






第八次周报
摘要
This week I read the following three classic Convolutional neural network papers, and reproduced the code,The experiment appeared an overfitting phenomenon, which was found not only related to batch_size, but also related to the amount of data, and I adjusted batch_size and adopted transfer learning to solve the problem。
本周阅读了下述三篇经典卷积神经网络论文,并复现了代码。实验出现了过拟合的现象,通过研究发现不仅与batch_size有关,还跟数据的数量有关,我调整了batch_size以及采用迁移学习解决了问题。
Alexnet
论文标题:《ImageNet Classification with Deep Convolutional Neural Networks》
作者:Alex Krizhevsky、Ilya Sutskever、Geoffrey E. Hinton

摘要
作者的训练了一个大型的深度卷积神经网络,该神经网络有6000万个参数和65万个神经元,由5个卷积层组成,使用最大池化层进行下采样,以及3个全连接层,最终的分类为1000类。为了加快训练速度,作者使用了非饱和神经元和一个高效使用GPU的方法实现卷积操作。为了减少全连接层中的过拟合,作者采用了一种最近开发的正则化方法,被称为“dropout",该方法被证明是非常有效的。
研究背景
1.数据集:出现imageNet这样的大数据集,可以用来训练更复杂的模型 。
2.CNN:而CNNs的能力可以通过改变深度和广度来控制,它们还对图像的本质(即统计的平稳性和像素依赖性的局部性)做出了强有力且基本正确的假设。与具有类似大小层的标准前馈神经网络相比,CNNs具有更少的连接和参数,因此更容易训练,而其理论上最好的性能可能只会稍微差一些。
3.GPU: GPU和卷积操作结合,便于训练大型CNN网络
研究贡献:
1.relu:解决梯度消失问题
2.高度优化GPU实现2D卷积方法,网络在2块GPU并行:解决算力问题
3.maxpool:提取最重要特征
4.dropout:解决过拟合问题
代码实现
#创建模型
models = tf.keras.Sequential([
tf.keras.layers.ZeroPadding2D(((1,2),(1,2)),input_shape=(224,224,3)), #行列分别补3,输出为227x227x3
tf.keras.layers.Conv2D(filters=48,kernel_size=(11,11),strides=4,padding='valid',activation='relu'),# 输出为48x55x55
tf.keras.layers.MaxPool2D(pool_size=(3,3),strides=2),# 输出为48x27x27
tf.keras.layers.Conv2D(filters=128,kernel_size=(5,5),strides=1,padding='same',activation='relu'),# 输出为 128x27x27
tf.keras.layers.MaxPool2D(pool_size=(3,3),strides=2),# 输出为 128x13x13
tf.keras.layers.Conv2D(filters=192,kernel_size=(3,3),strides=1,padding='same',activation='relu'),# 输出为 192x13x13
tf.keras.layers.Conv2D(filters=192,kernel_size=(3,3),strides=1,padding='same',activation='relu'),# 输出为 192x13x13
tf.keras.layers.Conv2D(filters=128,kernel_size=(3,3),strides=1,padding='same',activation='relu'),# 输出为 128x13x13
tf.keras.layers.MaxPool2D(pool_size=(3,3),strides=2),# 输出为 128x6x6
tf.keras.layers.Flatten(),# 拍平为一维向量
tf.keras.layers.Dropout(0.5), # 随机掐死百分之50神经元
tf.keras.layers.Dense(2048,activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(2048,activation='relu'),
tf.keras.layers.Dense(5,activation='softmax')
])
models.summary()
模型结构:

运行结果:

VGG
论文标题:《VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION》
作者:Karen Simonyan、Andrew Zisserman
**思想:把卷积层组合成块拼接(VGG块:大量3x3卷积拼接)
摘要
作者研究了卷积网络深度对其精度的影响,使用非常小(3×3)卷积滤波器的体系结构对增加深度的网络进行了全面的评估,这表明通过将深度推到16-19个权重层,可以实现对现有技术配置的显著改进,而且可以很好地推广到其他数据集,并实现了很好的结果(泛化性高)。
作者还评估了非常深的卷积网络(多达19个权重层)的大尺度图像分类。结果表明,表示深度有利于分类精度,并且研究结果再次证实了深度在视觉表征中的重要性。
研究背景
背景:由于有大型公共图像存储库(数据)和高性能计算系统(高算力如:GPU)以及大规模分布式集群(算法),使得卷积网络最近在大规模图像和视频识别方面取得了巨大成功。
研究内容
(别人的工作:)随着convnet成为计算机视觉领域的一种商品,人们已经多次尝试改进克里日夫斯基等人(2012)的原始架构,以获得更好的准确性。例如,在ILSVRC- 2013中表现最好的使用了更小的接受窗口大小和更小的第一卷积层的步幅。(1.改算法,减少信息的丢失)另一项改进是在整个图像和多个尺度上密集地训练和测试网络(2.改数据喂到模型的技巧))。
(作者的工作)在本文中,作者讨论了关于ConvNet架构设计的另一个重要方面——深度。为此,作者固定了体系结构的其他参数,并通过添加更多的卷积层来稳步增加网络的深度,在所有层中都使用了非常小的(3×3)卷积滤波器,这被证明是可行的。
研究贡献:
作者提出了更准确的网络架构,不仅实现最先进的精度ILSVRC分类和本地化任务,但也适用于其他图像识别数据集(具有很好的泛化性),他们实现优秀的性能即使作为一个相对简单的pipeline(管线:一条龙服务)的一部分(例如深度特性分类的线性SVM没有微调)(把其他数据集喂给VGG做特征提取,得到的4096维特征向量再给SVM(支持向量机)也能有很好的分类)
Pipeline解释:(数据读取 - 数据预处理 - 创建模型(具体到模型也有相应的Pipeline,比如模型的具体构成部分:比如GCN+Attention+MLP的混合模型) - 评估模型结果 - 模型调参)
提出堆叠两个3x3小卷积核取代一个5x5卷积核,堆叠三个3x3小卷积核取代一个7x7卷积核,在相同感受野下,训练参数减少,提取特征更精细
代码实现:
因为采用的数据集小,所以用迁移学习来实现数据集在VGG16上的训练
VGG=tf.keras.applications.VGG16(include_top=False,weights='imagenet',input_shape=(224,224,3))
VGG.trainable = False # 固定卷积层
models = tf.keras.Sequential([
VGG,
# 以下是全部连接层
tf.keras.layers.Flatten(),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(1024,activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(1024,activation='relu'),
tf.keras.layers.Dense(5,activation='softmax')
])
models.summary()
模型结构

运行结果:

GoogLenet
论文题目:《Going deeper with convolutions》
作者:Christian Szegedy、Wei Liu、Yangqing Jia、Pierre Sermanet、Scott Reed、
Dragomir Anguelov、Dumitru Erhan、Vincent Vanhoucke、Andrew Rabinovich
摘要:
作者提出了一种深度卷积神经网络架构GoogLeNe,这是一个22层的深度网络,该体系结构的主要特点是提高了网络内部计算资源的利用率。它允许增加网络的深度和宽度,同时保持计算预算不变。作者证明了通过现成的密集构建块(Inception)来近似预期的最优稀疏结构是改进计算机视觉神经网络的可行方法。该方法的主要优点是,与较浅和较不宽的网络相比,在降低了算力的需求(更少的参数个数和计算复杂度)。虽然期望通过更昂贵的相似深度和宽度的网络可以实现相似的结果质量,但作者的方法证明转向稀疏架构是可行和有用的想法。这表明未来将以自动化的方式创建更稀疏和更精细的结构。
研究背景:
在过去的三年里,主要是由于卷积网络,图像识别和目标检测的质量已经取得了惊人的进步。这些进展不仅仅是更强大的硬件、更大的数据集和更大的模型的结果,还是新想法、算法和改进的网络架构的结果。另一个值得注意的因素是,随着移动计算和嵌入式计算的持续发展,算法的效率——特别是它们的能力和内存使用——变得越来越重要。值得注意的是,导致本文中提出的深层架构设计的考虑包括了这个因素,而不是完全固定在精度数字上。对于大多数的实验,模型设计保持15亿的计算预算增加推理时间,但可以把现实世界使用,即使在大型数据集,在一个合理的成本。(通过降低参数和维度来达到降低计算成本)
研究内容:
本文中,作者将重点研究一种高效的计算机视觉深度神经网络架构,在作者举的例子中,单词“deep”有两种不同的含义:首先,他们以“盗梦空间模块(一层接一层)”的形式引入了一个新的组织层次,也在更直接的意义上增加了网络深度。
研究贡献:
引入了Inception块用四条有不同超参数的卷积层和池化层通路抽取不同信息,与之前的所有模型对比:模型参数小,计算复杂度低

代码实现:
def Inception(ch1,ch3_red,ch3,ch5_red,ch5,pool_red,input_):
# 1x1卷积核数量 3x3卷积核数量,3x3路径中降维1x1卷积核数量,5x5数量,5x5降维数量,池化中1x1降维数量,输入图片尺寸
inputs1 = tf.keras.layers.Input(shape=input_.shape[1:])
x1 = tf.keras.layers.Conv2D(ch1,kernel_size=1,activation='relu')(inputs1)
x21 = tf.keras.layers.Conv2D(ch3_red,kernel_size=1,activation='relu')(inputs1)
x22 = tf.keras.layers.Conv2D(ch3,kernel_size=3,padding='same',activation='relu')(x21)
x31 = tf.keras.layers.Conv2D(ch5_red,kernel_size=1,activation='relu')(inputs1)
x32 = tf.keras.layers.Conv2D(ch5,kernel_size=5,padding='same',activation='relu')(x31)
x41 = tf.keras.layers.MaxPool2D(pool_size=3,strides=1,padding='same')(inputs1)
x42 = tf.keras.layers.Conv2D(pool_red,kernel_size=1,activation='relu')(x41)
outputs1 = tf.concat((x1,x22,x32,x42),axis=-1)# 长宽相同,在倒数第一个维度(通道数)进行拼接
return tf.keras.Model(inputs=inputs1,outputs=outputs1)
#辅助分类器
def InceptionAux(num_classes,input_): # 分类的个数,输入
inputs1 = tf.keras.layers.Input(shape=input_.shape[1:])
x = tf.keras.layers.AvgPool2D(pool_size=5,strides=3)(inputs1)
x = tf.keras.layers.Conv2D(128,kernel_size=1,activation='relu')(x)
#全连接层
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dropout(rate=0.7)(x)
x = tf.keras.layers.Dense(1024,activation='relu')(x)
x = tf.keras.layers.Dropout(rate=0.7)(x)
x = tf.keras.layers.Dense(num_classes)(x) # 在外层才实现softmax
return tf.keras.Model(inputs=inputs1,outputs=x)
def GoogLeNet():
input_image = tf.keras.layers.Input(shape=(224,224,3))
x = tf.keras.layers.Conv2D(64,kernel_size=7,strides=2,padding='same',activation='relu')(input_image)
x = tf.keras.layers.MaxPool2D(pool_size=3,strides=2,padding='same')(x)
x = tf.keras.layers.Conv2D(64,kernel_size=1,activation='relu')(x)
x = tf.keras.layers.Conv2D(192,kernel_size=3,padding='same',activation='relu')(x)
x = tf.keras.layers.MaxPool2D(pool_size=3,strides=2,padding='same')(x)
x = Inception(64,96,128,16,32,32,x)(x)
x = Inception(128,128,192,32,96,64,x)(x)
x = tf.keras.layers.MaxPool2D(pool_size=3,strides=2,padding='same')(x)
x = Inception(192,96,208,16,48,64,x)(x)
aux11 = InceptionAux(5,x)(x)
aux1 = tf.keras.layers.Softmax(name='aux_1')(aux11)
x = Inception(160,112,224,24,64,64,x)(x)
x = Inception(128,128,256,24,64,64,x)(x)
x = Inception(112,144,288,32,64,64,x)(x)
aux22 = InceptionAux(5,x)(x)
aux2 = tf.keras.layers.Softmax(name='aux_2')(aux22)
x = Inception(256,160,320,32,128,128,x)(x)
x = tf.keras.layers.MaxPool2D(pool_size=3,strides=2,padding='same')(x)
x = Inception(256,160,320,32,128,128,x)(x)
x = Inception(384,192,384,48,128,128,x)(x)
x = tf.keras.layers.MaxPool2D(pool_size=7,strides=1)(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dropout(rate=0.4)(x)
x = tf.keras.layers.Dense(5)(x)
aux3 = tf.keras.layers.Softmax(name='aux_3')(x)
# 得到了三个损失结果
model = tf.keras.models.Model(inputs=input_image,outputs=[aux1,aux2,aux3])# 用主分支加两个辅助分类器预测
#model = tf.keras.models.Model(inputs=input_image,outputs=aux3)# 也可以直接用主分支预测
return model
models = GoogLeNet()
模型结构
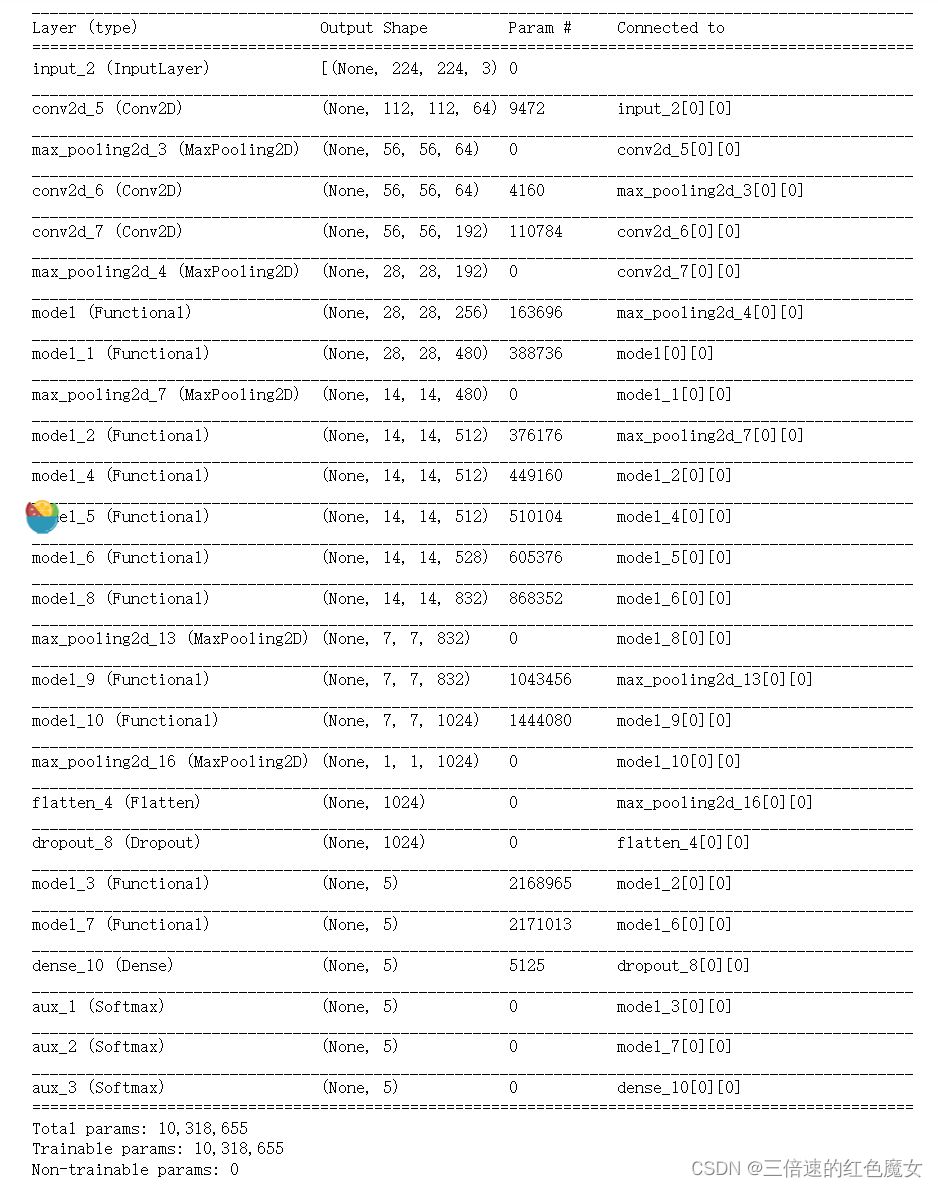
运行结果:
(GoogLenet有三个分支,这里只输出主分支的正确率,其他分支也差不多)
aux_3为主分支

总结
明早补上resnet,下周主要进行对RNN的研究















 2259
2259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









