






原文链接: scrapy 爬取校花网
上一篇: scrapy 安装和简单命令
下一篇: scrapy 腾讯 招聘信息爬取
网址,爬取名称和对应的图片链接,并保存为json格式
http://www.xiaohuar.com/2014.html
新建项目
scrapy startproject girl项目结构
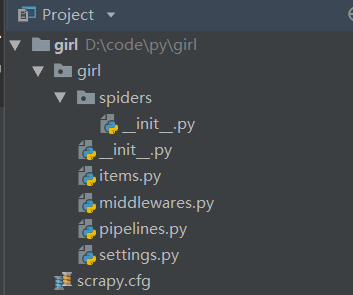
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
创建爬虫
scrapy genspider test www.xiaohuar.com/2014.html
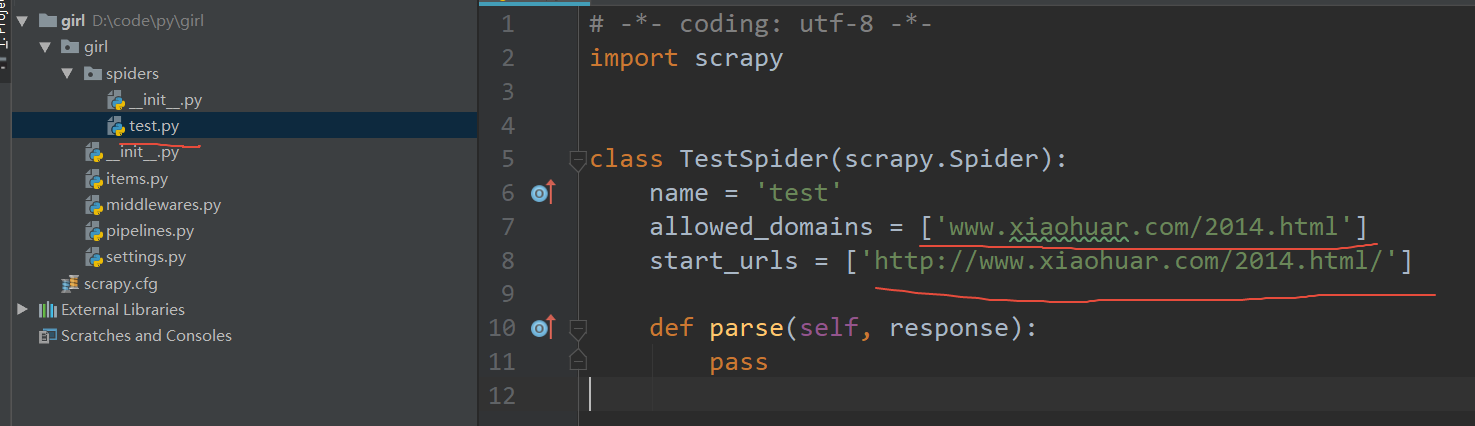
会自动生成爬虫文件
在设置文件中关闭robot设置

div,img,a标签的xpath依次获取后,进行修改
'//*[@id="list_img"]/div[1]/div/div[2]'
'//*[@id="list_img"]/div[1]/div/div[2]/div[1]/div[2]/a/img'
'//*[@id="list_img"]/div[1]/div/div[2]/div[1]/div[3]/span/a'
编写爬虫文件
import scrapy
class TestSpider(scrapy.Spider):
name = 'test'
allowed_domains = ['xiaohuar.com']
start_urls = ['http://www.xiaohuar.com/2014.html']
def parse(self, response):
items = []
nodes = response.xpath('//*[@id="list_img"]/div[1]/div/div')
print('nodes:', nodes)
for node in nodes:
url = node.xpath('div[1]/div[2]/a/img/@src').extract()[0]
text = node.xpath('div[1]/div[3]/span/a/text()').extract()[0]
print(text, url)
item = {}
item['name'] = text
item['url'] = url
items.append(item)
return items
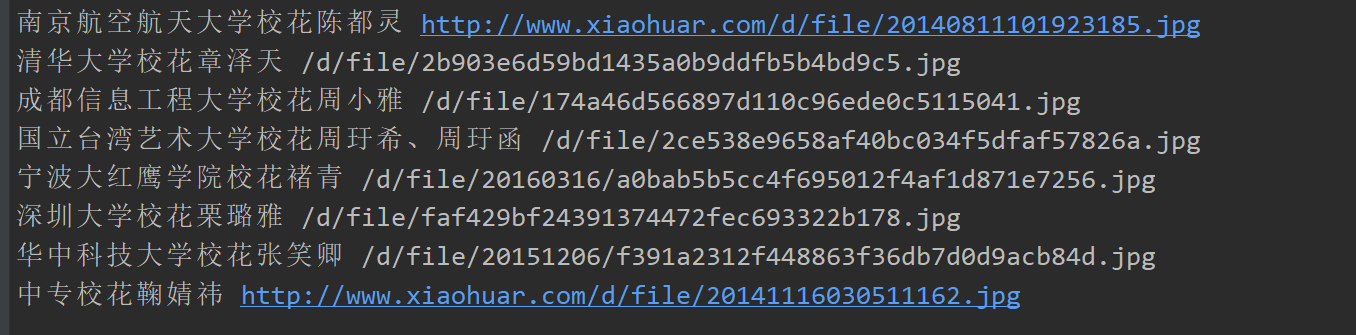
启动并保存为json格式,设置不输出日志,默认可以保存为json,csv,xml等格式
scrapy crawl test -o girls.json --nolog
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









