







 本文介绍使用ScrapyCrawlSpider爬取电影天堂网站的过程,包括项目创建、爬虫定义、数据解析及Mysql存储。通过XPath提取电影标题、发布时间和下载链接,并利用pymysql将数据保存至本地数据库。
本文介绍使用ScrapyCrawlSpider爬取电影天堂网站的过程,包括项目创建、爬虫定义、数据解析及Mysql存储。通过XPath提取电影标题、发布时间和下载链接,并利用pymysql将数据保存至本地数据库。
Scrapy CrawlSpider爬取
目标网址:http://www.dytt8.net
创建项目:scrapy startproject <爬虫项目文件的名字>
生成 CrawlSpider 命令:scrapy genspider -t crawl <爬虫名字> <爬虫域名>
终端运行:scrapy crawl <爬虫的名字>
Python操作Mysql数据库操作: https://www.runoob.com/python/python-reg-expressions.html
爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
import re
class DySpider(CrawlSpider):
name = 'dy'
allowed_domains = ['www.dytt8.net']
start_urls = ['http://www.dytt8.net/']
rules = (
Rule(LinkExtractor(allow=r'dytt8\.net/html/gndy/dyzz/\d+/\d+\.html'), callback='parse_item'),
)
def parse_item(self, response):
item = {}
item['title'] = response.xpath('//div[@class="title_all"]/h1/font/text()').get()
item['datetime'] = response.xpath('//div[@class="co_content8"]/ul/text()').get()
item['datetime'] = re.sub('\r\n', '', item['datetime'])
item['download'] = response.xpath('//div[@class="co_area2"]//tbody//td/a/@href').get()
yield item
pipelines.py 管道文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
class MoviesPipeline(object):
def __init__(self):
self.db = pymysql.connect('127.0.0.1', 'root', 'root', 'spider')
self.cursor = self.db.cursor()
def process_item(self, item, spider):
sql = 'create table if not exists movies (title varchar (255) not null ,datetime varchar (255) not null , download varchar (255) not null )'
sql_insert = 'insert into movies(title, datetime, download) value (%s, %s, %s)'
args = (item['title'], item['datetime'], item['download'])
self.cursor.execute(sql)
self.cursor.execute(sql_insert, args)
return item
def close_spider(self, spider):
self.db.commit()
self.db.close()
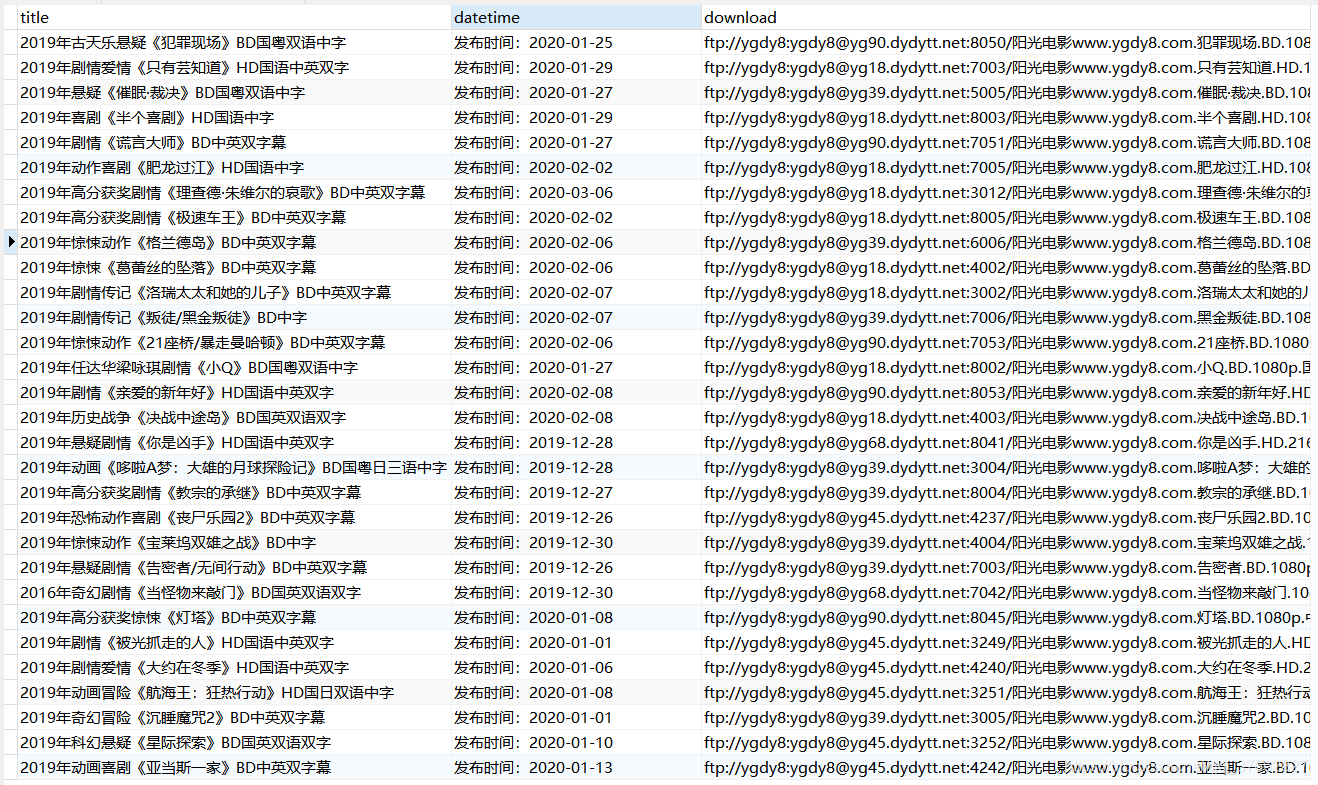
运行结果:

















 981
981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









