








作者:Michael Galarnyk
翻译:李润嘉
校对:和中华
本文约3600字,建议阅读15分钟。
本教程介绍了用于分类的决策树,即分类树,包括分类树的结构,分类树如何进行预测,使用scikit-learn构造分类树,以及超参数的调整。
本教程详细介绍了决策树的工作原理
由于各种原因,决策树一种流行的监督学习方法。决策树的优点包括,它既可以用于回归,也可用于分类,易于解释并且不需要特征缩放。它也有一些缺点,比如容易过拟合。本教程介绍了用于分类的决策树,也被称为分类树。
除此之外,本教程还将涵盖:
分类树的结构(树的深度,根节点,决策节点,叶节点/终端节点)
分类树如何进行预测
如何通过Python中的scikit-learn构造决策树
超参数调整
与往常一样,本教程中用到的代码可以在我的github(结构,预测)中找到,我们开始吧!
什么是分类树?
分类和回归树(CART)是由Leo Breiman引入的,用一种于解决分类或回归预测建模问题的决策树算法。本文只介绍分类树。
分类树
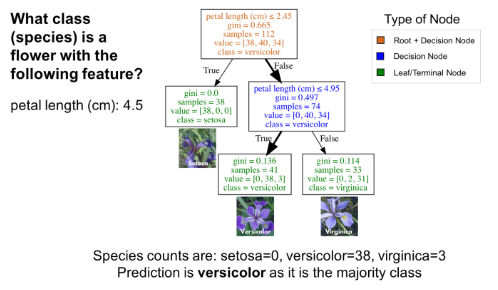
从本质上讲,分类树将分类转化为一系列问题。下图是在IRIS数据集(花卉种类)上训练的一个分类树。根节点(棕色)和决策节点(蓝色)中包含了用于分裂子节点的问题。根节点即为最顶端的决策节点。换句话说,它就是你遍历分类树的起点。叶子节点(绿色),也叫做终端节点,它们不再分裂成更多节点。在叶节点处,通过多数投票决定分类。

将三个花卉品种(IRIS数据集)一一进行分类的分类树
如何使用分类树
使用分类树,要从根节点(棕色)开始,逐层遍历整棵树,直到到达叶节点(终端节点)。如下图所示的分类树,假设你有一朵花瓣长度为4.5cm的花,想对它进行分类。首先从根节点开始,先回答“花瓣长度(单位:cm)≤ 2.45吗?”因为宽度大于2.45,所以回答否。然后进入下一个决策节点,回答“花瓣长度(单位:cm)≤ 4.95吗?”。答案为是,所以你可以预测这朵花的品种为变色鸢尾(versicolor)。这就是一个简单的例子。
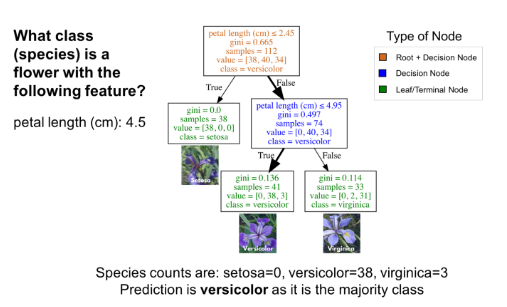
分类树如何生长(非数学版)
分类树从数据中学到了一系列“如果…那么…”的问题,其中每个问题都涉及到一个特征和一个分割节点。从下图的局部树(A)可看出,问题“花瓣长度(单位:cm)≤ 2.45”将数据基于某个值(本例中为2.45)分成两个部分。这个数值叫做分割点。对分割点而言,一个好的值(使得信息增益最大)可将类与类之间分离开。观察下图中的B部分可知,位于分割点左侧的所有点都被归为山鸢尾类(setosa),右侧的所有点则被归为变色鸢尾类(versicolor)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









