,例如01、02、03。一 张数据表可以有多个分片,而每个分片都拥有自己的副本。
- table_name表示数据表的名称,为了方便维护,通常与物理表的名字相同(虽然ClickHouse并不强制要求路径中的表名称和物理表名相同);而replica_name的作用是定义在ZooKeeper中创建的副本名称,该名称是区分不同副本实例的唯一标识。一种约定成俗的命名方式是使用所在服务器的域名称。
//1分片,1副本的情形:
// zk_path相同,replica_name不同
ReplicatedMergeTree('/clickhouse/tables/01/test_1, 'ch5.nauu.com')
ReplicatedMergeTree('/clickhouse/tables/01/test_1, 'ch6.nauu.com')
// 多个分片、1个副本的情形:
// 分片1
// 2分片,1副本. zk_path相同,其中{shard}=01, replica_name不同
ReplicatedMergeTree('/clickhouse/tables/01/test_1, 'ch5.nauu.com')
ReplicatedMergeTree('/clickhouse/tables/01/test_1, 'ch6.nauu.com')
// 分片2
// 2分片,1副本. zk_path相同,其中{shard}=02, replica_name不同
ReplicatedMergeTree('/clickhouse/tables/02/test_1, 'ch7.nauu.com')
ReplicatedMergeTree('/clickhouse/tables/02/test_1, 'ch8.nauu.com')10.3 ReplicatedMergeTree原理解析
10.3.1 数据结构
核心逻辑中,大量运用了ZooKeeper的能力,以实现多个ReplicatedMergeTree副本实例之间的协同,包括主副本选举、副本状态感知、操作日志分发、任务队列和BlockID去重判断等。
执行INSERT数据写入、MERGE分区和MUTATION操作的时候,都会涉及与ZooKeeper的通信。
通信的过程中,并不会涉及任何表数据的传输,在查询数据的时候也不会访问ZooKeeper。
从zookeeper数据结构开始介绍。
1.ZooKeeper内的节点结构
在每张ReplicatedMergeTree表的创建过程中,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











