







1. 下列哪一项属于特征学习算法(representation learning algorithm)?
A K近邻算法
B 随机森林
C 神经网络
D 都不属于
正确答案是:C, 您的选择是:C
解析:神经网络会将数据转化为更适合解决目标问题的形式,我们把这种过程叫做特征学习。
2. 下列哪些项所描述的相关技术是错误的?
A AdaGrad使用的是一阶差分(first order differentiation)
B L-BFGS使用的是二阶差分(second order differentiation)
C AdaGrad使用的是二阶差分
正确答案是:C, 您的选择是:C
解析:AdaGrad是梯度下降法,用的是一阶导数信息,L-BFGS是拟牛顿法,用到了二阶导数信息
3. 提升卷积核(convolutional kernel)的大小会显著提升卷积神经网络的性能,这种说法是
A 正确的
B 错误的
正确答案是:B, 您的选择是:B
解析:卷积核的大小是一个超参数(hyper-parameter),也就意味着改变它既有可能提高亦有可能降低模型的表现。
超参数本身就代表了不确定性,所以调参调参,效果可能会好,也有可能会差。
4. 假设我们有一个使用ReLU激活函数(ReLU activation function)的神经网络,假如我们把ReLU激活替换为线性激活,那么这个神经网络能够模拟出同或函数(XNOR function)吗?
A 可以
B 不好说
C 不一定
D 不能
正确答案是:D, 您的选择是:D
解析:使用ReLU激活函数的神经网络是能够模拟出同或函数的。 但如果ReLU激活函数被线性函数所替代之后,神经网络将失去模拟非线性函数的能力。
5. 假设我们有一个5层的神经网络,这个神经网络在使用一个4GB显存显卡时需要花费3个小时来完成训练。而在测试过程中,单个数据需要花费2秒的时间。 如果我们现在把架构变换一下,当评分是0.2和0.3时,分别在第2层和第4层添加Dropout,那么新架构的测试所用时间会变为多少?
A 少于2s
B 大于2s
C 仍是2s
D 说不准
正确答案是:C, 您的选择是:C
解析:在架构中添加Dropout这一改动仅会影响训练过程,而并不影响测试过程。
在训练阶段,改动
dropout意味着神经元减少,所以训练时间会降低,而在测试阶段,model.eval()则会dropout将会失效。
6. 下列的哪种方法可以用来降低深度学习模型的过拟合问题? 1 增加更多的数据 2 使用数据扩增技术(data augmentation) 3 使用归纳性更好的架构 4 正规化数据 5 降低架构的复杂度
A 1 4 5
B 1 2 3
C 1 3 4 5
D 所有项目都有用
正确答案是:D, 您的选择是:D
解析:上面所有的技术都会对降低过拟合有所帮助。
- 增加更多的数据:更多的数据代表了更多的不确定性,模型可以更难去拟合,所以可以降低过拟合程度
- 使用数据扩增技术: 数据增强和第一条的意思一样,通过增强数据集的数量,给数据带来多样性,增加模型的拟合难度,同样可以实现降低过拟合程度
- 使用归纳性更好的架构:越好的框架其实特征提取能力越强,越有可能出现过拟合的情况,所以这里这条我们并不能确定
- 正规化数据:就是在
Dataloader中将数据归一化(高斯分布),以此让数据处于同一分布,还有其他正则化的方法
- BN: BN是将网络中流动的特征图进行归一化(让特征图的数据几次都重置到最佳状态)
- Dropout:Dropout是将线性分类层的神经元部分失活,将模型的分类部分从原本的多神经映射变为了少量神经元映射,模型的复杂度降低,即模型的特征提取能力降低(表示能力降低),让模型变得简单了,所以也可以减少过拟合的程度
- 降低架构的复杂度:模型的复杂度降低,即模型的特征提取能力降低(表示能力降低),让模型变得简单了,所以也可以减少过拟合的程度
7. 假设有一个如下定义的神经网络,如果我们去掉ReLU层,这个神经网络仍能够处理非线性函数,这种说法是:
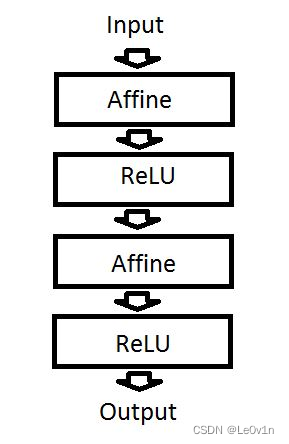
A 正确的
B 错误的
正确答案是:B, 您的选择是:A
解析:Affine是神经网络中的一个全连接层,仿射(Affine)的意思是前面一层中的每一个神经元都连接到当前层中的每一个神经元。即当前层的每一个神经元输入均为增广权值向量和前一层神经元向量的内积 ,本质是一个线性变换。而ReLU是一个常用的非线性激活函数,其表达为
max
(
0
,
x
)
\max(0,x)
max(0,x),如果去掉ReLU层,该神经网络将失去非线性表达能力,即无法拟合复杂世界中的非线性函数规律,故答案选B。
affine 美
[əˈfaɪn]
adj. 亲合的;仿射的;拟似的;远交的; n. 姻亲;
8. 请阅读以下情景: 情景1:你拥有一份阿卡迪亚市(Arcadia city)地图的数据,数据中包含市内和郊区的航拍图片。你的任务是将城市划分为工业区、农场以及山川河流等自然区域等等。 情景2:你拥有一份阿卡迪亚市(Arcadia city)地图的数据,数据中包含详细的公路网和各个地标之间的距离,而这些都是以图表的形式呈现的。你的任务是找出任意两个地标之间的最短距离。
深度学习可以在情景1中应用但无法应用在情景2中,这种说法是:
A 正确的
B 错误的
正确答案是:B, 您的选择是:B
解析:情景1基于欧几里得数据(Euclidean data)而情景2基于图形数据,这两种类型的数据深度学习均可处理。
9. 下列哪些项目是在图像识别任务中使用的数据扩增技术(data augmentation technique)?
- 水平翻转(Horizontal flipping)
- 随机裁剪(Random cropping)
- 随机放缩(Random scaling)
- 颜色抖动(Color jittering)
- 随机平移(Random translation)
- 随机剪切(Random shearing)
A 1,3,5,6
B 1,2,4
C 2,3,4,5,6
D 所有项目
正确答案是:D, 您的选择是:D
解析:
- 翻转flip:将图片水平或垂直翻转。
- 旋转rotate:旋转后图像维度可能不会被保留:
- 如果是正方形图像,旋转90度后图像的尺寸会被保存
- 如果图像是长方形,旋转180度后图像的尺寸也会被保存
- 但用更小的角度旋转图像将会改变最终图像的尺寸,所以不会被保留(看具体代码)。
- 缩放re-scale:图像可以被放大或缩小。
- 放大时大多数图像处理框架会按原始尺寸对放大后的图像进行裁剪
- 缩小时由于图像尺寸比原来的尺寸小,不得不对图像边界之外的内容做出假设。
- 裁剪crop:随机从原始图像中采样一部分,然后将这部分图像调整为原始图像大小。
注意裁剪和缩放的区别。 - 平移pad:将图像沿X或Y轴或同时沿2个方向移动,这一数据增强方法非常有用,因为大多数对象有可能分布在图像的任意位置,这迫使CNN网络需要看到所有的地方。
- 插值interpolation:当旋转、平移或者缩小一个没有纯色背景的图片,且又需要保持原始图片的大小时,需要对边界之外没有任何信息的区域做出假设。
- 最简单的假设是令边界外的部分每一个像素点的值都是常数0(RGB值=0为黑色),这样在对图像进行变换后,在图像没有覆盖的地方会得到一块黑色的区域。
- 大多数情况下最简单假设的效果不好,可以采用以下方式填充未知的空间:
- 常量填充:适用于在单色背景下拍摄的图像
- 边缘填充:用图像边缘的值填充边界以外,适用于轻微平移的图像
- 反射填充:图像像素值沿图像边界进行反射,适用于包含连续或自然背景的图像
- 对称填充:类似反射,除了在反射边界上进行边缘像素copy
Note: 通常反射和对称可以交替使用,但在处理非常小的图像时,差异将是可见的 - 包裹模式:在边界以外重复填充图像,相当于平铺图像,这种方法不像其他方法那样普遍被使用,因为它对很多场景都没有意义
- 还可以自定义方法处理未知区域(如近大远小等),但通常以上方法对大多数分类问题都有很好的效果
10. 当构建一个神经网络进行图片的语义分割时,通常采用下面哪种顺序?
A 先用卷积神经网络处理输入,再用反卷积神经网络得到输出
B 先用反卷积神经网络处理输入,再用卷积神经网络得到输出
C 不能确定
正确答案是:A, 您的选择是:A
解析:一般的语义分割架构可以被认为是一个编码器-解码器网络。编码器通常是一个预训练的分类网络,像 VGG、ResNet,然后是一个解码器网络。这些架构不同的地方主要在于解码器网络。
解码器的任务是将编码器学习到的可判别特征(较低分辨率)从语义上投影到像素空间(较高分辨率),以获得密集分类。不同于分类任务中网络的最终结果(对图像分类的概率)是唯一重要的事,语义分割不仅需要在像素级有判别能力,还需要有能将编码器在不同阶段学到的可判别特征投影到像素空间的机制。不同的架构采用不同的机制(跳跃连接、金字塔池化等)作为解码机制的一部分。
11. Sigmoid是神经网络中最常用到的一种激活函数,除非当梯度太大导致激活函数被弥散,这叫作神经元饱和。这就是为什么ReLU会被提出来,因为ReLU可以使得梯度在正向时输出值与原始值一样。这是否意味着在神经网络中ReLU单元永远不会饱和?
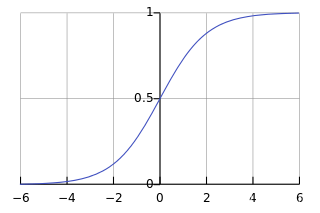
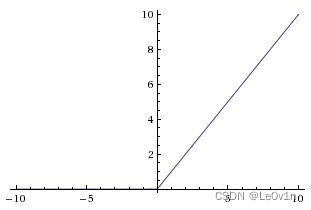
A 正确的
B 错误的
正确答案是:B, 您的选择是:B
解析:ReLU也可能会造成饱和,当输出为负的时候。
输出为负对应着梯度消失或者梯度弥散;饱和是对应着梯度爆炸
12. Dropout率和正则化有什么关系? 提示:我们定义Dropout率为保留一个神经元为激活状态的概率
A Dropout率越高,正则化程度越低
B Dropout率越高,正则化程度越高
正确答案是:A, 您的选择是:B
解析:高dropout率意味着更多神经元是激活的,所以这亦为之正则化更少。
解析是错的,
Dropout(p=),p越高,失活的神经元越高,网络越简单!
13. 普通反向传播算法和随时间的反向传播算法(BPTT)有什么技术上的不同?
A 与普通反向传播不同的是,BPTT会在每个时间步长内减去所有对应权重的梯度
B 与普通反向传播不同的是,BPTT会在每个时间步长内叠加所有对应权重的梯度
正确答案是:B, 您的选择是:B
解析:与普通反向传播不同的是,BPTT会在每个时间步长内叠加所有对应权重的梯度。
BPTT是一种基于时间的反向传播算法,主要在LSTM和RNN等网络中有广泛的应用,与普通反向传播不同的是,BPTT会在每个时间步长内叠加所有对应权重的梯度















 821
821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









