






第19次周报
摘要
This week I read two review about the natural language processing .In the first article,The authors propose adapter modules, an efficient way of parameter updating parameters, comparable to finetune full model parameters by training only a small number of parameters.In another article, The author designed a super-large pre-training model T5, and then mainly worked to transform the NLP task into a unified text-to-text format framework, which have shown enormous potential in unifying most existing NLP tasks
本周我读了两篇关于自然语言处理的综述,在第一篇文章中,作者提出了adapter modules,一种高效的参数更新方式,只训练少量参数的情况下达到与微调全部参数的效果相似。在另一篇文章中,作者设计了一个超大预训练模型T5,然后主要工作是把NLP任务转换成文本到文本格式的统一框架,该框架在统一大多数现有NLP任务方面表现出了巨大的潜力。
文献阅读
《Parameter-Efficient Transfer Learning for NLP》
作者:Neil Houlsby 、Andrei Giurgiu 1* 、Stanisław Jastrze¸bski * 、Bruna Morrone 、Quentin de Laroussilhe 、Andrea Gesmundo 、 Mona Attariyan 、Sylvain Gelly ;
摘要
对大型预训练模型进行微调是自然语言处理中一种有效的传递机制。然而,在存在许多下游任务的情况下,微调是参数效率较低的:每个任务都需要一个全新的模型。作为一种替代方案,我们建议使用适配器模块(adapter modules)进行传输。适配器模块产生一个紧凑和可扩展的模型;针对每个任务只添加一些可训练参数,并且可以添加新的任务而无需重新访问以前的任务。原网络的参数保持不变,产生了高度的参数共享(复用性强)。为了证明适配器的有效性,我们将最近提出的BERT Transformer模型转移到26个不同的文本分类任务中,包括GLUE基准测试。适配器(Adapters)达到接近最先进的性能,同时每个任务只添加几个参数。在GLUE上,作者获得了完全微调性能的0.4%以内,每个任务只添加3.6%的参数。相比之下,微调训练每个任务的100%的参数。
finetune是一种低效的参数更新方式,对于每一个下游任务,都需要去更新语言模型的全部参数,这需要庞大的训练资源。进而,人们会尝试固定语言预训练模型大部分网络的参数,针对下游任务只更新一部分语言模型参数。大部分情况下都是只更新模型最后几层的参数,但是语言模型的不同位置的网络聚焦于不同的特征,针对具体任务中只更新高层网络参数的方式在不少情形遭遇到精度的急剧下降,作者提出了adapter modules,只需要对每个任务添加一些可训练的参数,在实现新任务的同时,更新好的参数也可以在以前的任务上实现好的性能,且参数共享性高
一、研究背景
从预先训练的模型转移可在许多NLP任务上产生强大的性能(Dai & Le,2015;Howard & Ruder,2018;Radford等人,2018)。BERT是一个在无监督损失的大型文本语料库上训练的Transformer网络,在文本分类和提取问题回答方面取得了最先进的性能(Devlin et al.,2018)。
在本文中,作者实现了一种 online 设置,其中任务以 stream(流)的形式到达。我们的目标是建立一个在所有系统上都表现良好的系统,但不需要为每一个新任务训练一个全新的模型。任务之间的高度共享对于云服务等应用程序特别有用,在这些应用程序中,需要对模型进行训练,以解决从客户那里依次到达的许多任务。为此,作者提出了一种迁移学习策略,它可以产生紧凑和可扩展的下游模型。紧凑模型是那些在每个任务使用的少量附加参数来解决多个任务的模型。可扩展的模型可以通过逐步训练来解决新的任务,而不会忘记以前的任务。我们的方法可以在不牺牲性能的情况下产生这样的模型。
自然语言处理中最常见的两种迁移学习技术是基于特征的迁移和微调。相反,作者提出了一种基于adapter modules的替代迁移方法(Rebuffi等人,2017)。基于特征的迁移涉及到预训练的实值嵌入向量。这些嵌入可能是单词(Mikolov等人,2013年)、句子(Cer等人,2019年)或段落级别(Le & Mikolov,2014年)。然后,将embedding的数据输入到自定义的下游模型中。微调包括从预先训练好的网络中复制权重,并在下游任务上对它们进行调整。最近的研究表明,微调通常比基于特征的传输具有更好的性能(Howard & Ruder,2018)。
基于特性的传输和微调都需要针对每个任务更新一组新的权重。如果网络的底层在任务之间共享,那么微调的参数效率就会更高。然而,我们提出的适配器调优方法的参数效率更高。
作者提出了基于adapter的方法,它可以产生出紧凑的和可扩展的模型
紧凑的模型:为每个任务附加少量参数来实现多个任务的模型
可扩展的模型:通过逐步训练解决新的任务且不会忘记以前的任务的模型
基于adapter可替换迁移学习,迁移学习最常见的两种技术:
基于特征:将embedding提供给自定义的下游模型
微调:从预先训练好的网络中复制权重,并在下游任务上对它们进行调整
微调通常比基于特征好,不过adapter方法的训练参数比微调少了两个数量级就实现了最佳性能.
基于adapter的调参不需要访问同时所有任务,实现新任务的同时也不会忘记以前的任务
二、Adapter tuning for NLP(针对NLP的adapter调优)
作者提出了一个在大型文本模型的几个下游任务上调优的策略。作者的策略有三个关键属性: (i)它获得了良好的性能(ii)它允许按顺序对任务进行训练,也就是说,它不需要同时访问所有数据集,并且(iii)它只为每个任务添加了少量的额外参数。这些属性在云服务的上下文中特别有用,在云服务中,许多模型需要对一系列下游任务进行训练,因此高度的共享是可取的。
为了实现这些特性,作者提出了一个新的瓶颈适配器模块。使用适配器模块进行调优需要向模型添加少量新参数,这些参数在下游任务上进行训练(Rebuffi等人,2017)。当对深度网络进行普通的微调时,会对网络的顶层进行修改。这是必需的,因为上游和下游任务的标签空间和损耗不同。适配器模块执行更一般的架构修改,以重新将预先训练好的网络用于下游任务。特别是,适配器调优策略涉及到向原始网络中注入新的层。原始网络的权值是不变的,而新的适配器层是随机初始化的。在标准的微调中,新的顶层和原始的权重是共同训练的。相比之下,在适配器调优中,原始网络的参数被冻结,因此可能被许多任务共享。
适配器模块有两个主要特性:少量的参数和一个接近恒等的初始化。与原始网络的图层相比,适配器模块需要较小。这意味着当添加更多的任务时,总模型大小增长相对较慢。对于适应模型的稳定训练,需要近恒等初始化;通过将适配器初始化为一个近恒等的函数,原始网络在训练开始时不受影响。在训练期间,适配器可能会被激活,以改变整个网络中激活的分布。如果不需要,适配器模块也可能被忽略;作者观察到一些适配器对网络的影响比其他的更大。我们还观察到,如果初始化偏离恒等函数太远,模型可能无法训练。
Adapter提供了一个非常高效的技巧,那就是在微调的时候,不改变已有的参数,而是新加一些参数,调整这部分参数从而达到微调的效果。
适配器模块有两个主要功能:参数数量较少 和 near-identity 的初始化。
与原始网络的层相比,适配器模块很小。 这意味着当添加更多任务时,总模型大小增长相对缓慢。
Adapter模型的稳定训练需要 near-identity 的初始化
2.1.对Transformer网络的实例化
基于适配器的调优为文本Transformer实例化。这些模型在许多NLP任务中获得了最先进的性能,包括翻译、提取QA和文本分类问题(Vaswani等,2017年;Radford等,2018年;Devlin等,2018年)。作者考虑了Vaswani等人(2017)中提出的标准Transforme架构。
适配器模块提供了许多体系结构上的选择。作者提供了一个简单的设计,以获得良好的性能。作者实验了一些更复杂的设计,但发现以下策略在许多数据集上执行得和我们测试的任何其他策略一样好。
下图显示了作者的适配器架构,及其对Transforme的应用。Transforme的每一层都包含两个主要的子层:一个注意层和一个前馈层。两个层后面都有一个投影,该投影将特征大小映射回层输入的大小。在每个子层上都应用了一个跳跃式连接(残差链接)。每个子层的输出被输入到子层的归一化中。作者在每个子层之后插入两个串行适配器。适配器总是直接应用到子层的输出上,在投影回到输入大小之后,但在添加跳过连接回来之前。然后,将适配器的输出直接传递到下面的图层规范化中。

为了限制参数的数量,我们提出了一个瓶颈架构。适配器首先将原始的d维特征投影到一个更小的维度m中,应用一个非线性,然后投影回d维。每层添加的参数总数,包括偏差,为2md + d + m。通过设置md,我们限制了每个任务添加的参数的数量;在实践中,我们使用了原始模型的8%的约0.5−的参数。瓶颈维度m提供了一种简单的方法来权衡性能和参数效率。适配器模块本身在内部有一个残差连接。通过残差连接,如果投影层的参数被初始化为接近于零,则该模块被初始化为一个近似的恒等函数。
除了适配器模块中的层外,我们还训练每个任务的新的归一化层参数。该技术类似于条件批归一化(De Vries等人,2017)、FiLM(Perez等人,2018)和自调制(Chen等人,2019),也产生了网络的参数后效适应;每层只有2d参数。然而,仅训练归一化层参数并不足以获得良好的性能,见第3.4节。【所以真实情况下,一般新增的模型参数都只占语言模型全部参数量的0.5%~8%。同时要注意到,针对下游任务训练需要更新的参数除了adapter引入的模型参数外,还有adapter层后面紧随着的layer normalization层参数需要更新,每个layer normalization层只有均值跟方差需要更新,所以需要更新的参数是2d。(由于插入了具体任务的adapter模块,所以输入的均值跟方差发生了变化,就需要重新训练)
适配器在 transformer 网路中的应用,具体来讲就是在 transformer 的两个子组件 attention 和前馈网络后加入 adapter,在针对某个下游任务微调时,改变的仅仅是 adapter 的参数。
适配器内部残差连接的作用:即便投影层(adapter)的参数被初始化为接近于0,通过残差连接,该模块被初始化为一个恒等映射(和transformer前面输入的值一样),从而保证训练的有效性。
三、Experiments
总结,适配器的平均GLUE得分为80.0,而通过完全微调则为80.4。最佳适配器的大小不同。例如,对于MNLI选择256,而对于最小的数据集,选择RTE,8。限制在64尺寸,导致平均精度小幅下降到79.6。为了解决表1中的所有数据集,微调需要9×的BERT参数总数。4相比之下,适配器只需要1.3个×参数。(只训练少量参数的adapter方法的效果可以媲美finetune语言模型全部参数的传统做法)

为了进一步探究adapter的参数效率跟模型性能的关系,论文做了进一步的实验,同时比对了finetune的方式(只更新最后几层的参数或者只更新layer normalization的参数),从下图的结果可以看出adapter是一种更加高效的参数更新方式,同时效果也非常可观,通过引入0.5%~5%的模型参数可以达到不落后先进模型1%的性能。

3.1Analysis and Discussion
首先,我们观察到移除任何单个层的适配器对性能只有很小的影响。热图的对角线上的元素显示了从单个层中删除适配器的性能,其中最大的性能下降是2%。相比之下,当所有适配器从网络中移除时,性能大幅下降:MNLI的性能达到37%,通过预测大多数类获得的CoLA分数达到69%。这表明,虽然每个适配器对整个网络的影响很小,但总体影响很大。
其次,下图表明,下层上的适配器比高层上的影响更小。从MNLI上的0−4层中删除适配器几乎不会影响性能。这表明适配器表现良好,因为它们会自动确定更高的层的优先级。事实上,专注于上层是一种流行的微调策略(Howard & Ruder,2018)。一种直觉是,较低的层提取在任务之间共享的底层特征,而较高的层则构建不同任务所特有的特征。这与我们的观察有关,即对于某些任务,只有顶层的微调优于完全微调。

接下来,我们研究了适配器模块对神经元数量和初始化规模的鲁棒性。在我们的主要实验中,适配器模块中的权值从一个标准差为10−2的零均值高斯分布中提取,并被截断为两个标准差。为了分析初始化量表对性能的影响,我们测试了区间内的标准偏差[10−7,1]。图6总结了这些结果。我们观察到,在两个数据集上,适配器的性能在10−2以下的标准差下都是稳健的。然而,当初始化太大时,在 CoLA上性能会下降。
为了研究适配器对神经元数量的鲁棒性,我们重新检查了第3.2节中的实验数据。我们发现,跨适配器大小的模型质量是稳定的,并且在所有任务中使用固定的适配器大小,但对性能的损害很小。对于每个适配器的大小,我们通过选择最优的学习率和epoch数来计算8个分类任务的平均验证精度6。对于尺寸为8、64和256的适配器,平均验证精度分别为86.2%、85.8%和85.7%。图4和图5进一步证实了这一消息,它们显示了几个数量级的稳定性能。
最后,我们尝试了对适配器架构的一些扩展,但并没有显著提高性能。为了保证它们的完整性,我们在这里记录了它们。我们尝试了(i)在适配器中添加一个批处理/层的归一化,(ii)增加每个适配器的层数,(iii)不同的激活函数,如tanh,(iv)只在注意层内插入适配器,(v)向主层并行添加适配器,并可能采用乘法交互。在所有情况下,我们都观察到所产生的性能与第2.1节中提出的瓶颈相似。因此,由于其简单性和强大的性能,我们推荐原始的适配器体系结构
删单个适配器影响小,删全部影响大,删高层单个适配器影响比删低层单个适配器影响大,初始化值不能太大,神经元数量在8,64,256上,原始adapter好
四、研究贡献
Adapter tuning的思想:就是在已有的transformer模型中,插⼊一个额外的组件(adapter), 然后在训练时,freeze原有参数,只对adapter进⾏更新,这样就大幅减少了在不同下游任务训练时所产生的花销。
(1) 提出了一种高效的参数更新方式,不改变已有的参数,在引入少量参数,只训练少量参数的情况下达到媲美finetune全模型参数的效果
(2)只训练少量参数也意味着对训练数据量更低的要求以及更快的训练速度,是一种将大规模预训练语言模型能力迁移到下游任务的高效方案,
《Exploring the Limits of Transfer Learning with a UnifiedText-to-Text Transformer》
作者:Colin Raffel∗、Noam Shazeer∗ 、Adam Roberts∗、Katherine Lee∗ 、Sharan Narang 、Michael Matena 、Yanqi Zhou 、Wei Li、Peter J. Liu
这篇论文的第三章开始对几种 Transformer>变体架构进行了分析与实验,作为综述的价值十分巨大,所以下文只详细介绍该论文的第三章而不是论文整体。
三、Experiments
NLP 迁移学习的最新进展来自新的预训练目标、模型架构和未标记的数据集等。我们在本节中对这些技术进行了实验研究,希望弄清它们的贡献和重要性。对于更广泛的文献综述,参见 Ruder 等人 NAACL2019 的Tutorial (笔记及资源整理)。
实验采用一个合理的基线模型每次通过调整某一方面并固定其他的方式来研究该方面的影响,这样的 coordinate descent 方法可能会忽视 second-order effects 二阶效应(例如在当前设置下的某种预训练目标效果不好,但在其他设置下很好,但由于如上实验方法,无法发现),但出于组合探索极其昂贵代价,会在未来的工作中探索。
本文的目标是在保持尽可能多的因素不变的情况下,采用多种不同的方法比较各种任务的效果。为了实现此目标,在某些情况下我们没有完全复制现有方法而是测试本质上相似的方法。
3.1 Architectures
介绍了现有的不同模型架构,并对无监督预训练的降噪目标和传统语言建模目标进行实验比较
3.1.1 Model structures(模型结构)
Attention masks:不同体系结构的主要区别因素是模型中不同注意力机制所使用的“掩码”。Transformer 中的自注意操作将一个序列作为输入,并输出相同长度的新序列。通过计算输入序列的加权平均值来生成输出序列的每个条目

图3 是代表不同的注意力掩码矩阵。自我注意机制的输入和输出分别表示为x和y。第 i 行和第 j 列中的黑色单元表示在输出时间步骤 i 允许自我注意机制参与输入元素 j。白色单元格表示不允许自我注意机制参与相应的 i 和 j 组合。
左:完全可见的掩码。输出的每个时间步会注意全部输入
中:因果掩码。防止第 i 个输出元素依赖于“未来”的任何输入元素
右:带前缀的因果掩码。使自我注意机制可以在输入序列的一部分上使用完全可见的掩码。

图4:Transformer体系结构变体的示意图。方框代表序列的元素,线条代表注意力的可见度。不同颜色的块组指示不同的 Transformer 层块。深灰色线对应于完全可见的掩码,浅灰色线对应于因果的掩码。我们使用“·”表示表示预测结束的特殊序列结束标记。输入和输出序列分别表示为 x 和 y。
左:标准的编码器-解码器体系结构,在 encoder 和encoder-decoder 注意力中使用完全可见的掩码,在decoder中使用因果掩码。
中:语言模型由一个单独的 Transformer 层块组成,并通过使用因果掩码实现输入和目标的串联。
右:在语言模型中添加前缀并对这部分输入使用完全可见的掩码。
Encoder-decoder:图 4 左侧展示了编码器-解码器结构,编码器使用“完全可见”的注意掩码。这种掩码适用于注意力“前缀”,即提供给模型的某些上下文,供以后进行预测时使用。BERT也使用了完全可见掩码,并在输入中附加了特殊的“分类”标记。然后,在与分类令牌相对应的时间步中,BERT的输出将用于对输入序列进行分类的预测。
Language model:Transformer 中的decoder用于自回归生成输出序列,即在每个输出时间步,都会从模型的预测分布中选取令牌,然后将选取的令牌再输入到模型中为下一个输出时间步做出预测。这样,可以将 Transformer 解码器用作语言模型,即仅训练用于下一步预测的模型。此架构的示意图如图 4 中间所示。实际上,针对NLP的迁移学习的早期工作使用这种架构并将语言建模目标作为一种预训练方法。
语言模型通常用于压缩或序列生成。但是,它们也可以简单地通过连接输入和目标而用于 text-to-text 框架中。例如,考虑英语到德语的翻译:如果我们有一个训练数据的输入句子为“ That good.”,目标为“Das ist gut.”,那么我们只需在连接的输入序列“translate English to German: That is good. Target: Das ist gut.” 上对模型进行语言模型训练(错位预测)即可。如果我们想获得此示例的模型预测,则向模型输入前缀“translate English to German: That is good. Target: ”,模型自回归生成序列的其余部分。通过这种方式,该模型可以预测给定输入的输出序列,从而满足 text-to-text 任务。这种方法最近被用来表明语言模型可以学会在无监督的情况下执行一些 text-to-text 的任务。
Prefix LM:在 text-to-text 设置中使用语言模型的一个基本且经常被提到的缺点是,因果掩码会迫使模型对输入序列的第 i 个输入的表示仅取决于直到 i 为止的输入部分(没考虑下文)。在该框架中,在要求模型进行预测之前,为模型提供了前缀/上下文(例如,前缀为英语句子,并且要求模型预测德语翻译)。使用完全因果掩码,前缀状态的表示只能取决于前缀的先前条目。因此,在预测输出的条目时,模型使用的前缀表示是不需要受到限制的,但却由于语言模型而使其前缀表示受到了限制。在序列到序列模型中使用单向递归神经网络编码器也存在类似问题。
只需更改掩码模式,就可以在基于Transformer的语言模型中避免此问题。在序列的前缀部分使用完全可见的掩码。图 3 和 4 的右边分别显示了此掩码模式和前缀LM的示意图。
在上述英语到德语的翻译示例中,将完全可见的掩码应用于前缀“translate English to German: That is good. Target: ”,而因果掩码将在训练期间用于预测目标“Das ist gut.”。在 Text-to-text 框架中使用 prefix LM 最初是由 Generating Wikipedia by Summarizing Long Sequences [10]提出的。最近有工作[11]展示了这种架构对多种 Text-to-text 任务均有效。
我们注意到,当遵循我们的 Text-to-text 框架时,prefix LM体系结构非常类似于分类任务的BERT。以 MNLI 基准为例,前提是“I hate pigeons.”,假设是“My feelings towards pigeons are filled with animosity.”,而正确的标签是“entailment”。为了将此示例输入语言模型,我们将其转换为序列“mnli premise: I hate pigeons. hypothesis: My feelings towards pigeons are filled with animosity. target: entailment”。在这种情况下,完全可见的前缀将对应于整个输入序列,直到单词“target:”,这可以看作类似于BERT中使用的“分类”令牌。因此,我们的模型将对整个输入具有完全的可见性,然后将通过输出单词“entailment”来进行分类。对于给定任务前缀(在这种情况下为“mnli”)的模型,该模型很容易学习输出有效的类标签。这样,prefix LM 和 BERT 架构之间的主要区别在于, 分类器简单地集成到 prefix LM 中的 Transformer 解码器的输出层中 。
第一种,Encoder-Decoder 型,即 Seq2Seq 常用模型,分成 Encoder 和 Decoder 两部分,对于 Encoder 部分,输入可以看到全体,之后结果输给 Decoder,而 Decoder 因为输出方式只能看到之前的。此架构代表是 MASS(今年WMT的胜者),而 BERT 可以看作是其中 Encoder 部分。
第二种, 相当于上面的 Decoder 部分,当前时间步只能看到之前时间步信息。典型代表是 GPT2 还有最近 CTRL 这样的。
第三种,Prefix LM(Language Model) 型,可看作是上面 Encoder 和 Decoder 的融合体,一部分如 Encoder 一样能看到全体信息,一部分如 Decoder 一样只能看到过去信息。最近开源的 UniLM 便是此结构
3.1.2 Comparing different model structures(比较不同模型结构)
为了实验上比较这些体系结构变体,我们希望每个模型在某种意义上都是等效的:如果两个模型具有相同数量的参数,或者它们需要大致相同的计算量来处理给定的(输入序列,目标序列)对,则可以说是等效的。但不可能同时根据这两个标准将编码器-解码器模型与语言模型体系结构(包含单个Transformer块)进行比较。由于在编码器中具有L层且在解码器中具有L层的编码器-解码器模型具有与具有2L层的语言模型大约相同数量的参数。但是,相同的L + L编解码器模型将具有与仅具有 L 层的语言模型大约相同的计算成本,这是因为语言模型中的L层必须同时应用于输入和输出序列,而编码器仅应用于输入序列,而解码器仅应用于输出序列。所以存在参数量不同,但计算量几乎相同的情况。这些等价是近似的——由于对编码器的注意力,解码器中存在一些额外的参数,并且在注意力层中,序列长度为平方的计算量也很大。然而,实际上,我们观察到L层语言模型与L + L层编码器-解码器模型几乎相同的步长时间,这表明计算成本大致相当。
为了提供合理的比较方法,我们考虑了编码器-解码器模型的多种配置。我们将 BERTBASE大小的层块中的层数和参数分别称为 L 和 P 。
我们将使用 M 来指代L + L层编码器-解码器模型或仅L层的解码器模型处理给定输入目标对所需的FLOP数量。
总的来说,我们将进行比较:
1.在编码器中具有 L 层,在解码器中具有 L 层的编码器-解码器模型。该模型具有 2P 个参数和M FLOP的计算成本。
2.等效模型,但参数在编码器和解码器之间共享,即 P 个参数和 M FLOP计算成本。
3.在编码器和解码器中各具有 L / 2 层的编码器-解码器模型,提供 P 参数和 M/2 FLOP成本。
4.具有 L 层和 P 参数的纯解码器的语言模型,以及由此产生的M FLOP计算成本。
5.具有相同架构(因此具有相同数量的参数和计算成本),但对输入具有完全可见的自我注意力的解码器的前缀LM。
3.1.3 Objectives
考虑将基本语言建模目标以及第 3.1.4 节中描述的降噪目标作为无监督的目标。对于在进行预测之前先提取前缀的模型(编码器-解码器模型和前缀LM),我们从未标记的数据集中采样了一段文本,并选择一个随机点将其分为前缀和目标部分。对于标准语言模型,我们训练模型以预测从开始到结束的整个跨度。我们的无监督降噪目标是为 text-to-text 模型设计的;为了使其适应语言模型,我们将输入和目标连接起来,如3.2.1节所述。
3.1.4 Results
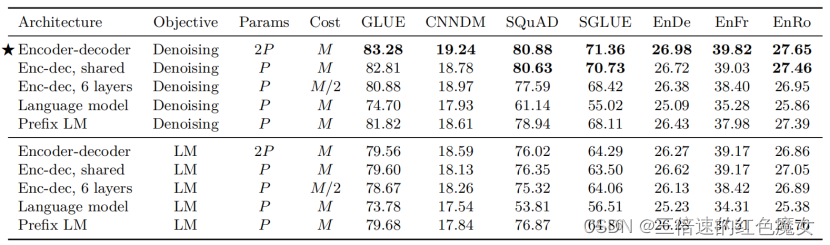
表2:我们使用P来表示12层基底变压器层堆栈中的参数数,使用M来表示使用编码解码器模型处理序列所需的流量。我们使用去噪目标(在第3.1.4节中描述)和自回归目标(通常用于训练语言模型)来评估每个架构变体
表 2 显示了我们比较的每种架构所获得的分数。对于所有任务,具有降噪目标的编码器-解码器架构表现最佳。此变体具有最高的参数计数(2P),但与仅使用P参数的解码器的模型具有相同的计算成本。令人惊讶的是,我们发现在编码器和解码器之间共享参数几乎同样有效。相反,将编码器和解码器堆栈中的层数减半会严重影响性能。ALBERT 还发现,在Transformer块之间共享参数是可以减少总参数数量而不牺牲太多性能的有效方法。XLNet 与具有降噪目标的共享编码器-解码器方法有些相似。我们还注意到,共享参数编码器-解码器的性能优于仅解码器的前缀LM,这表明增加编码器-解码器的显式注意是有益的。最后,我们确认了一个广为接受的观念,即与语言建模目标相比,使用降噪目标始终可以带来更好的下游任务性能。在以下部分中,我们将对无监督目标进行更详细的探讨。
通过实验作者们发现,在提出的这个 Text-to-Text 架构中,Encoder-Decoder 模型效果最好。于是乎,就把它定为 T5 模型,T5 模型其实就是个 Transformer 的 Encoder-Decoder 模型。
上面这些模型架构都是 Transformer 构成,之所以有这些变换,主要是对其中注意力机制的 Mask 操作。
3.2 Unsupervised objectives(预训练目标)
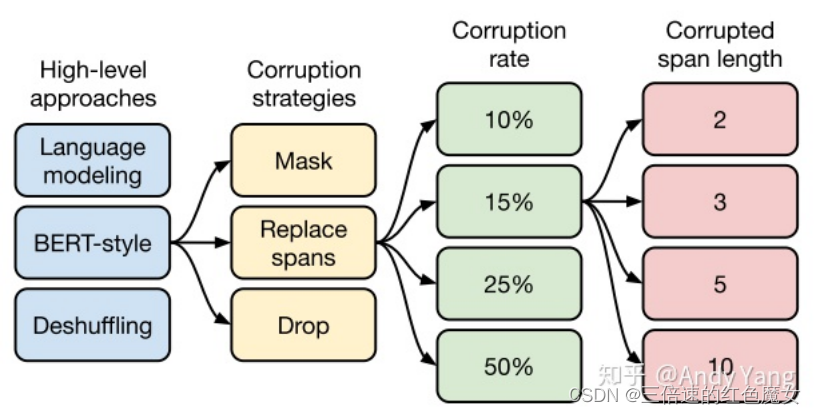
如上图所示,总共从四方面来进行比较。
第一个方面,高层次方法(自监督的预训练方法)对比,总共三种方式。
1.语言模型式,就是 GPT-2 那种方式,从左到右预测;
2.BERT-style 式,就是像 BERT 一样将一部分给破坏掉,然后还原出来;
3.Deshuffling (顺序还原)式,就是将文本打乱,然后还原出来。
其中发现 Bert-style 最好,进入下一轮。
第二方面,对文本一部分进行破坏时的策略,也分三种方法。
1.Mask 法,如现在大多模型的做法,将被破坏 token 换成特殊符如 [M];
2.replace span(小段替换)法,可以把它当作是把上面 Mask 法中相邻 [M] 都合成了一个特殊符,每一小段替换一个特殊符,提高计算效率;
3.Drop 法,没有替换操作,直接随机丢弃一些字符。
此轮获胜的是 Replace Span 法,类似做法如 SpanBERT 也证明了有效性。
进入下一轮。
第三方面,到底该对文本百分之多少进行破坏呢,挑了 4 个值,10%,15%,25%,50%,最后发现 BERT 的 15% 就很 ok了。
接着进入第四方面,因为 Replace Span 需要决定对大概多长的小段进行破坏,于是对不同长度进行探索,2,3,5,10 这四个值,最后发现 3 结果最好。
终于获得了完整的 T5 模型,还有它的训练方法。
1.Transformer Encoder-Decoder 模型;
2.BERT-style 式的破坏方法;
3.Replace Span 的破坏策略;
4.15 %的破坏比;
5.3 的破坏时小段长度。
T5使用了简化的相对位置embeding,即每个位置对应一个数值而不是向量,将相对位置的数值加在attention softmax之前的logits上,每个head的有自己的PE,所有的层共享一套PE。个人认为这种方式更好一点,直接在计算attention weight的时候加入位置信息,而且每一层都加一次,让模型对位置更加敏感。
3.3 Pre-training dataset
比较了使用不同方法过滤后的 C4 数据集以及常用的预训练数据集,并对预训练数据集(是否重复)进行试验;
3.3.1 Unlabeled datasets
除了将其与其他过滤方法和常见的预训练数据集进行比较之外,我们有兴趣测量这种过滤是否会改善下游任务的性能。为此,我们在以下数据集上进行预训练后比较基线模型的性能:
C4:作为基准,首先在我们发布的未标记数据集进行预训练。
Unfiltered C4:为了衡量我们在创建C4中使用的启发式过滤的效果,我们还生成了C4的替代版本,该版本放弃了过滤。请注意,我们仍然使用 langdetect 提取英文文本。结果,我们的“未过滤”变体仍包含一些过滤,因为 langdetect 有时会给不自然的英语文本分配低概率。
RealNews-like:使用了从新闻网站提取的文本数据。为了进行比较,我们额外过滤C4使其仅包括一个“RealNews”数据集对应的域的内容来生成另一个未标记的数据集。请注意,为便于比较,我们保留了C4中使用的启发式过滤方法。唯一的区别是,表面上我们忽略了任何非新闻内容。
WebText-like:WebText数据集仅使用提交到内容聚合网站 Reddit 且收到的“score”至少为3的网页内容。提交给Reddit的网页得分基于认可或反对网页的用户比例。使用Reddit分数作为质量信号的背后想法是,该网站的用户只会上传高质量的文本内容。为了生成可比较的数据集,我们首先尝试从C4中删除所有不是 OpenWebText[13] 列表中出现的URL。但是,由于大多数页面从未出现在Reddit上,因此内容相对较少,仅约 2 GB。为避免使用过小的数据集,因此我们从2018年8月至2019年7月从 Common Crawl 下载了12个月的数据,对 C4 和 Reddit 应用了启发式过滤,产生了一个17 GB的类似 WebText 的数据集,其大小与原始40GB的 WebText 数据集相类似。
Wikipedia:Wikipedia网站包含数以百万计的协作撰写的百科全书文章。该网站上的内容受严格的质量准则约束,因此已被用作可靠且纯净的自然文本来源。我们使用 TensorFlow Datasets[14] 的英文 Wikipedia 文本数据,其中省略了文章中的任何标记或参考部分。
Wikipedia + Toronto Books Corpus:使用来自 Wikipedia 的预训练数据的缺点是,它仅表示自然文本的一个可能域(百科全书文章)。为了缓解这种情况,BERT将来自维基百科的数据与多伦多图书公司进行了组合。TBC包含从电子书中提取的文本,它代表自然语言的不同领域。

上表显示了每个数据集预训练后获得的结果。第一个明显的收获是,C4中删除启发式过滤会降低性能,并使未过滤的变体在每个任务中表现最差。除此之外,我们发现在某些情况下,具有更受限域的预训练数据集的性能优于多样化的C4数据集。例如,使用Wikipedia + TBC语料库产生的SuperGLUE得分为73.24,超过了我们的基准得分。这几乎完全归因于MultiRC的完全匹配得分从25.78(基准C4)提高到50.93(Wikipedia + TBC)(参见表15)。MultiRC是一个阅读理解数据集,其最大数据来源来自小说书,而这恰恰是TBC覆盖的领域。类似地,使用类似RealNews 的数据集进行预训练可使 ReCoRD 的精确匹配得分从68.16提高到73.72,ReCoRD是测量新闻文章阅读理解的数据集。最后一个例子是,使用来自Wikipedia的数据在 SQuAD上获得了显着(但并没那么突出)的收益,SQuAD是一个使用来自 Wikipedia 的段落的问题解答数据集。这些发现背后的主要教训是,对域内未标记的数据进行预训练可以提高下游任务的性能。如果我们的目标是预训练可以快速适应来自任意领域的语言任务的模型,这将不足为奇,但也不令人满意。
仅在单个域上进行预训练的一个缺点是所得的数据集通常要小得多。类似地,虽然在我们的基准设置中类似WebText的变体在性能上类似或优于C4数据集,并且基于Reddit的过滤所产生的数据集比C4小约 40 倍,但它是基于Common Crawl的 12 倍以上数据而建立的。在以下部分中,我们将研究使用较小的预训练数据集是否会引起问题。
3.3.2 Pre-training dataset size
本文创建C4的方法旨在能够创建非常大的预训练数据集。对大量数据的访问使我们能够对模型进行预训练,而无需重复样本。目前尚不清楚在预训练期间重复样本是会对下游性能有所帮助还是有害,因为我们的预训练目标本身就是随机的,并且可以帮助防止模型多次看到相同的数据。
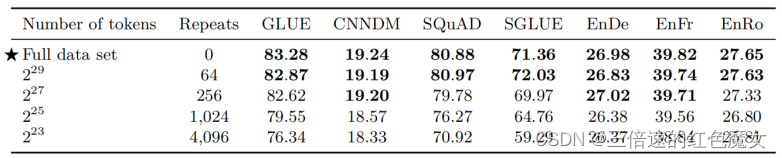
最终的下游性能如上表所示,随着数据集大小缩小而下降。我们怀疑这可能是由于该模型开始记住预训练数据集。为了测量这是否成立,我们在图6中绘制了每种数据集大小的训练损失。的确,随着预训练数据集的大小缩小,该模型获得的训练损失明显较小,这表明可能存在记忆。
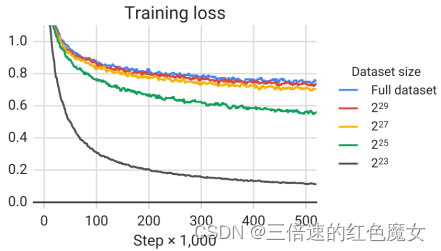
我们注意到,当预训练数据集仅重复 64 次时,这些影响是有限的。这表明一定程度的重复预训练数据可能不会有害。但是,考虑到额外的预训练可能是有益的,并且获取额外的未标记数据既便宜又容易,我们建议尽可能使用大型的预训练数据集。
1.C4中数据集删除启发式过滤会降低性能,更受限域的预训练数据集的性能优于多样化的C4数据集
2.最终的下游性能随着数据集大小缩小而下降
3.4 Training Strategy
对训练方式进行了探究,Baseline 是在无监督降噪任务上对模型的所有参数进行预训练,然后对在每个下游任务上分别对其进行了微调,并使用模型的不同参数设置(检查点)来评估性能,本节进一步的对微调方法、多任务学习方法以及两者的结合进行了实验探究;
3.4.1 Fine-tuning methods
有人认为,微调模型的所有参数可能会导致结果欠佳,尤其是在资源匮乏的情况下。文本分类任务的迁移学习的早期结果提倡仅微调小型分类器的参数。 这种方法不太适用于我们的编码器-解码器模型,因为必须训练整个解码器以输出给定任务的目标序列 。相反,我们专注于两种替代的微调方法,这些方法仅更新编码器-解码器模型的参数的子集。
第一种:“adapter layers”[15]的动机是在微调时保持大多数原始模型固定不变。适配器层是附加的dense-ReLU-dense块,这些块在变压器的每个块中的每个预先存在的前馈网络之后添加。这些新的前馈网络的设计使其输出维数与其输入相匹配。这样就可以将它们插入网络,而无需更改结构或参数。进行微调时,仅更新适配器层和层归一化参数。这种方法的主要超参数是前馈网络的内部维数 d ,它改变了添加到模型中的新参数的数量。我们用 d 的各种值进行实验。
第二种替代性微调方法是“gradual unfreezing”[6]。在逐步解冻过程中,随着时间的流逝,越来越多的模型参数会进行微调。逐步解冻最初应用于包含单个块层(a single stack of layers)的语言模型体系结构。在此设置中,微调开始时仅更新最后一层的参数,然后在训练了一定数量的更新之后,就会更新包括倒数第二层的参数,依此类推,直到整个网络的参数都在微调。为了使这种方法适应我们的编码器-解码器模型,我们从顶部开始逐渐并行地解冻编码器和解码器中的层。由于我们的输入嵌入矩阵和输出分类矩阵的参数是共享的,因此我们会在整个微调过程中对其进行更新。
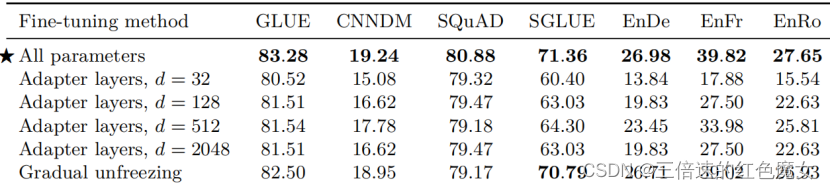
上表显示了这些微调方法的性能比较。对于适配器层,我们使用32、128、512、2048的内部尺寸 d 。根据过去的结果我们发现像 SQuAD 这样的资源较少的任务在 d 较小的情况下效果很好,而资源较高的任务则需要较大的维度才能实现合理的性能。这表明,adapter layers 可能是一种在较少参数上进行微调的有前途的技术,只要将维度适当地缩放到任务大小即可。请注意,在我们的案例中,我们通过将 GLUE 和 SuperGLUE 的各自的子数据集连接起来,将它们分别视为一个“任务”,因此,尽管它们包含一些资源较少的数据集,但组合的数据集足够大,因此需要较大的 d 值。我们发现, 尽管在微调过程中确实提供了一定的加速,但全局解冻会在所有任务中造成轻微的性能下降。通过更仔细地调整解冻时间表,可以获得更好的结果。
3.4.2 Multi-task learning
到目前为止,我们已经在单个无监督学习任务上对我们的模型进行了预训练,然后在每个下游任务上分别对其进行了微调。另一种方法称为“多任务学习”,在多个任务上同时训练模型。这种方法通常的目标是训练可以同时执行许多任务的单个模型,即该模型及其大多数参数在所有任务之间共享。我们在某种程度上放松了这一目标,而是一次研究了针对多个任务进行训练的方法,以便最终产生对每个任务都执行良好的独立参数设置。例如, 我们可能会针对多个任务训练一个模型,但是在报告性能时,我们可以为每个任务选择不同的检查点 。与目前为止我们所考虑的 pre-train-then-fine-tune 方法相比,这放松了多任务学习框架的要求并使之处于更稳定的基础上。我们还注意到,在我们统一的 Text-to-text 框架中,“多任务学习”仅对应于将数据集混合在一起。相比之下,大多数将多任务学习应用于NLP的应用都会添加特定于任务的分类网络,或者为每个任务使用不同的损失函数。
正如Arivazhagan等人指出,在多任务学习中一个非常重要的因素是模型应该在每个任务的多少数据进行训练。我们的目标是不对模型进行 under- or over-train 过少训练或过度训练——也就是说,我们希望模型从给定任务中看到足够的数据以使其能够很好地执行任务,但又不想看到太多数据以致于记住训练集。
如何准确设置每个任务的数据比例取决于各种因素,包括数据集大小,学习任务的“难度”(即模型在有效执行任务之前必须看到多少数据),正则化等。
另一个问题是潜在的“任务干扰”或“负向转移”,在一个任务上实现良好的性能会阻碍在另一任务上的性能。鉴于这些问题,我们先探索各种设置每个任务的数据比例的策略。Wang [16]等人进行了类似的探索。
Examples-proportional mixing: 模型适应给定任务的速度的主要因素是任务数据集的大小。因此,设置混合比例的自然方法是根据每个任务数据集的大小按比例进行采样。这等效于串联所有任务的数据集并从组合数据集中随机采样示例。但是请注意,我们引入了无监督降噪任务,该任务使用的数据集比其他所有任务的数量级大。因此,如果我们仅按每个数据集的大小按比例进行采样,该模型看到的绝大多数数据将是无标签的,并且所有监督任务都会缺乏训练(under-train)。即使没有无监督的任务,某些任务(例如WMT英语到法语)也很大,以至于它们同样会占据大多数批次。为了解决这个问题,我们在计算比例之前对数据集的大小设置了人为的“限制”。
Equal mixing:在这种情况下,我们以相等的概率从每个任务中抽取示例。具体来说,每个批次中的每个示例都是从我们训练的数据集中随机抽样的。这很可能是次优策略,因为该模型将在资源不足的任务上快速过拟合,而在资源过多的任务上不充分拟合。我们主要将其作为参考当比例设置不理想时可能出现的问题。
为了将这些混合策略在相同的基础上与我们的基线
pre-train-then-fine-tune结果进行比较,我们以相同的总步数训练了多任务模型:
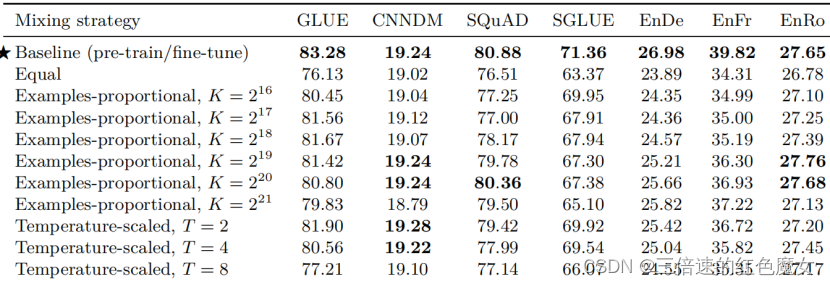
总的来说,我们发现多任务训练的效果不如预训练后对大多数任务进行微调。特别是“均等”的混合策略会导致性能急剧下降,这可能是因为低资源任务过度拟合,高资源任务没有看到足够的数据,或者模型没有看到足够的未标记数据以学习通用语言能力。对于Examples-proportional mixing的示例,我们发现对于大多数任务,K 都有一个“最佳点”,在该点上模型可以获得最佳性能,而K值较大或较小都会导致性能变差。(对于我们考虑的K值范围)WMT英语到法语的翻译是个例外,这是一项资源非常丰富的任务,它总是受益于更高的混合比例。最后,我们注意到 Temperature-scaled mixing 提供了一种从大多数任务中获得合理性能的方法,其中 T = 2 在大多数情况下表现最佳。在以下部分中,我们将探讨缩小多任务训练与 pre-train-then-fine-tune 方法之间差距的方法。
3.4.3 Combining multi-task learning with fine-tuning
回想一下,我们正在研究多任务学习的宽松版本:我们在混合任务上训练单个模型,但允许使用模型的不同参数设置(检查点)来评估性能(注意,预训练时是只有单一无监督任务的)。我们可以通过考虑以下情况来扩展此方法:模型同时针对所有任务进行预训练,然后针对有监督的单个任务进行微调。这是“MT-DNN”[17]使用的方法,该方法在推出时就达到了GLUE和其他基准的最新性能。
1.首先,模型在 Examples-proportional mixing 的人工混合数据集上预训练模型,然后在每个单独的下游任务上对其进行微调。 这有助于我们衡量在预训练期间是否将监督任务与无监督目标一起包括在内,可以使模型对下游任务有一些有益的早期暴露 。我们也希望,可能在许多监督源中进行混合可以帮助预训练的模型在适应单个任务之前获得更为通用的“技能”(宽松地说)。
2.为了直接测量这一点,我们考虑第二个变体,其中我们在相同的混合数据集上对模型进行预训练,只是从该预训练混合物中省略了一项下游任务。然后,我们在预训练中遗漏的任务上对模型进行微调。对于我们考虑的每个下游任务,我们都会重复此步骤。我们称这种方法为“leave-one-out”多任务训练。这模拟了真实的设置,在该设置中,针对未在预训练中看到的任务微调了预训练模型。
3.因此,对于第三个变体,我们对所有考虑的监督任务进行预训练。

我们在表 12 中比较了这些方法的结果。为进行比较,我们还包括基线和标准多任务学习的结果。我们发现,多任务预训练后的微调可以使性能与我们的基准相当。这表明在多任务学习之后使用微调可以帮助减轻第 3.5.2 节中描述的不同混合比率之间的某些权衡。有趣的是,“leave-one-out”训练的性能仅稍差一些,这表明针对各种任务训练的模型仍然可以适应新任务(即多任务预训练可能不会产生严重的任务干扰)。最后,除了翻译任务外,在所有情况下,有监督的多任务预训练的表现都明显较差。这可能表明翻译任务从(英语的)无监督预训练中受益较少,而无监督预训练则是其他任务中的重要因素。
多任务训练的效果不如预训练后对大多数任务进行微调。特别是“均等”的混合策略会导致性能急剧下降,这可能是因为低资源任务过度拟合,高资源任务没有看到足够的数据,或者模型没有看到足够的未标记数据以学习通用语言能力。
缩小多任务训练与 pre-train-then-fine-tune 方法之间差距的方法:多任务预训练+微调 的方式可以取得于baseline近似的结果。这表明多任务学习之后,再进行微调确实有助于缓解不同混合比例之间的一些权衡。另外,抛弃一个任务(“leave-one-out”)的训练结果仅仅轻微下降,说明模型在多个任务上训练确实可以应用于新的任务上。
四 结论
Architectures
1.原始的Transformer结构表现最好
2.encoder-decoder结构和BERT、GPT的计算量差不多
3.共享encoder和decoder的参数没有使效果差太多
Unsupervised objectives
1.自编码和自回归的效果差不多
2.作者推荐选择更短目标序列的目标函数,提高计算效率
Datasets
1.在领域内进行无监督训练可以提升一些任务的效果,但在一个小领域数据上重复训练会降低效果
Training strategies
1.精调时更新所有参数 > 更新部分参数
2.在多个任务上预训练之后精调 = 无监督预训练
Scaling
1.在小模型上训练更多数据 < 用少量步数训练更大的模型
2.从一个预训练模型上精调多个模型后集成 < 分开预训练+精调后集成
总结
下周继续总结该nlp方向的综述性论文,对论文提及的知识点再进行专门的学习。















 261
261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









