






序列模型
RNN
当前节点的隐藏状态 与 当前输入 和 上一节点的隐藏状态有关。
当前节点的输出 是 隐藏状态 的转换。
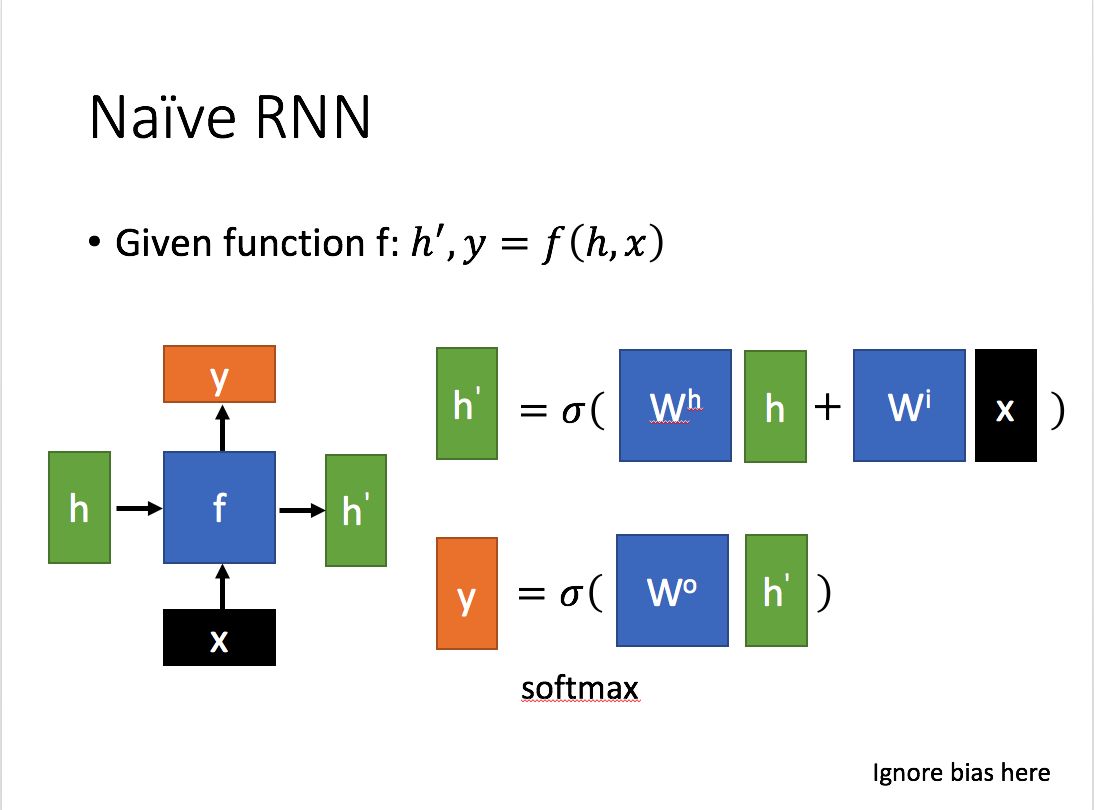
总结:
存在梯度消失问题。
LSTM
通过门控状态来控制传输状态,处理序列数据,解决长期依赖和反向传播中的梯度问题。
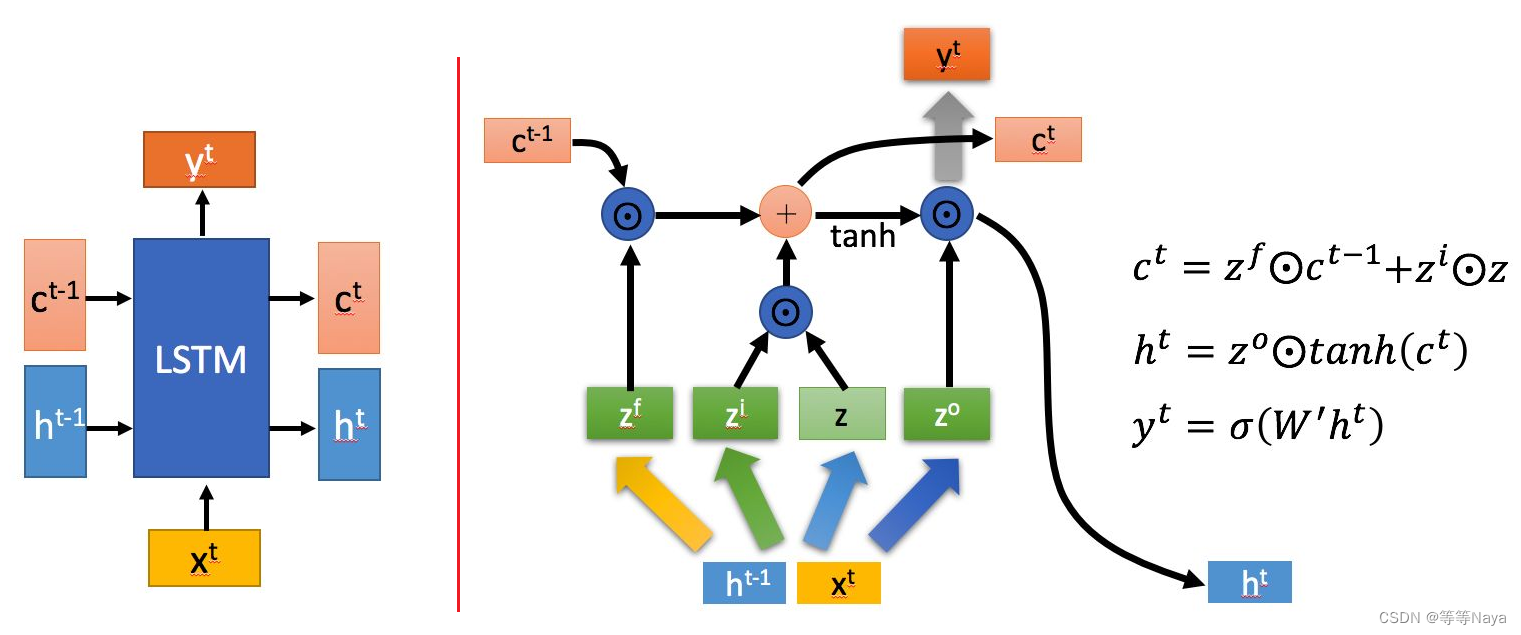
LSTM输入输出结构:
通过上一个节点的隐藏状态 和当前节点的输入
拼接训练得到四个状态。
其中, ,
,
是由拼接向量乘以权重矩阵之后,再通过一个 sigmoid 激活函数转换成0到1之间的数值,来作为一种门控状态。而
则是将结果通过一个 激活函数将转换成-1到1之间的值。
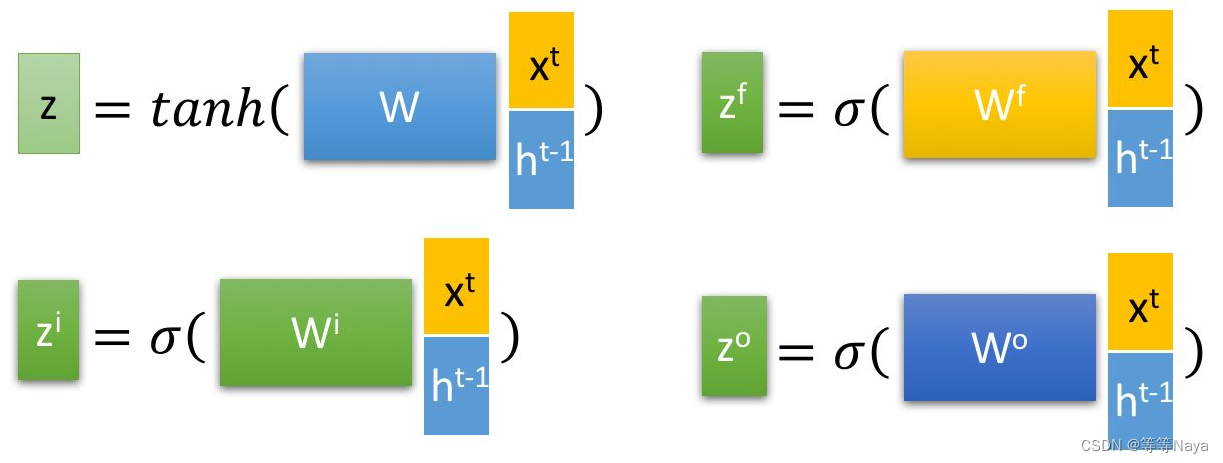
LSTM内部结构:
① 遗忘阶段。对上一个节点传进来的细胞单元 进行选择性遗忘。通过计算得到的
(f表示forget)作为遗忘门控。
② 选择记忆阶段。对当前输入 有选择性地进行“记忆”。通过计算得到的
(i表示input)作为选择记忆门控。
将上面两步得到的结果相加,即可得到传输给下一个状态的
。
③ 输出阶段。当前隐藏状态的输出。通过计算得到的 (o表示output)作为输出门控,还对上一阶段得到的
进行了放缩 (tanh函数)。
当前节点的输出 由 隐藏状态
变化得到。
总结:
参数变多,也使得训练难度加大了很多
GRU
处理序列数据,解决长期依赖和反向传播中的梯度问题。

GRU输入输出结构:
输入输出结构与普通的RNN是一样的。
输入为 当前的输入 和上一个节点的隐藏状态
,输出为当前隐藏节点的输出
和传递给下一个节点的隐藏状态
。
GRU内部结构:
①通过上一个节点的隐藏状态 和当前节点的输入
拼接 获取两个门控状态。
r 重置门(reset gate),z 更新门(update gate)。
② 选择记忆阶段:首先使用重置门控来得到“重置”之后的数据 ,再将
与输入
进行拼接,再通过一个tanh 激活函数来将数据放缩到-1~1的范围内。
③ 更新记忆阶段:使用同一个门控 z 同时进行遗忘和选择记忆,忘记传递下来的 中的某些维度信息,并加入当前节点输入的某些维度信息。
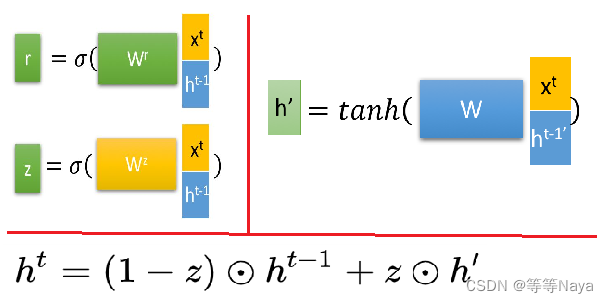
总结:
①GRU输入输出的结构与普通的RNN相似,其中的内部思想与LSTM相似。
②与LSTM相比,GRU内部少了一个”门控“,参数比LSTM少,但是却也能够达到与LSTM相当的功能。
Transformer
Bert















 838
838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









