






 本文介绍了使用TensorFlow进行风格迁移的方法,特别是在固定内容和风格下,利用VGG19网络。文章讨论了Gram矩阵的概念及其在度量图像风格上的作用,并提供了计算和应用Gram矩阵的技巧。通过训练网络,可以生成风格化的图像,超参数的设置是逐步调整的。
本文介绍了使用TensorFlow进行风格迁移的方法,特别是在固定内容和风格下,利用VGG19网络。文章讨论了Gram矩阵的概念及其在度量图像风格上的作用,并提供了计算和应用Gram矩阵的技巧。通过训练网络,可以生成风格化的图像,超参数的设置是逐步调整的。
原文链接: tf 风格迁移 固定内容 固定风格 vgg19
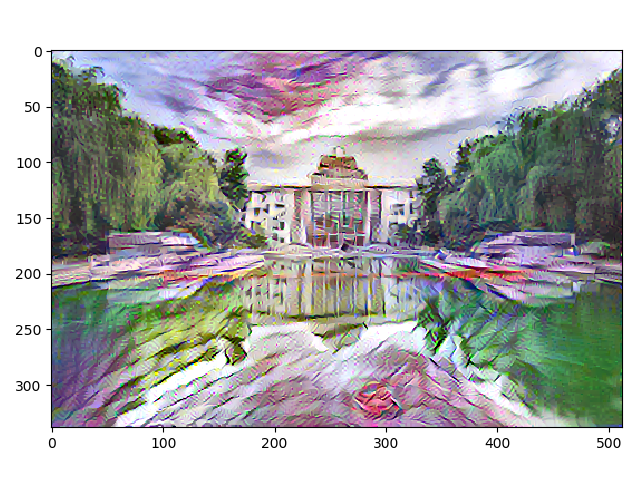
效果
开始时会有很大的噪声不过最后都会收敛

Gram Matrices 参考
https://blog.csdn.net/tunhuzhuang1836/article/details/78474129
我们使用 Gram矩阵 来表示图像的风格特征。对于每一张图片C X H X W
C表示卷积核的通道数
H X W 卷积核通过学习后输出的H X W代表这张图片的feature map
格拉姆矩阵可以看做feature之间的偏心协方差矩阵(即没有减去均值的协方差矩阵),在feature map中,每个数字都来自于一个特定滤波器在特定位置的卷积,因此每个数字代表一个特征的强度,而Gram计算的实际上是两两特征之间的相关性,哪两个特征是同时出现的,哪两个是此消彼长的等等,同时,Gram的对角线元素,还体现了每个特征在图像中出现的量,因此,Gram有助于把握整个图像的大体风格。有了表示风格的Gram Matrix,要度量两个图像风格的差异,只需比较他们Gram Matrix的差异即可。总之, 格拉姆矩阵用于度量各个维度自己的特性以及各个维度之间的关系。内积之后得到的多尺度矩阵中,对角线元素提供了不同特征图各自的信息,其余元素提供了不同特征图之间的相关信息。这样一个矩阵,既能体现出有哪些特征,又能体现出不同特征间的紧密程度[2]。
Gram矩阵 为了度量自己的特性以及各个维度之间的关系
关于 Gram矩阵还有以下三点值得注意:
1 Gram矩阵的计算采用了累加的形式,抛弃了空间信息。一张图片的像素随机打乱之后计算得到的Gram Matrix和原图的 Gram Matrix 一样。所以认为 Gram Matrix所以认为 Gram Matrix抛弃了元素之间的空间信息。
2 Gram Matrix的结果与feature maps F 的尺寸无关,只与通道个数有关,无论H,W的大小如何,最后 Gram Matrix的形状都是CXC
3 对于一个C X H X W的 feature maps,可以通过调整形状和矩阵乘法运算快速计算它的 Gram Matrix。即先将F调整到 C X (HW)的二维矩阵,然后再计算F 和F的转置。结果就为 Gram Matrix
使用vgg19网络
输入风格图片,得到风格图片在各个层的输出
输入内容图片,得到内容图片在各个层的输出
初始化风格化图片,可以使用随机矩阵或者零矩阵或者内容图片(容易收敛)
计算loss并训练网络 即可获得风格化的图片
超参数设置是在训练网络的过程中慢慢调节的
完整代码
import tensorflow as tf
import numpy as np
import time
import cv2 as cv
import matplotlib.pyplot as plt
import tensorflow.contrib.slim as slim
import tensorflow.contrib.slim.nets as nets
STYLE_IMAGE_PATHS = [
# './styled_images/starry.jpg',
'./styled_images/feathers.jpg',
# './styled_images/paojie.jpg',
# './styled_images/candy.jpg',
# './styled_images/tree.jpg',
]
STYLE_WEIGHTS = [1., 1., 1.]
STYLE_LAYERS = [
'vgg_19/conv1/conv1_1',
'vgg_19/conv2/conv2_1',
'vgg_19/conv3/conv3_1',
'vgg_19/conv4/conv4_1',
'vgg_19/conv5/conv5_1',
]
STYLE_LAYER_WEIGHTS = [.1, .1, .1, .1, .1, ]
CONTENT_LAYERS = [
# 'vgg_19/conv1/conv1_2',
# 'vgg_19/conv2/conv2_2',
# 'vgg_19/conv3/conv3_2',
'vgg_19/conv4/conv4_2',
# 'vgg_19/conv5/conv5_2',
]
# CONTENT_LAYERS = ['relu4_2']
CONTENT_LAYER_WEIGHTS = [.1, .1, .1, .1, .1, ]
LEARNING_RATE = 1
MEAN_PIXEL = np.array([123.68, 116.779, 103.939]).reshape((1, 1, 1, 3))
TRAIN_STEP = 3000
SHOW_STEP = 200
SAMPLE_STEP = 3
CONTENT_IMAGE_PATH = './images/xjtu2.jpg'
MAX_IMAGE_SIZE = 512
VIDEO_PATH = './video/out2.mp4'
FPS = 30
CONTENT_WEIGHT = 1.
STYLE_WEIGHT = .0001
TV_WEIGHT = .0001
VGG19_CKPT_PATH = r"D:\data\tf_models\vgg19\vgg_19.ckpt"
# 1000
# Single image elapsed time: 256.1928884983063
# TV_WEIGHT = 0
def build_model(in_x):
with tf.variable_scope('', reuse=tf.AUTO_REUSE):
_, net = nets.vgg.vgg_19(in_x, spatial_squeeze=False)
net['input'] = in_x
return net
def content_layer_loss(p, x):
_, h, w, d = p.get_shape()
M = h.value * w.value
N = d.value
# K = 1. / (2. * N ** 0.5 * M ** 0.5)
K = 1. / (N * M)
# K = 1. / 2.
loss = K * tf.reduce_sum(tf.pow((x - p), 2))
return loss
def style_layer_loss(a, x):
_, h, w, d = a.get_shape()
M = h.value * w.value
N = d.value
A = gram_matrix(a, M, N)
G = gram_matrix(x, M, N)
loss = (1. / (4 * N ** 2 * M ** 2)) * tf.reduce_sum(tf.pow((G - A), 2))
return loss
def gram_matrix(x, area, depth):
F = tf.reshape(x, (area, depth))
G = tf.matmul(tf.transpose(F), F)
return G
def sum_style_losses(styled_net, style_nets):
with tf.variable_scope('sum_style'):
total_style_loss = 0.
for net, img_weight in zip(style_nets, STYLE_WEIGHTS):
style_loss = 0.
print(styled_net.keys())
for layer, weight in zip(STYLE_LAYERS, STYLE_LAYER_WEIGHTS):
a = net[layer]
x = styled_net[layer]
a = tf.convert_to_tensor(a)
style_loss += style_layer_loss(a, x) * weight
style_loss /= float(len(STYLE_LAYERS))
total_style_loss += (style_loss * img_weight)
total_style_loss /= float(len(style_nets))
return total_style_loss
def sum_content_losses(styled_net, content_net):
with tf.variable_scope('sum_content'):
content_loss = 0.
for layer, weight in zip(CONTENT_LAYERS, CONTENT_LAYER_WEIGHTS):
p = content_net[layer]
x = styled_net[layer]
p = tf.convert_to_tensor(p)
content_loss += content_layer_loss(p, x) * weight
content_loss /= float(len(CONTENT_LAYERS))
return content_loss
def preprocess(img):
img = img.copy()[..., ::-1]
img = img[np.newaxis, :, :, :]
img -= MEAN_PIXEL
return img
def postprocess(img):
img = img + MEAN_PIXEL
# shape (1, h, w, d) to (h, w, d)
img = np.clip(img, 0, 255).astype('uint8')[0]
# rgb to bgr
img = img[..., ::-1]
return img
def stylize(content_img, style_imgs):
with tf.Session() as sess:
style_nets = [
build_model(tf.constant(img))
for img in style_imgs
]
content_net = build_model(tf.constant(content_img))
styled_image = tf.Variable(np.zeros(content_img.shape, dtype=np.float32))
# styled_image = tf.Variable(content_img)
styled_net = build_model(styled_image)
# style loss
L_style = sum_style_losses(styled_net, style_nets)
# content loss
L_content = sum_content_losses(styled_net, content_net)
# denoising loss
L_tv = tf.image.total_variation(styled_net['input'])[0]
# total loss
L_total = tf.reduce_sum(
[CONTENT_WEIGHT * L_content, STYLE_WEIGHT * L_style, TV_WEIGHT * L_tv]
)
train_op = tf.train.AdamOptimizer(LEARNING_RATE).minimize(L_total, var_list=[styled_image])
sess.run(tf.global_variables_initializer())
variables_to_restore = slim.get_variables_to_restore(include=['vgg_19'])
restorer = tf.train.Saver(variables_to_restore)
restorer.restore(sess, VGG19_CKPT_PATH)
# tf.summary.FileWriter('./log', sess.graph)
images = []
for iterations in range(1, 1 + TRAIN_STEP):
sess.run(train_op)
if not iterations % SAMPLE_STEP:
output_img = sess.run(styled_image)
output_img = postprocess(output_img)
images.append(output_img)
if not iterations % SHOW_STEP:
print(iterations, L_total.eval(), L_style.eval(), L_content.eval(), L_tv.eval())
output_img = sess.run(styled_image)
output_img = postprocess(output_img)[..., ::-1]
plt.imshow(output_img)
plt.show()
shape = (content_img.shape[2] * 2, content_img.shape[1] * 2)
save_video(images, shape)
def save_video(images, shape):
fourcc = cv.VideoWriter_fourcc(*"mp4v")
# 设置输出文件路径和大小
out_file = cv.VideoWriter(VIDEO_PATH, fourcc, FPS, shape)
for frame in images:
frame = cv.pyrUp(frame)
out_file.write(frame)
def get_content_image(path):
# bgr image
img = cv.imread(path, cv.IMREAD_COLOR)
img = img.astype(np.float32)
h, w, d = img.shape
scale = MAX_IMAGE_SIZE / (max(h, w))
shape = (int(scale * w), int(scale * h))
img = cv.resize(img, dsize=shape, interpolation=cv.INTER_AREA)
img = preprocess(img)
return img
def get_style_images(shape):
style_imgs = []
for path in STYLE_IMAGE_PATHS:
# bgr image
img = cv.imread(path, cv.IMREAD_COLOR)
img = cv.resize(img, dsize=shape, interpolation=cv.INTER_AREA)
img = img.astype(np.float32)
img = preprocess(img)
style_imgs.append(img)
return style_imgs
def render_single_image():
content_img = get_content_image(CONTENT_IMAGE_PATH)
shape = (content_img.shape[2], content_img.shape[1])
style_images = get_style_images(shape)
with tf.Graph().as_default():
st = time.time()
stylize(content_img, style_images)
ed = time.time()
print('Single image elapsed time: {}'.format(ed - st))
if __name__ == '__main__':
render_single_image()















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









