









本文代码以及相应数据集
ID3算法:核心是在决策树各个节点上应用 信息增益 准则选择特征,递归的构建决策树。具体方法是:从根结点开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子结点;再对子结点递归的调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止。ID3算法还存在另一个问题,它不能直接出来连续型特征。只有事先将连续型特征转为离散型,才能在ID3中使用。 但这种转换过程会破坏连续型变量的内在性质。由于数据集是连续的数据,所以本实验采用的按区域划分的方法,将连续数据划分为离散数据。如下图所示:
连续数据:

离散数据:
1 ID3 决策分类树
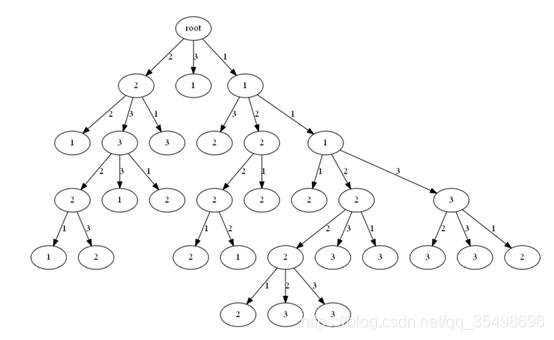
在数据集Wine中,构建的决策图如下所示:
根据所构建的决策树,分类的准确率如下图所示:

python 代码:
from math import log
import matplotlib
import matplotlib.pyplot as plt
from graphviz import Digraph
def loadSplitDataSet(txtname,rate):
file = open(txtname)
lines1 = file.readlines()
file.close
#print(lines1)
lines2=[]
for line in lines1:
lineTemp=line.replace('\n','').split(',')
lines2.append(lineTemp)
step=int(1/(1-rate))
testSet=lines2[::step]
del lines2[::step]
trainSet=lines2
trainData=[]
testData=[]
trainLabel=[]
testLabel=[]
for x in trainSet:
trainDataTemp=[]
trainLabel.append(int(x[0]))
for y in x[1:]:
trainDataTemp.append(float(y))
trainData.append(trainDataTemp)
for x in testSet:
testDataTemp=[]
testLabel.append(int(x[0]))
for y in x[1:]:
testDataTemp.append(float(y))
testData.append(testDataTemp)
#print(len(trainData))
#print(len(testData))
#print(len(trainLabel))
#print(len(testLabel))
return trainData,testData,trainLabel,testLabel
class DecisonTree:
trainData = []
trainLabel = []
featureValus = {} #每个特征所有可能的取值
interval=[]
def __init__(self, trainData, trainLabel, threshold):
self.loadData(trainData, trainLabel)
self.threshold = threshold
self.tree = self.createTree(range(0,len(trainLabel)), range(0,len(trainData[0])))
#加载数据
def loadData(self, trainData, trainLabel):
if len(trainData) != len(trainLabel):
raise ValueError('input error')
self.trainData = trainData
self.trainLabel = trainLabel
self.trainDataDiscrete()
#计算 featureValus
for data in self.trainData:
for index, value in enumerate(data):
if not index in self.featureValus.keys():
self.featureValus[index] = [value]
if not value in self.featureValus[index]:
self.featureValus[index].append(value)
#连续数据离散化,均值离散
def trainDataDiscrete(self):
trainData=[]
interval=[]
countClass=len(set(self.trainLabel))
if(countClass==0):
countClass=1
for i in range(len(self.trainData[0])):
tempData=[x[i] for x in self.trainData]
step=(max(tempData)-min(tempData))/countClass
intervalTemp=[]
trainDataTemp=[]
for j in range(1,countClass+1):
intervalTemp.append(min(tempData)+j*step)
interval.append(intervalTemp)
for x in tempData:
mark=countClass
for (index,y) in enumerate(intervalTemp):
if(x<y and x>=y-step):
mark=index+1
trainDataTemp.append(mark)
trainData.append(trainDataTemp)
trainData=self.transpose(trainData)
self.interval=interval
self.trainData=trainData
def transpose(self, matrix):
new_matrix = []
for i in range(len(matrix[0])):
matrix1 = []
for j in range(len(matrix)):
matrix1.append(matrix[j][i])
new_matrix.append(matrix1)
return new_matrix
#计算信息熵
def caculateEntropy(self, dataset):
labelCount = self.labelCount(dataset)
size = len(dataset)
result = 0
for i in labelCount.values():
pi = i / float(size)
result -= pi * (log(pi) /log(2))
return result
#计算信息增益
def caculateGain(self, dataset, feature):
values = self.featureValus[feature] #特征feature 所有可能的取值
result = 0
for v in values:
subDataset = self.splitDataset(dataset=dataset, feature=feature, value=v)
result += len(subDataset) / float(len(dataset)) * self.caculateEntropy(subDataset)
return self.caculateEntropy(dataset=dataset) - result
def splitDataset(self, dataset, feature, value):
reslut = []
for index in dataset:
if self.trainData[index][feature] == value:
reslut.append(index)
return reslut
#计算数据集中,每个标签出现的次数
def labelCount(self, dataset):
labelCount = {}
for i in dataset:
if trainLabel[i] in labelCount.keys():
labelCount[trainLabel[i]] += 1
else:
labelCount[trainLabel[i]] = 1
return labelCount
'''
dataset:数据集
features:特征集
'''
def createTree(self, dataset, features):
labelCount = self.labelCount(dataset)
#如果特征集为空,则该树为单节点树
#计算数据集中出现次数最多的标签
if not features:
return max(list(labelCount.items()),key = lambda x:x[1])[0]
#如果数据集中,只包同一种标签,则该树为单节点树
if len(labelCount) == 1:
return list(labelCount.keys())[0]
#计算特征集中每个特征的信息增益
#l = map(lambda x : [x, self.caculateGain(dataset=dataset, feature=x)], features)
l = list(map(lambda x : [x, self.caculateGain(dataset=dataset, feature=x)], features))
#print(l)
if len(l) == 0:
return max(list(labelCount.items()),key = lambda x:x[1])[0]
#选取信息增益最大的特征
feature, gain = max(l, key = lambda x: x[1])
#如果最大信息增益小于阈值,则该树为单节点树
#
if self.threshold > gain:
return max(list(labelCount.items()),key = lambda x:x[1])[0]
tree = {}
#选取特征子集
subFeatures = filter(lambda x : x != feature, features)
subFeatures = list(subFeatures)
#print(self.featureValus[feature])
#tree['feature'] = feature
#构建子树
for value in self.featureValus[feature]:
subDataset = self.splitDataset(dataset=dataset, feature=feature, value=value)
#保证子数据集非空
if not subDataset:
continue
tree[value] = self.createTree(dataset=subDataset, features=subFeatures)
return tree
def classify(self, data):
count=0
def f(tree, data,count=0):
if type(tree) != dict:
#print(count)
return tree
else:
count+=1
#print(tree[data[tree['feature']]])
return f(tree[data[tree['feature']]], data,count)
return f(self.tree, data,count)
#连续数据离散化,均值离散
def trainDataDiscrete(trainData,interval):
matrix=[]
for i in range(len(trainData[0])):
tempData=[x[i] for x in trainData]
trainDataTemp=[]
for x in tempData:
mark=3
last=0
for (index,y) in enumerate(interval[i]):
if(x<y and x>=last):
mark=index+1
last=y
trainDataTemp.append(mark)
matrix.append(trainDataTemp)
new_matrix = []
for i in range(len(matrix[0])):
matrix1 = []
for j in range(len(matrix)):
matrix1.append(matrix[j][i])
new_matrix.append(matrix1)
return new_matrix
''' 画决策树'''
def plot_model(tree, name):
g = Digraph("G", filename=name, format='png', strict=False)
first_label = 'root'
g.node("0", str(first_label))
#tree={first_label:tree}
#print(tree)
_sub_plot(g, tree, "0")
g.view()
root = "0"
def _sub_plot(g, tree, inc):
global root
#first_label = list(tree.keys())[0]
#ts = tree[first_label]
if(isinstance(tree, dict)):
tslist=list(tree.keys())
else:
tslist=[tree]
print("tsList:",tslist)
for i in tslist:
'''
if(isinstance(tree[first_label], dict)):
treeDict=tree[first_label]
else:
treeDict={i:first_label}
print('treeDict:',treeDict)
'''
if isinstance(tree[i], dict):
root = str(int(root) + 1)
g.node(root, str(i))
g.edge(inc, root, str(i))
_sub_plot(g, tree[i], root)
else:
root = str(int(root) + 1)
g.node(root, str(tree[i]))
g.edge(inc, root, str(i))
if __name__ == '__main__':
trainData,testData,trainLabel,testLabel=loadSplitDataSet(r'C:\Users\huawei\Desktop\统计学习理论\实验三\classify\wine.data',0.8)
tree = DecisonTree(trainData=trainData, trainLabel=trainLabel, threshold=0)
print(tree.tree)
plot_model(tree.tree, "hello.gv")
'''
newTestData=trainDataDiscrete(testData,tree.interval)
count=0
for i in range(len(newTestData)):
#print(newTestData[i])
try:
tree.classify(newTestData[i])
if(tree.classify(newTestData[i])==testLabel[i]):
count+=1
except Exception as e:
print(Exception,',',e)
print('The accuracy is %.2f'%(count/ len(testLabel)))
'''














 1559
1559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









