







 本文介绍了统计学的基础知识,包括描述性统计和推断性统计,通过销售数据案例展示了集中度、离散度和相关性的分析方法。此外,探讨了概率和概率分布,以及如何在数据分析中应用概率。最后,讲解了样本估计和假设检验,强调其在验证数据和商业决策中的重要性。
本文介绍了统计学的基础知识,包括描述性统计和推断性统计,通过销售数据案例展示了集中度、离散度和相关性的分析方法。此外,探讨了概率和概率分布,以及如何在数据分析中应用概率。最后,讲解了样本估计和假设检验,强调其在验证数据和商业决策中的重要性。
文章目录
【描述数据的统计学工具】
一、统计分为两大类
- 一个是分析数据集中度和分散度的描述性统计
- 一个是通过样本对总体情况作出推断的推断性统计
只有掌握了统计学基础,我们才能在统计学的基础上进行聚类、回归、分类、组间差异这四个常见的数据分析方法
二、数据案例引入
2.1销售数据
原始数据中上万条的记录都被保存着,一眼看上去是杂乱无章的数据
2.2销售额表现怎么样?
阐述解释数据的状况,这就是描述统计
2.3可视化
描述数据有两个关键的问题(描述性统计分析)
- 中心度:销售额集中在哪个区
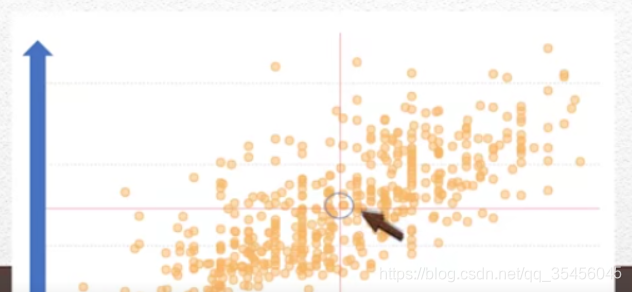
- 分散度:最小值和最大值之间的区间(左侧箭头)
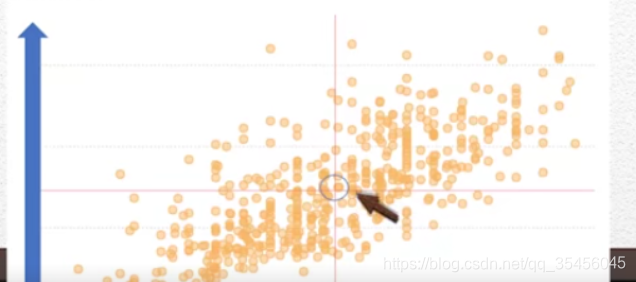
三、数据的集中度
包括以下三点:
- 均值,平均数,均件,最常用的衡量集中度的指标(误区:有非常大的或者非常小的销售额会拉高整体均值,因此需要同时提供中位数和众数)
- 中位数,将数据从小到大排列之后,处于最中间位置的那个数字
- 众数,数据中出现最频繁的那个数字,可能有很多众数,或者找不到众数
四、数据的离散度
包括以下四点:
- 全距,数据中最大值和最小值的差,是简单实用的指标
- 四分位数,对全距的改进,从小到大排序,均分为四等分,四分位数有三个,处在25%位置上的数值(Q1),处在50%位置上数值即中位数(Q2),和处在75%6位置上的数值(Q3),确定四分位数的位置公式
Q1的位置=(n+1) x 0.25
Q2的位置=(n+1) x 0.5
Q3的位置=(n+1) x 0.75 - 方差,更全面的反映离散度,偏离

- 标准差,方差的开方结果,越大,表示偏离越远
五、数据的相关性
5.1案例
数据有很多种类---------------->研究不同数据之间的关系
- 用户在app上的使用时间和他们购买产品金额大小之间的关系
- 用户个人资产大小以及他们申请贷款的金额等等
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









