










从CornerNet到CornerNet-Lite再到训练自己的数据
- 相关论文与代码
- 相关工作
- CornerNet
- CornerNet-Lite
- 训练自己的数据
一.论文
- 论文CornerNet: Detecting Objects as Paired Keypoints
- 论文链接:https://arxiv.org/abs/1808.01244
- 代码链接:https://github.com/umich-vl/CornerNet
- 论文CornerNet-Lite: Efficient Keypoint Based Object Detection
- 论文链接:https://arxiv.org/abs/1904.08900
- 代码链接:https://github.com/princeton-vl/CornerNet-Lite
二. 相关工作
Anchor free的目标检测的论文,作者提出了一种新的用于目标检测的方法,通过预测一对关键点(左上角和右下角点)来预测目标的bounding box,代替之前主流的anchor boxes方法。文章从Backbone网络到pooling layer再到损失函数都进行了精心的设计。在MS COCO数据集上实现了42.2% AP at 1147ms。
从Faster-RCNN开始,使用RPN来代替Selective Search可以说是真正意义上把物体检测整个流程融入到一个神经网络中。根据一定的比例和尺寸RPN层可以形成众多的anchor,我们需要多这些anchor进行NMS等处理得到一些候选框,然后对这些候选框进行分类和回归,如果是双阶段的还还需要第二阶段分类回归的微调。生成的众多候选框对模型算法带来了众多的弊端:
1.anchor boxes数量巨大,但是多数情况下ground truth标注图像的大小通常只占据图像的较小的比例,仅通过IOU阈值上下限,NMS等处理后负样本会严重多于正样本。正负样本不平衡会严重影响算法的精度,当然通常的解决办法有OHEM和focal loss.
2.对众多的anchor进行后处理在时间上的花费也是庞大的,这会严重的降低算法的训练和预测速度。
3.anchor调参的设置影响模型的精度,比如说Faster-RCNN中每个锚点会映射出9个框,映射条件为1:1,1:2,2:1的比例,128,256,512的尺寸。针对不同的任务,这个比例和尺寸是需要人工调参来调整以达到最优结果。
三. CornerNet
CornerNet放弃使用anchor box方法,使用一个简单的卷积网络来预测同一对象类别的所有实例的左上角和右下角的heatmap,以及每个检测到的角的embedding vector(嵌入向量)。embedding vector用来将同一个对象的两个角组成一对,下图展示了整个流程:
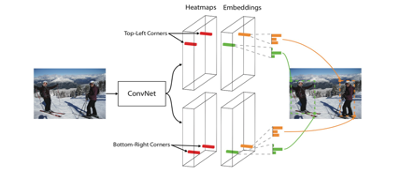
1.Backbone
图像进入神经网络后首先会经过一个Backbone也就是图像的ConvNet,论文选用了Hourglass。该网络通过串联多个hourglass module组成,每个hourglass module都是先通过一系列的降采样操作缩小输入的大小,然后通过上采样恢复到输入图像大小,因此该部分的输出特征图大小还是128×128,整个hourglass network的深度是104层。

相比原始的Hourglass文章做了以下改进:
1. max-pooling → 卷积 stride=2进行下采样
2. 在每个skip connection,有两个residual modules
3. 进入Hourglass前,进行了2次下采样。使用一个kernel size=7*7,stride=2,channel=128的卷积和一个stride=2,channel=256的residual block,将width和height缩小为以前的1/4
hourglass module后会有两个输出分支模块,分别表示左上角点预测分支和右下角点预测分支,每个分支模块包含一个corner pooling层和3个输出:heatmaps、embeddings和offsets。下面是左上角算法分支流程图:

Corner Pooling:
对图中红色点(坐标假设是(i,j))做corner pooling,那么就计算(i,j)到(i,H)的最大值(下图中间图);同时计算(i,j)到(W,j)的最大值(下图中间图)。然后将这两个最大值相加得到(i,j)点的值(下图中的蓝色点)。右下角点的corner pooling操作类似,只不过计算最大值变成从(0,j)到(i,j)和从(i,0)到(i,j)。

下图是Corner Pooling的一个例子,文章作者认为这样可以模仿人的眼睛搜索目标的过程,代码使用DP的形式实现。滑动比较的过程中保留当时的最大值,最后进行进行数值的相加得到右图的数值。

损失函数:
Heatmaps: detecting corners
![]()
Headmaps是角点预测的损失函数,pcij表示预测的heatmaps在第c个通道(类别c)的(i,j)位置的值,ycij表示对应位置的ground truth,N表示目标的数量。ycij=1时候的损失函数容易理解,就是focal loss,α参数用来控制难易分类样本的损失权重;ycij等于其他值时表示(i,j)点不是类别c的目标角点,照理说此时ycij应该是0(focal loss是这样处理的),但是这里ycij不是0,而是用基于ground truth角点的高斯分布计算得到,因此距离ground truth比较近的(i,j)点的ycij值接近1,这部分通过β参数控制权重。因为靠近ground truth的误检角点组成的预测框仍会和ground truth有较大的重叠面积,所以负样本点用不同权重的损失函数。
![]()
其中(x,y)表示negative location(i,j)与 gt corner location(圆中心)的坐标相对值,r是圆的半径,这个值控制惩罚降低的变化速度,值越大,随着negative location远离圆中心,值下降的越慢(高斯函数曲线越扁平)经过这个修改后,ycij=1依然表示positive,而ycij<1表示negative.
Grouping Corners: grouping corners
两组heatmaps中将会分别预测出很多左上角corners和右下角corners,作者使用embedding方法,为每个corner生成embedding vector,分别预测出很多左上角corners和右下角corners.etk表示属于k类目标的左上角角点的embedding vector,ebk表示属于k类目标的右下角角点的embedding vector,ek表示etk和ebk的均值。

从两个损失的命名可见,Lpull是为了将同一目标的etk,ebk两个embedding拉的更近,同一目标的两个embedding越接近,pull损失越小。使用这个损失学习,更偏向于将同一目标的两个embedding生成的更接近。Lpush则使不同目标的均值embedding尽可能互相“推开”,因为一个目标本身就有左上corner和右下corner的两个embedding,所以push中取etk和ebk的均值ek,互相推开的程度由∆来量化,当两个不同目标的均值embedding的差的L1范数超过∆时,我们认为可以足够区分corner是来自不同的目标,这里∆=1 。
Offsets: correcting corners’position:
从输入图像到特征图之间会有尺寸缩小,假设缩小倍数是n,那么输入图像上的(x,y)点对应到特征图上相应的值取整会带来精度丢失,这尤其影响小尺寸目标的回归,Faster RCNN中的 ROI Pooling也是有类似的精度丢失问题,Mask RCNN中使用ROI align进行了优化。这是解决精度丢失的常见思路。这个值和目标检测算法中预测的offset类似却完全不一样,说类似是因为都是偏置信息,说不一样是因为在目标检测算法中预测的offset是表示预测框和anchor之间的偏置,而这里的offset是表示在取整计算时丢失的精度信息。
![]()

Sum loss:
![]()
α, β, γ是超参数,分别取0.1, 0.1, 1。
模型预测:
- 测试图像采用0值填充方式得到指定大小作为网络的输入,而不是采用resize。输入尺寸511*511
- 在得到预测角点后,会对这些角点做NMS操作,选择前100个左上角角点和100个右下角角点。
- 计算左上角和右下角角点的embedding vector的距离时采用L1范数,距离大于0.5或者两个点来自不同类别的目标的都不能构成一对
- 最后通过soft-nms操作去除冗余框,只保留前100个预测框。
四.CornerNet-Lite
CornerNet-Lite是CornerNet的两种有效变体的组合:CornerNet-Saccade和CornerNet-Squeeze,前者使用注意机制(attention)消除了对图像的所有像素进行处理的需要,将cornernet单阶段检测器变为两阶段检测器,attention maps作用类似与fasterrcnn中的rpn但又有所不同,将roi区域crop下来进行第二阶段的精细检测,该网络与cornernet相比达到精度提升;后者引入新的紧凑骨干架构的CornerNet-Squeeze,主干网络实为hourglass network、mobilenet、squeezenet结构的变体,在实时检测器领域达到速度和精度的双重提升。
- CornerNet-Saccade
R-CNN系列论文中的saccades机制为single-type and single-object,也就是产生proposal的时候为单类型(前景类)单目标(每个proposal中仅含一个物体或没有),AutoFocus论文中的saccades机制为multi-type and mixed(产生多种类型的crop区域)
CornerNet-Saccade中的 saccades是single type and multi-object,也就是通过attention map找到合适大小的前景区域,然后crop出来作为下一阶段的精检图片。CornerNet-Saccade 检测图像中可能的目标位置周围的小区域内的目标。它使用缩小后的完整图像来预测注意力图和粗边界框;两者都提出可能的对象位置,然后,CornerNet-Saccade通过检查以高分辨率为中心的区域来检测目标。它还可以通过控制每个图像处理的较大目标位置数来提高效率。具体流程如下图figure2所示,主要分为两个阶段估计目标位置和检测目标:

- CornerNet-Squeeze
CornerNet-Saccade通过关注子区域的像素来减少处理量。CornerNet-Squeeze减少每个像素处理过程中的计算量。CornerNet中,计算量主要消耗在Hourglass-104上,其由包含两个3x3的卷积及一个跳跃连接的残差块组成。虽然Hourglass-104的性能好,但是,其参数量大,而且inference时间长。本文借鉴了SqueezeNet及MobileNet的思想来设计一个轻量级的Hourglass结构。
Ideas:SqueezeNet通过将3x3的卷积替换为1x1的卷积,减少3x3卷积的通道数,以及后续的下采样操作来减少网络的参数量。SqueezeNet中的building block及fire module包含前两个思想,Fire Module首先会通过包含一系列1x1卷积核来减少输入的通道数,然后,将结果送到包含1x1及3x3卷积核的扩张层中。
本文将CornerNet-Squeeze中的参差块替换为fire module。将其中第二层的3x3的标准卷积替换为深度可分离卷积。变换前后操作数量的对比如下。上述Squeeze的第三条特点,并未考虑,因为,hourglass为沙漏型对称结构。后续的下采样的结果会在上采样过程中得到更高的分辨率,而在高分辨率的feature map上进行卷积操作会占用大量的计算资源,不利于实时检测。本文通过在hourglass模型之前增加更多的下采样层,移除每个hourglass模型中的一个下采样层来进一步减少Hourglass 模型中的最大分辨率数。CornerNet-Squeeze在hourglass 模型之前减少3倍的尺寸,而CornerNet只减少两倍。将CornerNet预测模型中的3x3卷积替换为1x1的卷积。最后,将hourglass网络中最相邻的上采样层替换为4x4的转置卷积。
五. 训练自己的数据
- label标注自己的数据
- lableme转coco形
# -*- coding:utf-8 -*-
# !/usr/bin/env python
import argparse
import json
import matplotlib.pyplot as plt
import skimage.io as io
import cv2
from labelme import utils
import numpy as np
import glob
import PIL.Image
class labelme2coco(object):
def __init__(self,labelme_json=[],save_json_path='./new.json'):
'''
:param labelme_json: 所有labelme的json文件路径组成的列表
:param save_json_path: json保存位置
'''
self.labelme_json=labelme_json
self.save_json_path=save_json_path
self.images=[]
self.categories=[]
self.annotations=[]
# self.data_coco = {}
self.label=[]
self.annID=1
self.height=0
self.width=0
self.save_json()
def data_transfer(self):
for num,json_file in enumerate(self.labelme_json):
with open(json_file,'r') as fp:
data = json.load(fp) # 加载json文件
self.images.append(self.image(data,num))
for shapes in data['shapes']:
label=shapes['label'].split('_')
if label[1] not in self.label:
self.categories.append(self.categorie(label))
self.label.append(label[1])
points=shapes['points']
self.annotations.append(self.annotation(points,label,num))
self.annID+=1
def image(self,data,num):
image={}
height = data['imageHeight']# 解析原图片数据
width = data['imageWidth']
# img=io.imread(data['imagePath']) # 通过图片路径打开图片
# img = cv2.imread(data['imagePath'], 0)
# height, width = img.shape[:2]
img = None
image['height']=height
image['width'] = width
image['id']=num+1
image['file_name'] = data['imagePath'].split('/')[-1]
self.height=height
self.width=width
return image
def categorie(self,label):
categorie={}
categorie['supercategory'] = label[0]
categorie['id']=len(self.label)+1 # 0 默认为背景
categorie['name'] = label[1]
return categorie
def annotation(self,points,label,num):
annotation={}
annotation['segmentation']=[list(np.asarray(points).flatten())]
annotation['iscrowd'] = 0
annotation['image_id'] = num+1
# annotation['bbox'] = str(self.getbbox(points)) # 使用list保存json文件时报错(不知道为什么)
# list(map(int,a[1:-1].split(','))) a=annotation['bbox'] 使用该方式转成list
annotation['bbox'] = list(map(float,self.getbbox(points)))
annotation['category_id'] = self.getcatid(label)
annotation['id'] = self.annID
return annotation
def getcatid(self,label):
for categorie in self.categories:
if label[1]==categorie['name']:
return categorie['id']
return -1
def getbbox(self,points):
# img = np.zeros([self.height,self.width],np.uint8)
# cv2.polylines(img, [np.asarray(points)], True, 1, lineType=cv2.LINE_AA) # 画边界线
# cv2.fillPoly(img, [np.asarray(points)], 1) # 画多边形 内部像素值为1
polygons = points
mask = self.polygons_to_mask([self.height,self.width], polygons)
return self.mask2box(mask)
def mask2box(self, mask):
'''从mask反算出其边框
mask:[h,w] 0、1组成的图片
1对应对象,只需计算1对应的行列号(左上角行列号,右下角行列号,就可以算出其边框)
'''
# np.where(mask==1)
index = np.argwhere(mask == 1)
rows = index[:, 0]
clos = index[:, 1]
# 解析左上角行列号
left_top_r = np.min(rows) # y
left_top_c = np.min(clos) # x
# 解析右下角行列号
right_bottom_r = np.max(rows)
right_bottom_c = np.max(clos)
# return [(left_top_r,left_top_c),(right_bottom_r,right_bottom_c)]
# return [(left_top_c, left_top_r), (right_bottom_c, right_bottom_r)]
# return [left_top_c, left_top_r, right_bottom_c, right_bottom_r] # [x1,y1,x2,y2]
return [left_top_c, left_top_r, right_bottom_c-left_top_c, right_bottom_r-left_top_r] # [x1,y1,w,h] 对应COCO的bbox格式
def polygons_to_mask(self,img_shape, polygons):
mask = np.zeros(img_shape, dtype=np.uint8)
mask = PIL.Image.fromarray(mask)
xy = list(map(tuple, polygons))
PIL.ImageDraw.Draw(mask).polygon(xy=xy, outline=1, fill=1)
mask = np.array(mask, dtype=bool)
return mask
def data2coco(self):
data_coco={}
data_coco['images']=self.images
data_coco['categories']=self.categories
data_coco['annotations']=self.annotations
return data_coco
def save_json(self):
self.data_transfer()
self.data_coco = self.data2coco()
print(self.data_coco )
# 保存json文件
json.dump(self.data_coco, open(self.save_json_path, 'w'), ensure_ascii=False, indent=4,default=str) # indent=4 更加美观显示
labelme_json=glob.glob('detection_test_iamge/labels/*.json')
labelme2coco(labelme_json,'detection_test_iamge/mydata/annotations/train/new.json')- 修改配置文件
- core/dns/__init__
- 复制core/dns/coco.py 命名为mydata.py,修改加载数据路径以及分类数相关的代码
- 修改core/dns/detection.py 修改 self._configs["categories"] = 1,无背景类
修改CornerNet/config下的配置文件CornerNet.json("dataset","categories")
单gpu训练:
python train.py CornerNet_Saccade多gpu训练:
CUDA_VISIBLE_DEVICES =0,1,2,3 python train.py CornerNet_Saccade 预训练模型下载:
链接:https://pan.baidu.com/s/1IhQ3G-XtbAlp2TuJEVSXqw 密码: w2mp
在项目根目录下新建cache,将下载的nnet放进去即可
安装问题解决:
- 注意升级GCC
- 安装时遇到torch和torchvision不匹配问题,升级torchvision解决
- numpy要求高于1.16.0
- 问题:/lib64/libstdc++.so.6: version `GLIBCXX_3.4.20' not found,解决如下
- yum provides libstdc++.so.6
- yum install libstdc++-4.8.5-11.el7.i686
- cp /usr/local/lib64/libstdc++.so.6.0.20 /usr/lib64/libstdc++.so.6.0.20
- rm -f /usr/lib64/libstdc++.so.6
- ln -s /usr/lib64/libstdc++.so.6.0.20 /usr/lib64/libstdc++.so.6














 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









