










文章目录
CPU 多级缓存 & 缓存一致性协议(MESI)
CPU 多级缓存
缓存一致性协议(MESI)
- 多级缓存的出现解决了CPU处理速度和内存读取速度不一致的问题,但是同时也带来缓存不一致的问题,为了解决这个问题,我们引入了缓存一致性协议,常见的缓存一致性协议有MSI,MESI,MOSI,Synapse,Firefly及DragonProtocol等等,下文以MESI协议进行讲述。
缓存行(Cache line)
- 缓存行是指在缓存中的最小数据单元。
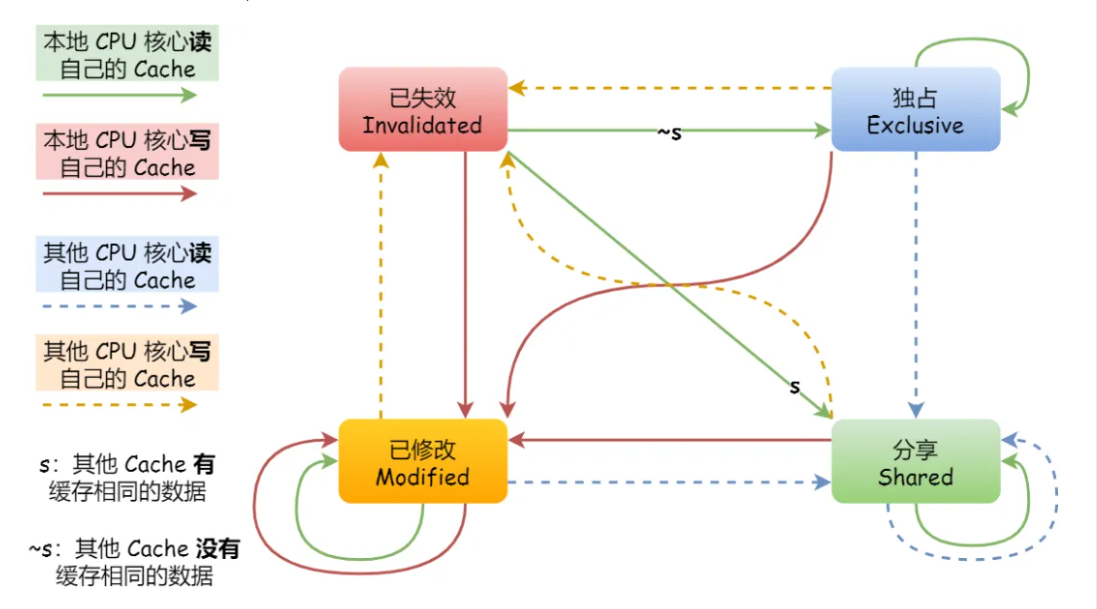
四种缓存状态
- 缓存行有4个状态,用2个bit表示。
| 状态 | 描述 | 监听任务 |
|---|---|---|
| E 独享 | 该Cache line有效,数据被修改,和内存数据一致,数据只存在本Cahe中 | 必须监听所有试图读该缓存行的操作,操作必须在该缓存行写回主存并将状态变为S后执行 |
| M 修改 | 该Cache line有效,数据被修改,和内存数据不一致,数据只存在本Cahe中 | 必须监听所有试图读该缓存行的操作,操作必须在该缓存行写回主存并将状态变为S后执行 |
| S 共享 | 该Cache line有效,数据和内存数据一致,数据存在多个Cache中 | 必须监听其它缓存使该缓存无效或独享该缓存的请求,并将该缓存行变为无效 |
| I 失效 | 该Cache line无效 | 无 |
- 注:对于M和E状态而言总是精确的,他们在和该缓存行的真正状态是一致的,而S状态可能是非一致的。如果一个处于S状态的缓存失效,另外一个缓存行可能已经独享了该缓存行,但是不会升迁为独享状态,因为失效并不会广播给其它缓存行。
缓存行状态转换
多核协同示例
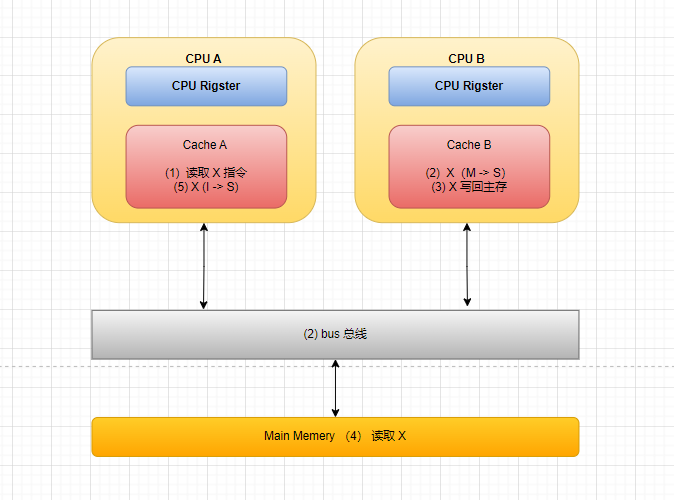
- 初始状态:CPUB 存在缓存变量 X 状态为 M
- CPUA 发出指令读取 X 指令,通过 bus 读取 X,检测到地址冲突,将 CPUB 缓存变量状态置为 S,读取 X 到 CPUA 完成
- 此时,CPUB 修改缓存变量并通过 bus 写回主存,发现地址冲突,将 CPUA 中的变量从 S 状态置为 I,数据写回主存
网站体验
- 模拟一致性的整个过程:https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESIHelp.htm
MESI优化和引入的问题
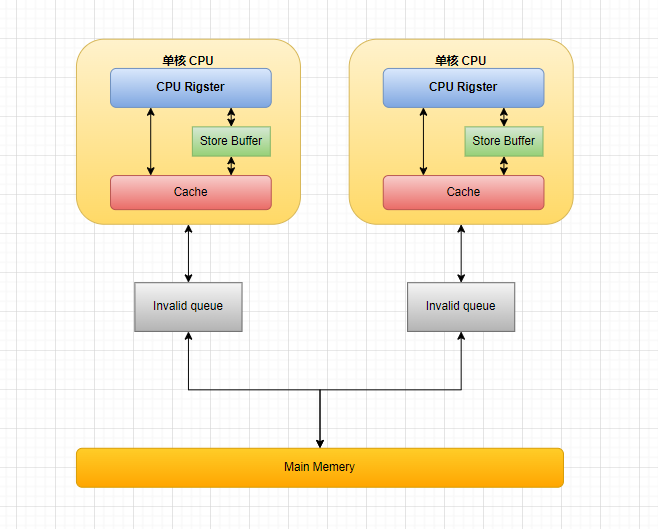
- 在上述多核CPU为保证缓存一致性进行协同的过程中,消息传递的时间远远大于CPU执行时间,如果每次的操作都需要等待协同指令响应完成,那么就会大大降低处理器的处理性能,因此引入了Store Bufferes和Invalidate Queue进行优化。
Store Bufferes & Invalidate Queue
- 从上述的多核协同案例中我们可以发现,每次修改缓存中的元素,都需要将无效状态指令(Invalidate Acknowledge)执行完才能将修改的数据写回缓存行中,等待协同指令会造成CPU运算能力浪费,因此,Store Bufferes被引入,我们不需要等待协同指令返回就可以将修改的数据写入Store Bufferes,当再次读取时若在Store Bufferes中已存在直接从Buffer中读取(称为“Store Forwarding”),只有当收到所有协同指令响应后才能写回缓存行中。
- Store Bufferes 是有限的,因此当要写回缓存行时为了更快的得到所有Invalidate Acknowledge指令的响应,实际上也不会立即执行,而是放入了Invalidate Queue中,并立即返回响应,在合适的时机去执行。
Store Bufferes & Invalidate Queue 带来的问题
- Store buffer 什么时候写回并没有保证
value = 3;
void exeToCPUA(){
value = 10;
isFinsh = true;
}
void exeToCPUB(){
if(isFinsh){
// value 一定等于10?
// 如果 Store Bufferes 没有写回那么将导致数据不一致
assert value == 10;
}
}
- Invalidate Acknowledge 什么时候执行没有保证
// 当一个CPU尝试读取实际已经失效但未执行 Invalidate Acknowledge 的数据时,会导致数据不一致
硬件内存模型
- 由于 Store Bufferes & Invalidate Queue 的引入,导致 Store Bufferes 写入缓存行和执行 Invalidate Acknowledge 的时机需要十分合适才能尽可能释放CPU的处理能力,实际上CPU并不知道什么时候会执行,因此将这个任务留给了写程序的人,这就是我们常说的内存屏障。
读屏障 & 写屏障
-
写屏障 Store Memory Barrier(a.k.a. ST, SMB, smp_wmb)是一条告诉处理器在执行这之后的指令之前,应用所有已经在Store buffer中的保存的指令到缓存行中。
-
读屏障Load Memory Barrier (a.k.a. LD, RMB, smp_rmb)是一条告诉处理器在执行任何的加载前,应用所有已经在失效队列中的失效操作的指令。
void executedOnCpu0() {
value = 10;
// 在更新数据之前必须将所有存储缓存(store buffer)中的指令执行完毕。
storeMemoryBarrier();
finished = true;
}
void executedOnCpu1() {
while(!finished);
// 在读取之前将所有失效队列中关于该数据的指令执行完毕。
loadMemoryBarrier();
assert value == 10;
}
思考 & 联系
- 不同的系统架构有不同的内存屏障,以X86架构为例:读屏障:lfence、写屏障:sfence、读写屏障:mfence。
- MESI 缓存一致性协议中为了尽可能的提高性能,引入了 Store Bufferes & Invalidate Queue ,将数据具体的失效时机和写入时间交给了内存屏障控制,而 JMM 则基于内存屏障保证数据的可见性。
- volatile 关键字底层使用了LOCK关键字,LOCK关键字的本质是锁(总线锁或缓存行锁),只是LOCK关键字的一部分能力具备和内存屏障相同的作用,但是和内存屏障还是有一定区别。


















 1188
1188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











