







CornerNet-Lite论文笔记与代码复现
(一)Title

(二)背景知识:Conernet
1、Idea
当今的目标检测算法大多都是基于深度学习模型的,大致可以分为两大门派,一个叫做One-Stage系列,另一个叫做Two-Stage系列。
- Two-Stage系列顾名思义就是两步走:是先由算法生成一系列作为样本的候选框(Region Proposal),再通过卷积神经网络对候选框进行分类回归,典型代表有R-CNN系列;
- One-Stage系列则不用产生候选框,直接将目标边框定位的问题转化为回归问题处理,所以他叫一步走,典型的代表有YOLO系列、SSD系列。正是由于两种方法的差异,在性能上也有不同,前者在检测准确率上占优,后者在算法速度上占优。
上述所讲的两个门派中的一些算法,都用到了anchor这个概念,但是本文的作者认为使用anchor来做目标检测有缺点:anchor的数量太大,参数太多,也就是anchor的设置太讲究了,所以作者就发出了质问,难道一定要用anchor来做目标检测吗??这是作者的第一个思路来源。第二个思路来源是来自一篇姿态估计的文章,这篇文章是基于CNN的2D多人姿态估计方法,通常有2个思路:Top-Down framework:就是先进行行人检测,得到边界框,然后在每一个边界框中检测人体关键点,连接成每个人的姿态,代表算法RMPE(alphapose);Bottom-Up framework:就是先对整个图片进行每个人体关键点的检测,再将检测到的人体部位拼接成每个人的姿态,代表方法就是openpose。
作者基于以上的两个思路,就诞生了:CornerNet: Detecting Objects as Paired Keypoints,重在Keypoints,作者把目标检测问题当作关键点检测问题来解决,检测目标的两个关键点——左上角(Top-left)和右下角(Bottom-right),有了两个点之后,就能确定框了。
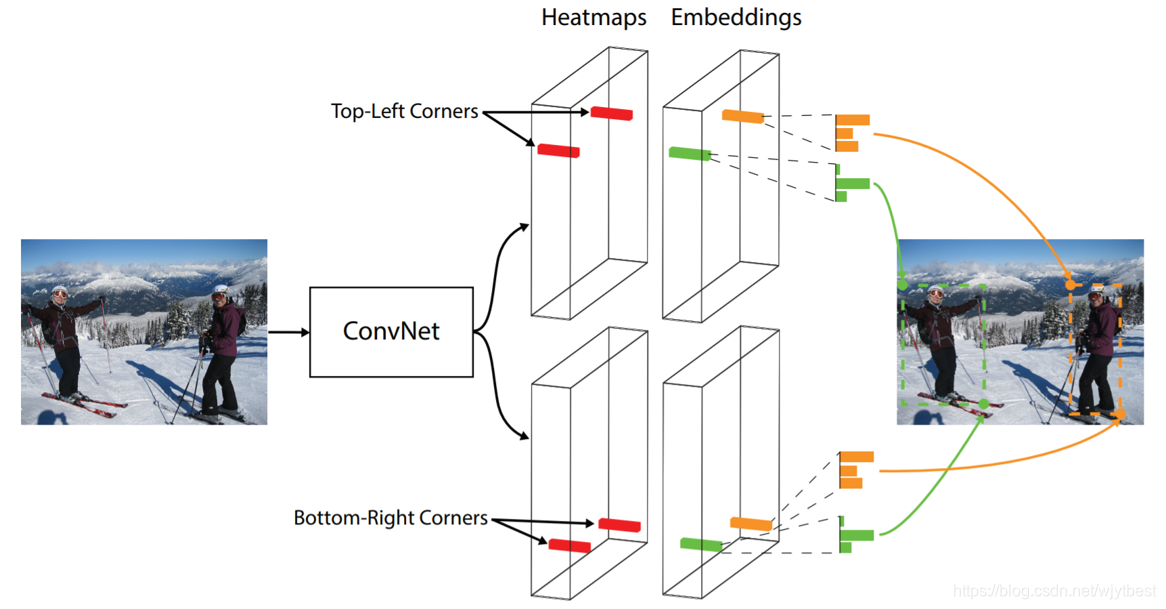
2、算法流程
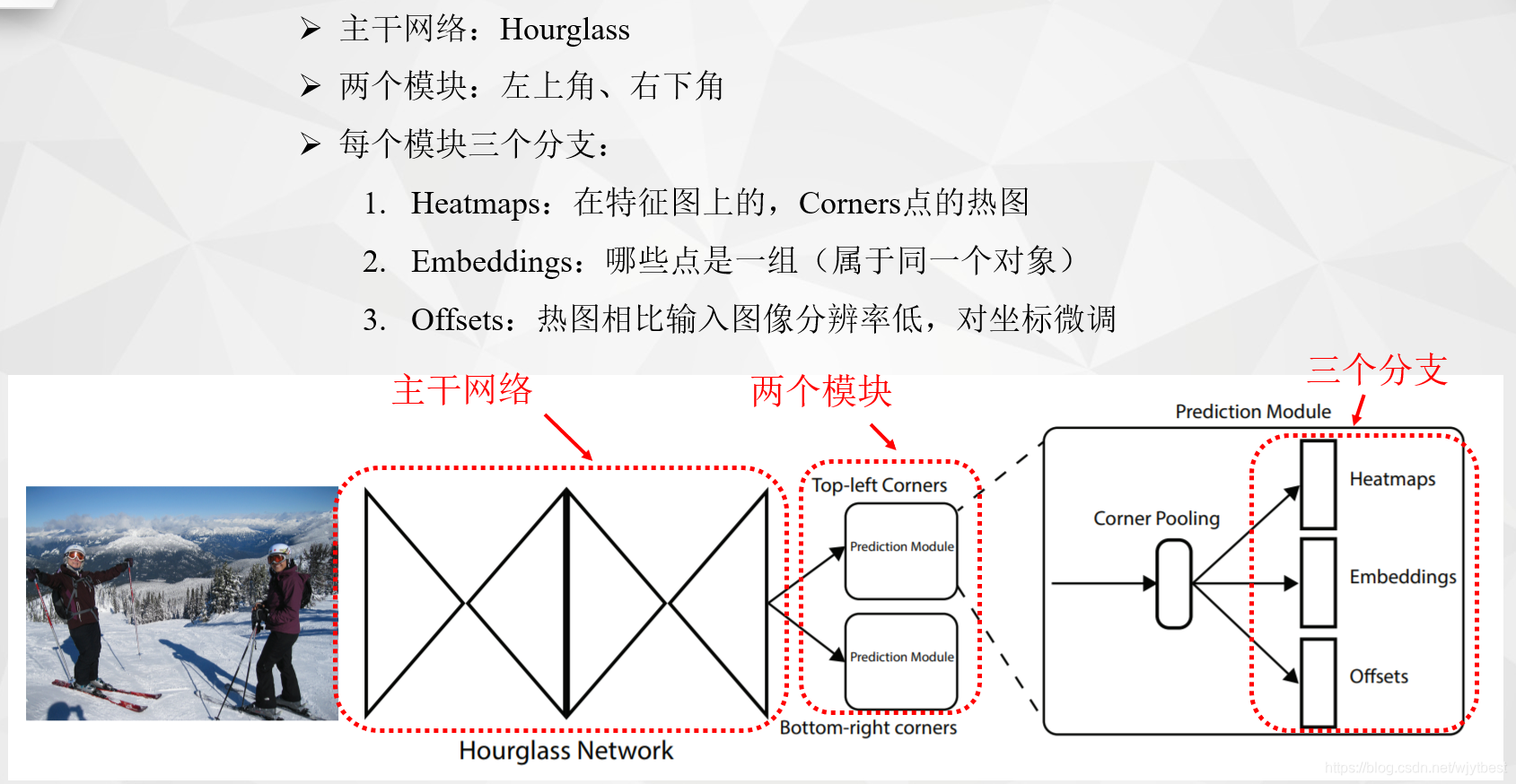
输入图片经过Hourglass主干网络后,得到特征图,然后将该特征图作为两个Prediction模块的输入,分别是Top-left corners和Bottom-right corners。在每个预测模块里面,先经过Corner Pooling,然后输出Heatmaps, Embeddings, Offsets三个分支。heatmaps预测哪些点最有可能是Corners点,embeddings的作用是分清哪些点是一组,最后的offsets用于对点的位置进行修正,因为原图到特征图分辨率已经降低了。
2.1 Backbone
Hourglass-104
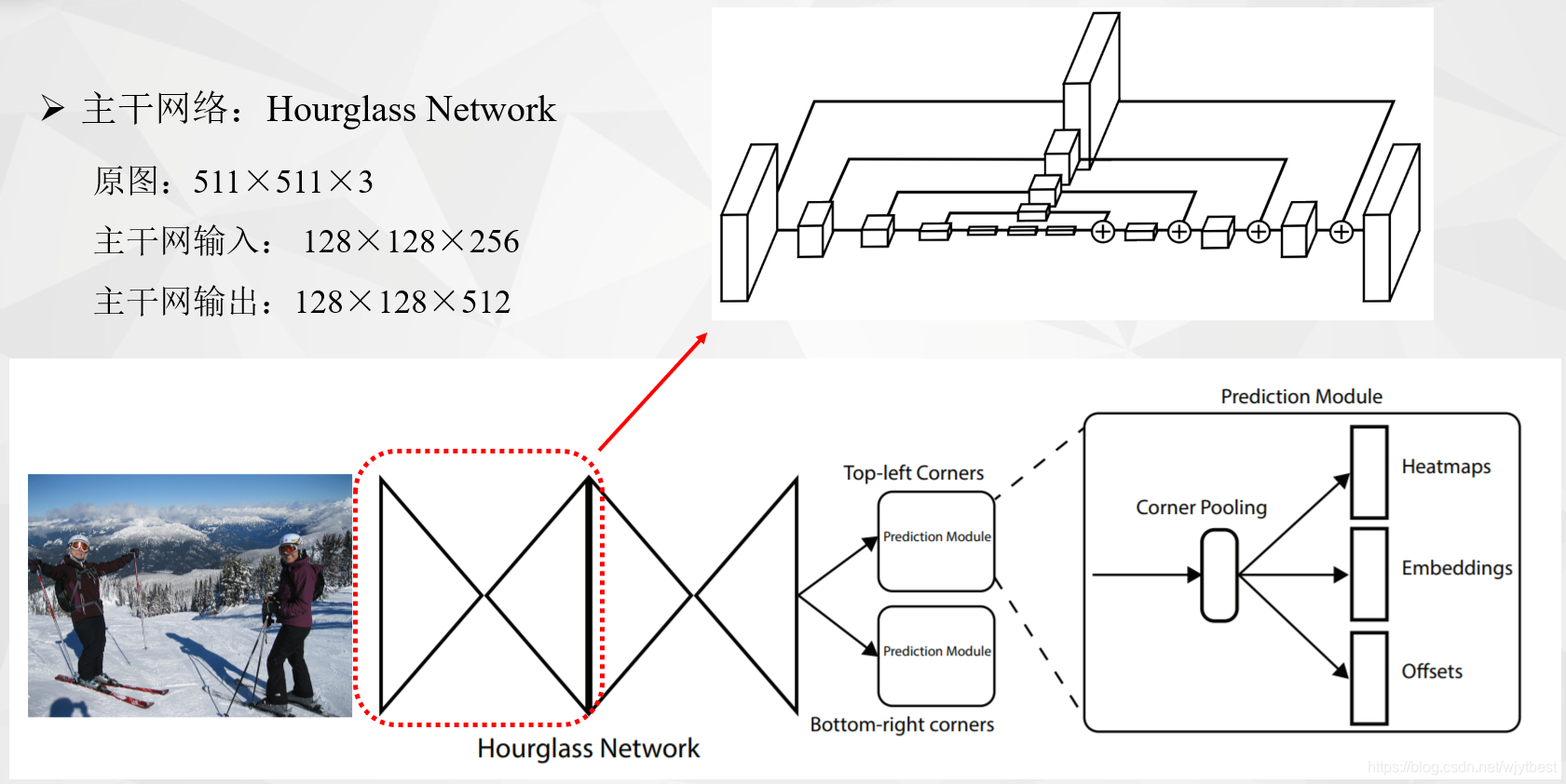
原始图片的大小为511×511×3,但这并不是主干网络的输入,主干网络的输入是128×128×256,为什么呢?因为作者是先将512的原图进行缩小四倍,缩小四倍用的操作是先用7×7的卷积核卷积,并且步长为2,通道数为128,这样就缩小两倍了,还有两倍是用了一个残差块,并且步长为2,通道数为256。所以,主干网络真正的的输入是128×128×256,主干网络的输出是128×128×512,为什么分辨率没有变化呢?因为这个主干网络叫做沙漏网络,样子像沙漏,他是先下采样后又上采样,连续堆叠了两个这样的沙漏,过程中经过了特征融合等等,这里总共用了104层。
主干网络出来后,面对的就是两个Module,一个用于预测左上角点,一个用于预测右下角点。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









