






 本文探讨了Spark在处理二级分区时产生的近10000个文件夹,导致的小文件IO问题,严重影响了写入Hive隐藏目录的效率。在处理千万级别数据时,虽然数据量仅为3.4GB,但过多的分区反而造成了性能下降。建议在数据量较小的情况下避免过度分区,以防止产生过多小文件,提高处理效率。
本文探讨了Spark在处理二级分区时产生的近10000个文件夹,导致的小文件IO问题,严重影响了写入Hive隐藏目录的效率。在处理千万级别数据时,虽然数据量仅为3.4GB,但过多的分区反而造成了性能下降。建议在数据量较小的情况下避免过度分区,以防止产生过多小文件,提高处理效率。
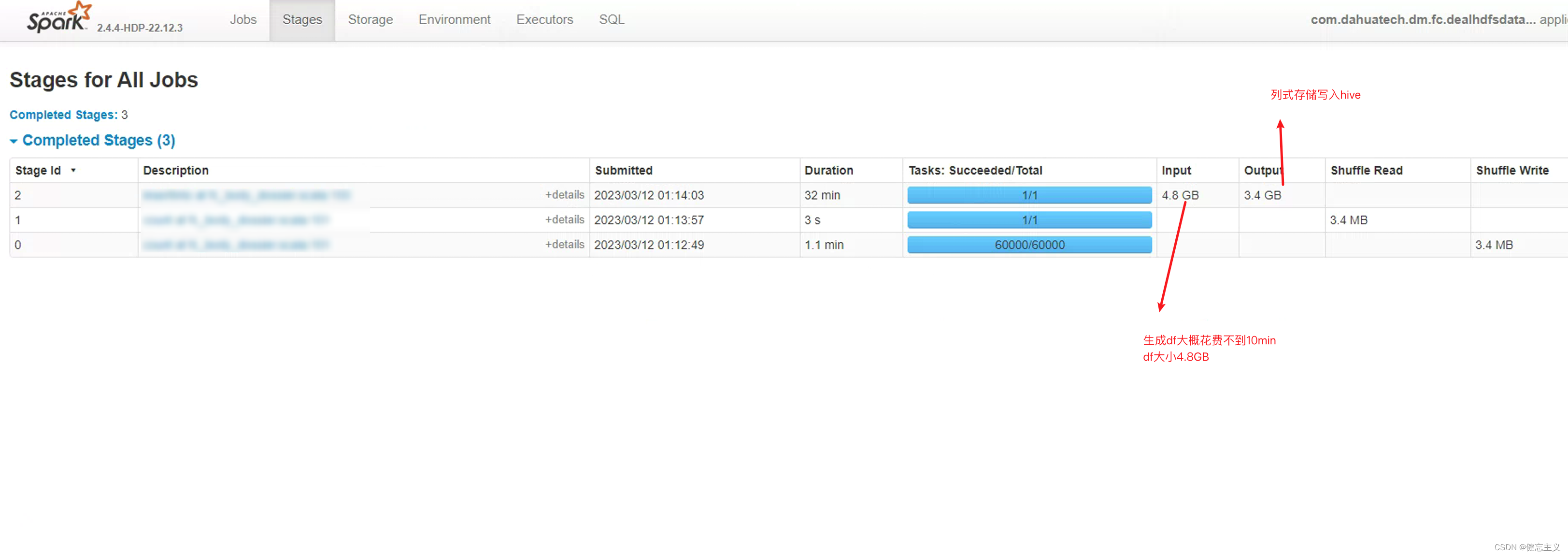

这里可以看到 spark的输出3.4GB 就是parque(默认启用压缩)的文件大小.
这里有个问题是 我的表是二级分区 一级有30个 二级有300个 所以总共接近10000个文件夹 途中可以看到8.2k个文件夹 即实际有8200个分区;
千万级别的数据 存储只占用3GB 但是文件夹特别多,这导致spark在输出到hive隐藏目录时 小文件IO问题导致耗时特别长.
所以分区内如果数据量太小 是没必要过度分区的,弊大于利.

这里可以看到 spark的输出3.4GB 就是parque(默认启用压缩)的文件大小.
这里有个问题是 我的表是二级分区 一级有30个 二级有300个 所以总共接近10000个文件夹 途中可以看到8.2k个文件夹 即实际有8200个分区;
千万级别的数据 存储只占用3GB 但是文件夹特别多,这导致spark在输出到hive隐藏目录时 小文件IO问题导致耗时特别长.
所以分区内如果数据量太小 是没必要过度分区的,弊大于利.

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言






















 188
188







