







之前用java写过一个简单的爬取电影天堂信息的爬虫,后来发现用python写这种简单的爬虫程序更简单,异步网络框架在不使用多线程和多进程的情况下也能增加爬取的速度,目前刚开始学scrapy,用这个写了一个爬电影天堂的程序
1.环境部署
1:scrapy部署:我是在阿里云的centos+python2.7的环境下部署的scrapy。本人比较习惯使用python3.6.1。之前写爬虫程序的时候最经常用的是urllib.request库,其他要用到的模块在各个python版本大同小异。用python2.7的原因是linux自带的python版本默认是次版本,而我在编译安装python3.6的时候环境安装不全,导致安装scrapy之后创建工程的时候提示找不到_sqlite模块,索性直接用2.7 pip install scrapy搞定,安装过程中最常见的问题是提示找不到Twisted模块,下载之后解压cd到目录下运行python setup.py install搞定
2:数据存储使用mongodb,这个数据库存储数据的格式和python字典的格式非常象,很容易理解
3:网站分析,电影天堂的网站基本上都是静态的,没有涉及到javascript和ajax,所以信息提取非常简单,这里只爬取三个信息,分别是下载地址(source),电影名称(name),和主要信息(message)
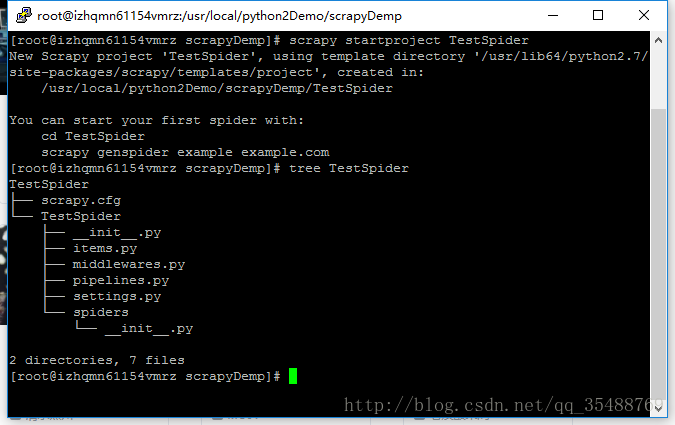
4:scrapy的使用,cd到部署项目的目录下,键入“scrapy startproject 项目名“创建项目,创建完成后用tree命令可以查看项目结构如下
- spiders:用与放置爬虫模块代码的目录,爬虫模块负责从网站中解析数据,需要继承scrapy.Spider类,并且至少定义一下几个属性
1.name属性:用于区别Spider,名字必须唯一。
2.start_urls属性 :Spider启动时的初始url,第一个爬取的页面
3.parse()函数:该函数传入的response参数向url发送请求后获得的响应,此方法获得数据后解析数据和生成进一步爬取的url - items.py:类似于jevaee中的javabean类,用于封装要爬取的数据的类,需要继承scrapy.Item类
- piplines.py:用于对封装后的数据类进行处理,验证数据是否正确,储存数据或者直接丢弃数据,该类必须实现process_item()方法,传入item和spider参数,item是数据封装的类,spider代表爬取该item的spider。该类需要在setting.py中激活
- middlewares.py:中间件,介于request/response之间的钩子程序,用于修改reuqest和response的类
- settings.py:设置文件
- spiders:用与放置爬虫模块代码的目录,爬虫模块负责从网站中解析数据,需要继承scrapy.Spider类,并且至少定义一下几个属性
2.程序编写
- dytts_spider.py
import sys
sys.path.append("../") #添加items.py模块
import scrapy
import urlparse
from bs4 import BeautifulSoup
import re
from items import DyttspiderItem
class DyttSpider(scrapy.Spider):
name = "dyttspiders" #爬虫名字
allowed_domains = ["ygdy8.com"] #允许爬取网页的域名
start_urls = ["http://www.ygdy8.com/html/gndy/dyzz/20130820/42954.html"] #初始url
def parse(self,response):
start_url = "http://www.ygdy8.com/" #用于构建完整的url
print("is parse :%s"%response.url)
rep = re.compile("<.*?>") #用于提取电影内容的正则表达式
mat = r".*/\d+/\d+\.html" #用于匹配需要爬取网页的正则表达式
urls = response.xpath("//a/@href").extract() #scrapy的选择器语法,用于提取网页链接
data = response.body #响应的文本
soup = BeautifulSoup(data,"lxml") #构建BeautifulSoup对象
content = soup.find("div",id="Zoom") #电影信息元素
item = None
if content:
sources = content.find_all("a") #电影下载地址元素
source = [] #电影下载地址
if sources:
for link in sources:
source.append(link.text)
print(source[0])
name = soup.find("title") #电影名称
if name:
name = name.text
print("%s is parsed"%name.encode("utf-8"))
message = content.text.encode("utf-8") #电影信息
message = rep.sub(" ",message)
item = DyttspiderItem(name=name,message=message,source=source) #构建数据类
else:
print("error!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!")
yield item #返回数据类
for url in urls:
if re.match(mat,url) != None:
full_url = urlparse.urljoin(start_url,url) #返回进一步爬取的url
yield scrapy.Request(url=full_url,callback=self.parse)
- 2.items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DyttspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field() #电影名称
source = scrapy.Field() #电影下载地址
message = scrapy.Field() #电影信息- pipelines.py
import pymongo
from items import DyttspiderItem
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
class DyttspiderPipeline(object):
def __init__(self):
self.client = pymongo.MongoClient() #构建mongodb客户端
def process_item(self, item, spider):
if item:
print("is saveing a move %s"%item.name)
dic_item = dict(item) #将数据类转化为能存储的字典
result = self.client.moves.ygdy.find_one({"name":item["name"]}) #查询数据库中是否存在此数据
if result == None:
self.client.moves.ygdy.insert(dic_item)
else:
print("one move is in document document")pipelines需要在settings.py中注册,详见后面的seetings.py
- middlewares.py
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
import random
class MyUserAgentMiddleware(UserAgentMiddleware):
'''
设置User-Agent
'''
def __init__(self, user_agent):
self.user_agent = user_agent
@classmethod
def from_crawler(cls, crawler):
return cls(
user_agent=crawler.settings.get('MY_USER_AGENT')
)
def process_request(self, request, spider):
agent = random.choice(self.user_agent)
request.headers['User-Agent'] = agent用于在request中添加随机user-agent
- settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for DyttSpider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'DyttSpider'
SPIDER_MODULES = ['DyttSpider.spiders']
NEWSPIDER_MODULE = 'DyttSpider.spiders'
COOKIES_ENABLES=False
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'DyttSpider (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
DOWNLOADER_MIDDLEWARES={
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware':None,
'DyttSpider.middlewares.MyUserAgentMiddleware':400,
}
ITEM_PIPELINES = {"DyttSpider.pipelines.DyttspiderPipeline":300}
MY_USER_AGENT = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",]
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'DyttSpider.middlewares.DyttspiderSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'DyttSpider.middlewares.MyCustomDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'DyttSpider.pipelines.DyttspiderPipeline': 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'爬取了dytt和ygdy两个域名的电影之后的结果
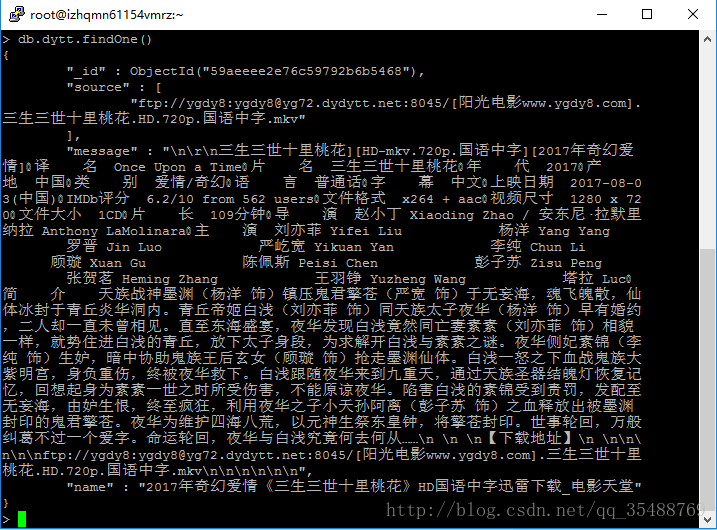
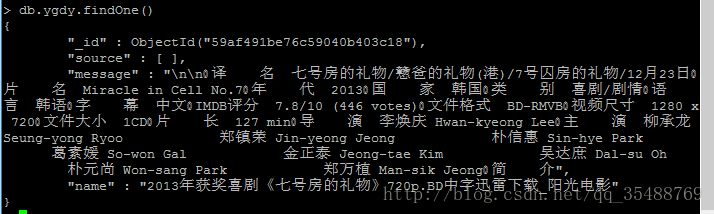

一共大约有八千多部电影
ps:在使用putty连接阿里云服务器时发现只要关闭连接时,爬虫程序也会随之关闭,需要使用screen来开启新窗口然后ctrl-a-d来后台窗口然后退出















 2266
2266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









