






摘要
This week I learned an article about introducing the attention mechanism to process long sentences。In the article, the authors introduced the attention mechanism to expand the encoder-decoder model。 It does not attempt to encode the entire input sequence into a fixed-length vector, instead it encodes the input sequence into a vector, largely improving the model’s ability to process long sentences。
一篇关于引入注意力机制处理长句子的文章被我学习了。在文章中,作者引入了注意力机制拓展了encoder-decoder模型,它不试图将整个输入序列编码成一个定长的向量,相反,它将输入序列编码成向量,在大程度上提高了模型处理长句子的能力。
文献阅读
本周阅读了《neural machine translation by jointly learning to align and translate》
作者:Dzmitry Bahdanau KyungHyun Cho Yoshua Bengio
摘要
神经机器翻译是最近提出的一种新的机器翻译方法,神经机器翻译的目标是建立一个单个的神经网络,可以共同调整,以最大限度地提高翻译性能。最近提出的神经翻译通常属于编码器-解码器(encoder-decoder)和解码器将一个目标序列编码为固定长度的向量,解码器从这些向量中生成译文。在本文中,作者推测定长向量的使用是一个提高基本的编码器-解码器框架性能的瓶颈,并提出了允许模型(软)搜索原句中与预测目标词相关的部分,不必将这些部分显示分割。通过这种新的方法,可以达到与现有的最先进的基于短语的英法翻译系统相当的翻译效果。此外,定性实验发现模型的(软)对齐方式和我们的直觉是一致的
研究背景
神经机器翻译的目标是建立并训练一个可以读取一个句子并输出正确的翻译的单一的、大型的的神经网络。很多提出的神经机器翻译都属于encoder-decoder,每种语言有一个编码器和解码器,或者是将某个特定语言的编码器应用在某个句子上,并比较它们的输出。一个解码神经网络读取和编码一个原序列为一个定长的向量。解码器输出编码向量的翻译。整个encoder-decoder系统,是由一个语言对的编码器和解码器组成的,它可以被整合训练来提高给定源句被正确翻译的概率。这种encoder-decoder方法有一个潜在的问题是,神经网络需要将源句所有的必要信息压缩成定长的向量。这可能使神经网络难以处理长句子,尤其是那些比训练语料库中更长的句子。随着输入句子长度的增加,基本的encoder-decoder的性能会迅速下降为了解决这一问题,我们引入了一种对encoder-decoder模型的拓展。每当生成的模型在翻译中生成一个单词的时候,它会(软)搜索源句中最相关信息集中的位置。然后,该模型根据与源句位置相关的上下文向量和之前产生的所有目标词来预测目标词。
对齐和翻译
作者提出了一种新的神经机器翻译架构,如下图所示。新的架构由一个作为编码器的双向RNN和一个解码器组成,解码器在译码翻译期间模拟对源句的搜索。
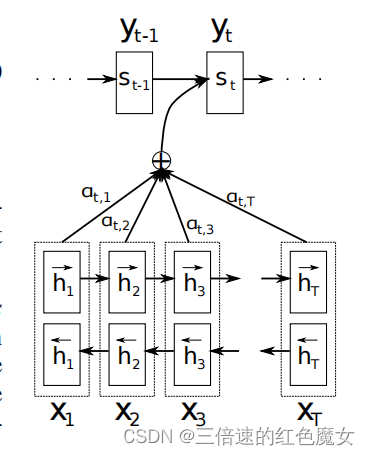
解码器
在新的模型体系结构中,我们定义了每个条件概率:

si是时间i的RNN隐藏状态

这里的概率是有一个对每个目标词 yi 不同的上下文向量 ci 决定的。
上下文向量ci依赖于编码器将输入句子映射到的注释序列(h1、hTx)。每个注释hi都包含关于整个输入序列的信息,重点关注输入序列的第i个字周围的部分。
直观地说,这在解码器中实现了一种注意机制。解码器决定源句中要注意的部分。通过让解码器具有注意机制,作者减轻了编码器必须将源句中的所有信息编码为固定长度向量的负担。通过这种新方法,信息可以遍布整个注释序列,解码器可以选择性地检索。
编码器
在作者提出的方案中,希望每个单词注释不仅要总结之前单词,还能总结之后的单词。因此,采用双向的RNN(biRNN)。
一个BiRNN由正向和向后的RNN组成。正向RNN−→f按顺序读取输入序列(从x1到xTx),并计算一个正向隐藏状态序列(−→h1,···,−→hTx)。向后的RNN←−f以相反的顺序读取序列(从xTx到x1),从而产生一个向后的隐藏状态序列(←−h1,···,←−h Tx)。
实验结果
从下表得知,RNNsearch均比RNNencdec的效果要好。其中,RNNsearch是加入了本文中所提模型的RNN Encoder-Decoder,RNNencdec是未加入的,证实了该模型相对于基本编解码器的优势

研究贡献
(1)对encoder-decoder模型进行拓展。它不试图将整个输入序列编码成一个定长的向量。相反,它将输入序列编码成向量,然后当解码翻译的时候自适应地选择向量的子集。这使得神经翻译模型避免把源句的所有信息,不管它的长度,压扁成一个定长的向量。
(2)引入attention机制处理长句子。每当生成的模型在翻译中生成一个单词的时候,它会(软)搜索源句中最相关信息集中的位置。然后,该模型根据与源句位置相关的上下文向量和之前产生的所有目标词来预测目标词。
总结
本周主要阅读了论文,下周开始学习注意力机制。















 1518
1518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









