







项目地址: https://github.com/Feeyao/License-plate-recognition
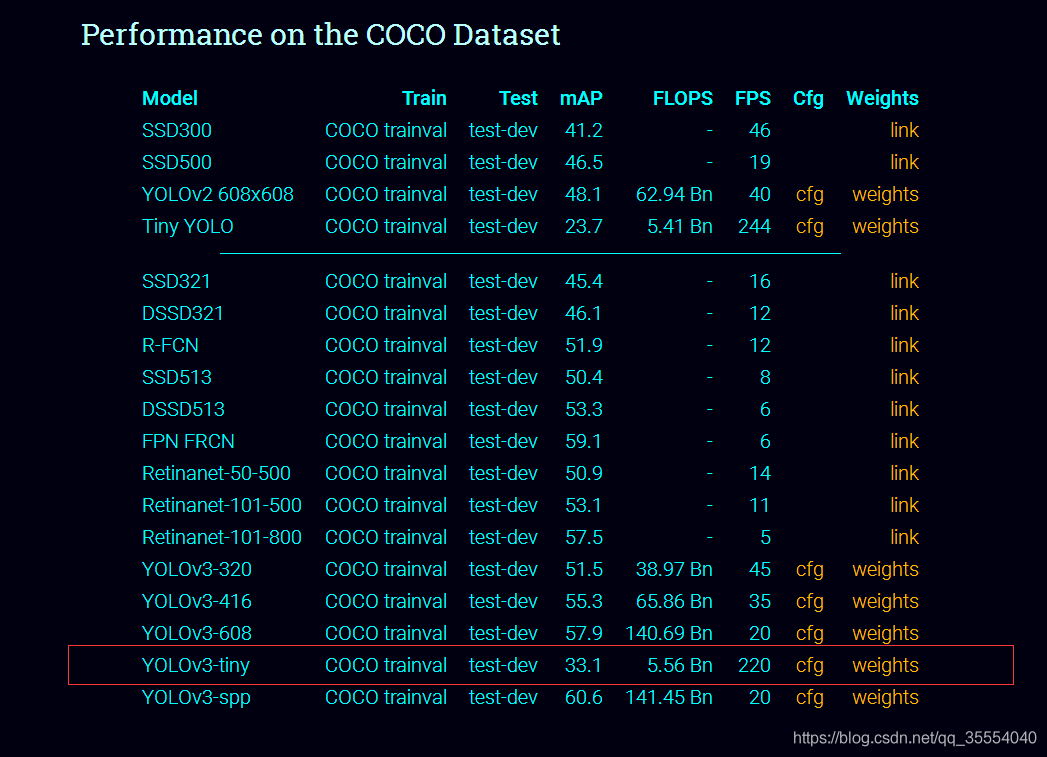
1. 从https://pjreddie.com/darknet/yolo/官网可以看到yolov3-tiny在GPU模式下可以高达220FPS. 可以说非常快. 因此完全可以满足车牌识别实时性的要求.
2. 和一般检测任务一样, 主要用到下面几个目录.
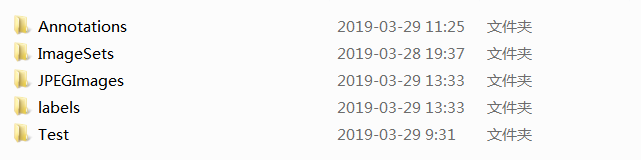
3. JPEGImages目录下是项目用到的一些训练数据. 大家也猜得到了, 这个项目是区域车牌识别, 因为车牌和字符同时作为一个网络的标签, 图片太大时, 网络输入不变的情况下, 字符会变得很小, 所以只能用局部区域进行识别了.

4. Annotations目录下是使用https://github.com/tzutalin/labelImg对车牌区域和字符进行定位标注文件.
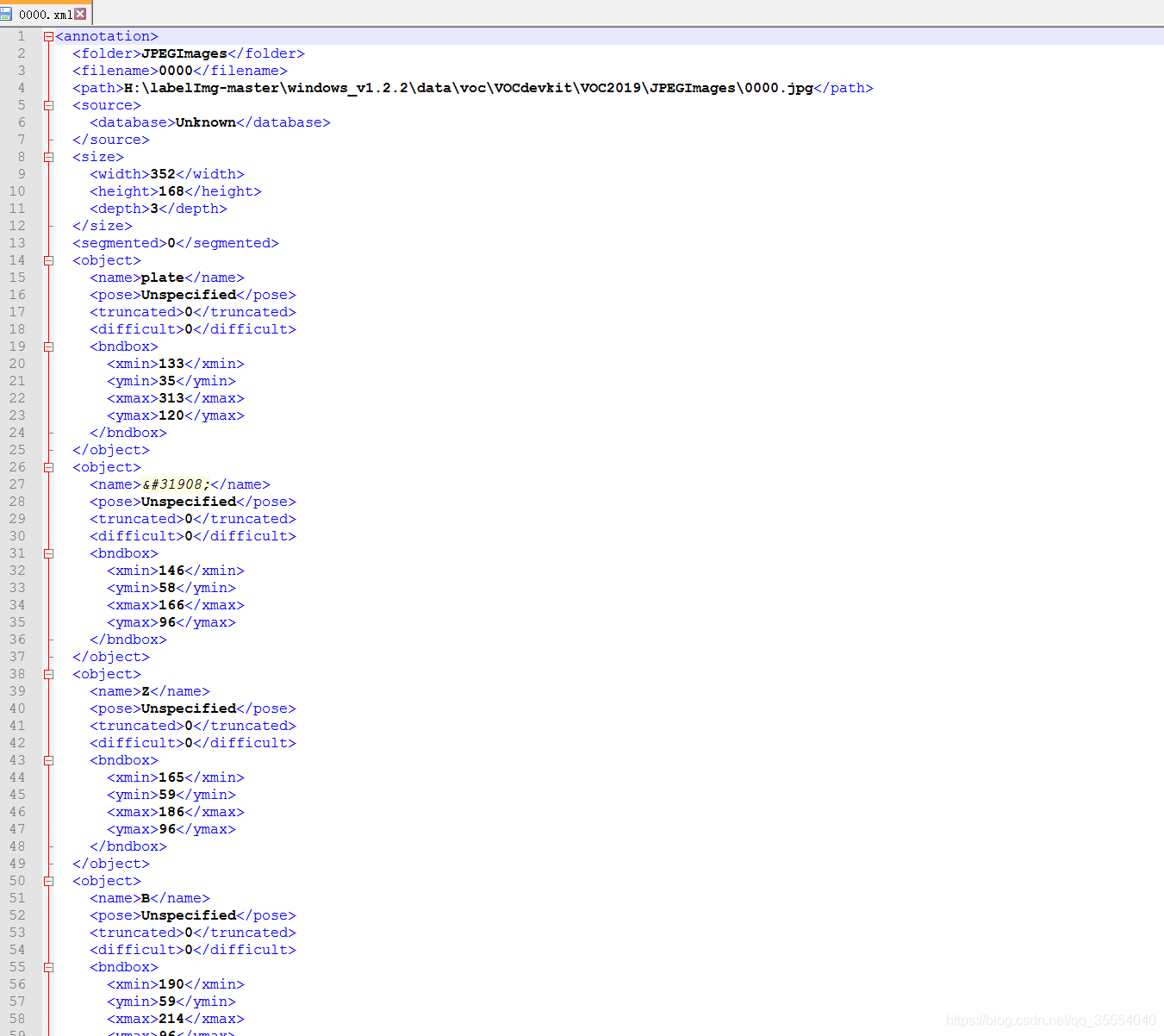
5. ImageSets/Main目录下是训练文件和验证文件对应的标签文件名, 没有后缀. 这个是手动生成的.虽然分了验证文件, 但是训练过程似乎没看到验证文件发挥什么作用O__O "…

6. Test目录下放的是测试文件.

7. 回到voc目录下, 打开voc_label.py修改数据集sets和标签classes
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
#sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
#classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
sets=[('2019','train'), ('2019', 'val')]
'''1和l重复, 0和O重复, 此处共列了70个标签'''
classes = ["plate", "0", "1", "2", "3", "4", "5", "6", "7", "8", "9",
"A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L",
"M", "N", "P", "Q", "R", "S", "T", "U", "V", "W", "X",
"Y", "Z", "澳", "川", "鄂", "甘", "赣", "港", "贵", "桂",
"黑", "沪", "吉", "冀", "津", "晋", "京", "警", "辽", "鲁",
"蒙", "闽", "宁", "青", "琼", "陕", "苏", "皖", "湘", "新",
"学", "渝", "豫", "粤", "云", "浙", "藏"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()运行python voc_label.py ,当前目录下生成两个保存训练图片的路径文件.

同时VOC2019/labels目录下生成训练的标签文件.

8. 到data目录下, 修改voc.data和voc.names, voc.data下的backup是训练过程weights保存的目录, 需要先在darknet.exe目录下创建
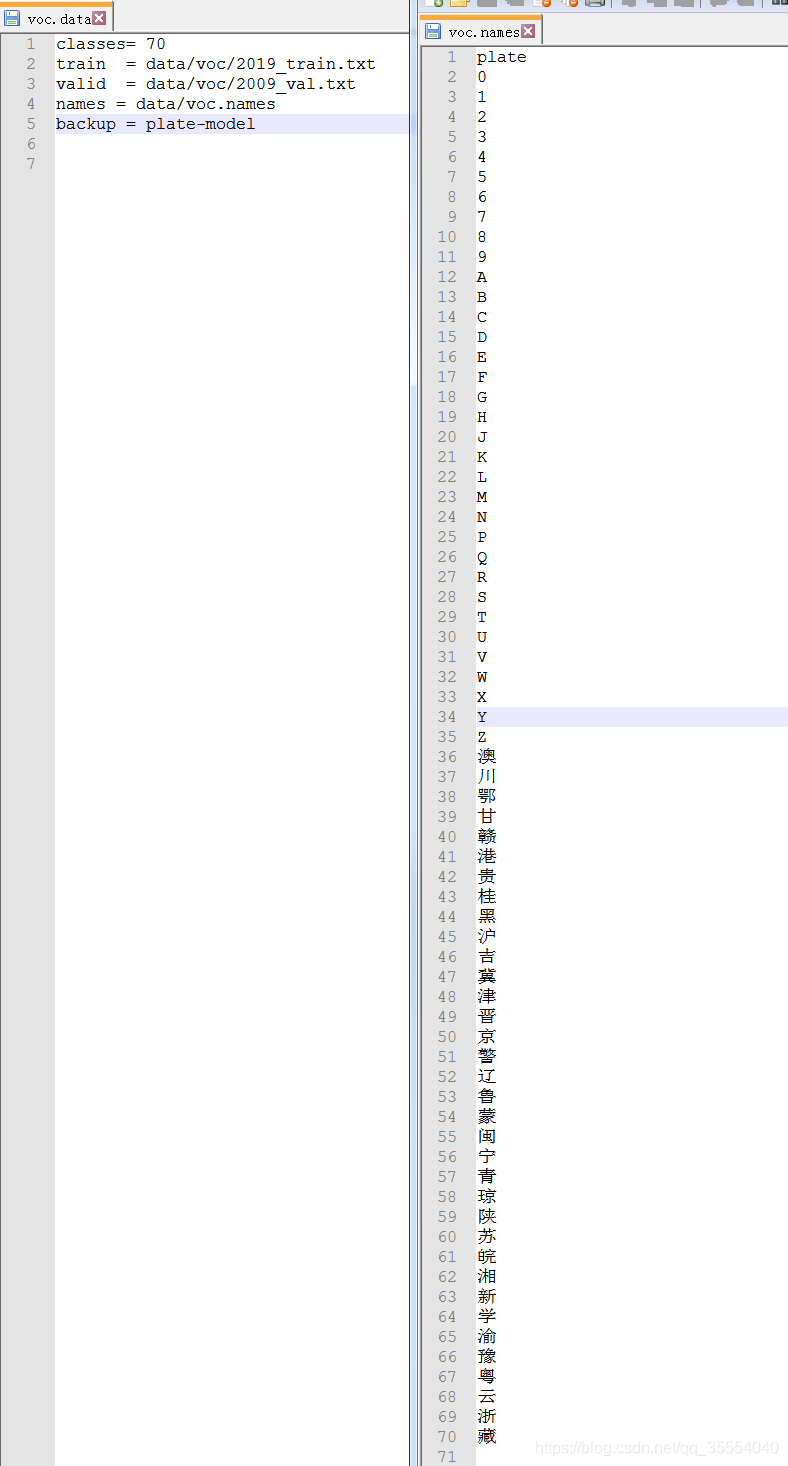
9. 我这里是将darknet.exe和cfg, 及对应动态库放到data同级目录下, 修改cfg/yolov3-tiny.cfg
[net]
batch=64
subdivisions=4 // 这里根据自己内存大小修改(我11G显存设置2时,中途会out of memory. 所以设置4, 训练时显存占用约6G)
angle=5 // 增加旋转角度产生样本
max_batches = 220000 //最大迭代次数
steps=70000,200000 //调整学习率变化点
...
filters=225 //[yolo]前一个filters=(classes类别数+ coords坐标数 +1) * mask个数
[yolo]
anchors = 12,27, 17,45, 23,61, 37,58, 198,140, 344,319
classes=70
ignore_thresh = .7
...10. 在darknet.exe目录下, 执行
darknet.exe detector train data/voc.data cfg/yolov3-tiny.cfg
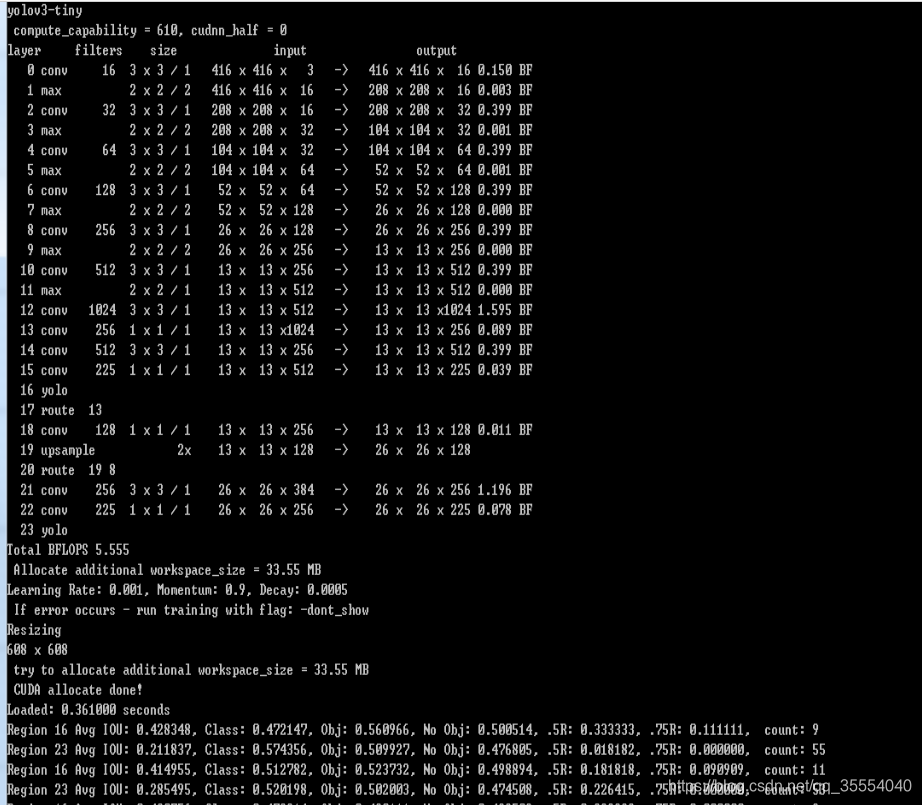
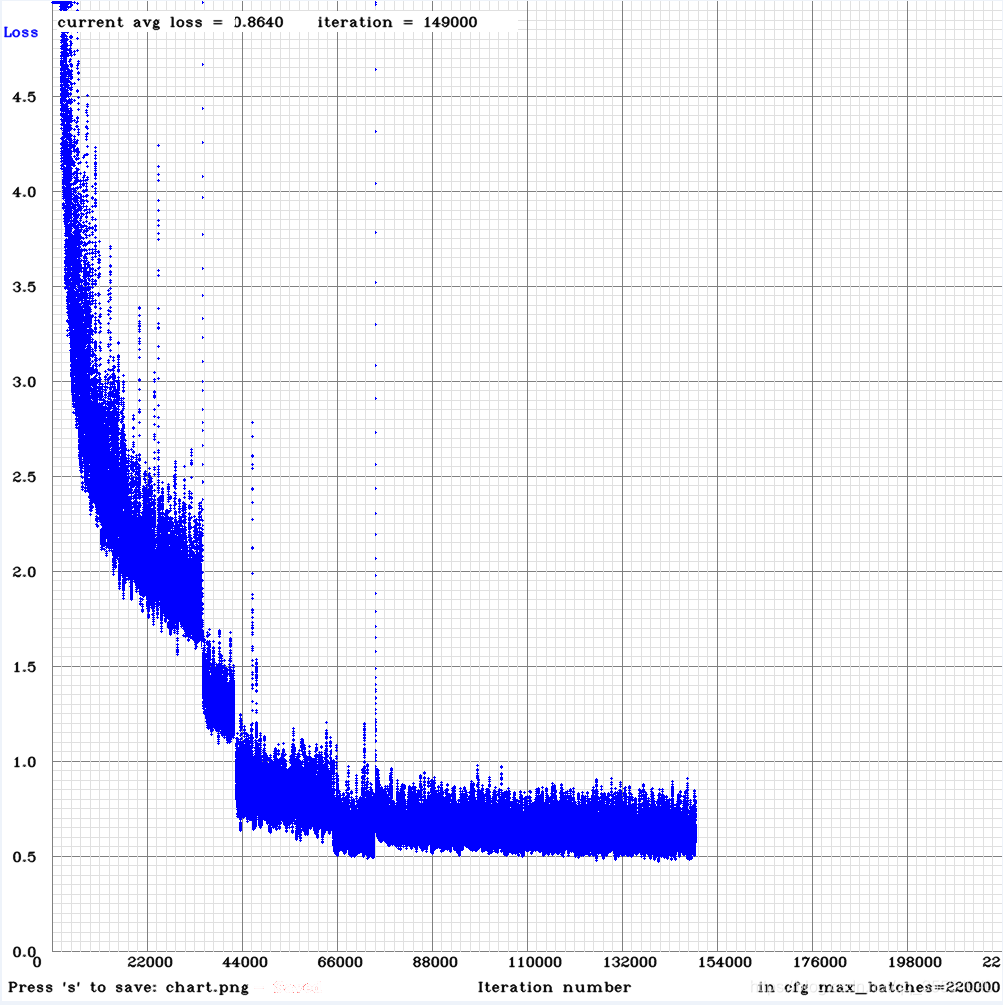
11. 最终使用模型测试了73张. 识别正确70张, 识别率约95.89%.















 531
531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









